【 TiDB 使用环境】生产环境
【 TiDB 版本】5.0.2
【描述】
最近使用批量更新工具清理一个表的数据时遇到一种异常的情况,因此发出来一下。
工具之前有介绍过: 使用tidb-toolkit批量删除/更新数据
原始SQL为:
delete from db.t where dt < '2023-06-01';
生成的批量删除SQL执行日志为:
[2023-08-23 16:57:11,381] [INFO] [tk_chunk_update.py:215]: chunk 131491 Done [split_time=0:00:00.014420] [duration=0:00:41.683770] [rows=1000] [sql=DELETE FROM db.t WHERE dt < '2023-06-01' and (`t`.`_tidb_rowid` >= 252168339 and `t`.`_tidb_rowid` < 252169339)]
[2023-08-23 16:57:11,390] [INFO] [tk_chunk_update.py:215]: chunk 131498 Done [split_time=0:00:00.013967] [duration=0:00:40.087776] [rows=1000] [sql=DELETE FROM db.t WHERE dt < '2023-06-01' and (`t`.`_tidb_rowid` >= 252175339 and `t`.`_tidb_rowid` < 252176339)]
[2023-08-23 16:57:11,391] [INFO] [tk_chunk_update.py:302]: write savepoint 252178339, complete percent: 73.18%
这里贴一下拆分出来的SQL以及表结构:
DELETE FROM db.t WHERE dt < '2023-06-01' and (t._tidb_rowid>= 252168339 andt._tidb_rowid < 252169339)
CREATE TABLE `t` (
`book_id` int(11) NOT NULL COMMENT '主键',
`dt` date NOT NULL,
`entity_id` bigint(20) NOT NULL,
`content_type` int(11) NOT NULL DEFAULT '0',
`book_name` varchar(255) DEFAULT NULL,
`inter_name` varchar(255) DEFAULT NULL,
`author` varchar(255) DEFAULT NULL,
`translator` varchar(255) DEFAULT NULL,
`contract_id` bigint(10) DEFAULT NULL,
`word_count` bigint(20) DEFAULT NULL,
`book_type` int(4) DEFAULT NULL,
`file_type` int(4) DEFAULT NULL,
`desc_brief` varchar(255) DEFAULT NULL,
`book_url` varchar(255) DEFAULT NULL,
`volume_count` bigint(10) DEFAULT NULL,
`chapter_count` bigint(10) DEFAULT NULL,
`created_time` datetime DEFAULT NULL,
`updated_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最后更新时间',
PRIMARY KEY (`dt`,`book_id`) /*T![clustered_index] NONCLUSTERED */,
UNIQUE KEY `ix_uniq_entityId` (`dt`,`entity_id`),
KEY `ix_contractId` (`contract_id`)
)
【问题为】:
最初这个SQL的执行效率还是很好的,执行计划显示直接通过TableRangeScan实现了rowid的快速扫描。
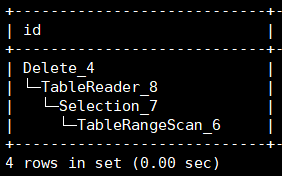
但是后来突然发现执行效率变慢了,执行计划变为了:

很迷惑的去使用了唯一索引,因此单个SQL的执行耗时从几十ms变为了40多秒。
尝试加上/*+ use_index(t) */的注释后执行计划可以恢复到最初的表范围扫描(我期望的方式)。
计划为批量更新工具添加hint,当rowid为主键时就 use_index(t,PRIMARY),为隐式的_tidb_rowid时就添加use_index(t),应该可以增强稳定性。
