【 TiDB 使用环境】生产环境
【 TiDB 版本】5.0.1
【遇到的问题:问题现象及影响】
因发现tikv 795天会panic的bug,详见https://asktug.com/t/topic/1011645,于是主动对集群的tikv节点进行重启,操作:tiup cluster restart xxxx -R tikv
从日志输出上tikv是重启成功的,如下图
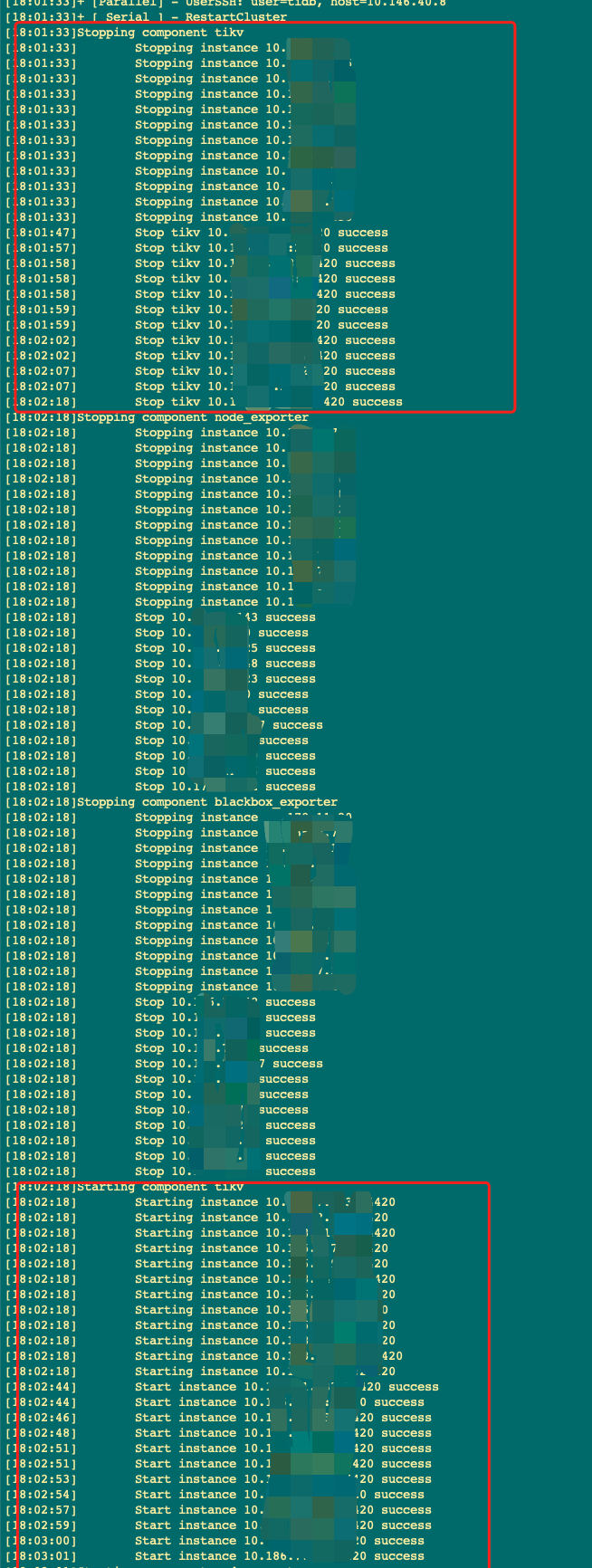
但从业务QPS,重启完成后qps下降了很多,业务反馈有超时。从监控上看集群的慢sql量增多,999耗时变大.

restart之后执行tiup cluster display xx 发现多个tikv节点的status为Disconnected,且每次执行display,处于Disconnected的tikv是不固定的。
后面通过多次tiup cluster stop xx关停整个集群,tiup cluster start xx开启集群,使得整个集群恢复正的。请问tikv重启之后tikv不正常是什么原因呢?如何进行排查
该集群特点:这个集群写入量大(1.2w写qps,1.5k读qps),数据量大(25T), tikv节点12个(物理机)
【附件:截图/日志/监控】
tikv节点的日志,有很多报错
[2023/08/22 18:03:09.380 +08:00] [ERROR] [util.rs:416] [“request failed, retry”] [err_code=KV:PD:gRPC] [err=“Grpc(RpcFailure(RpcStatus { status: 4-DEADLINE_EXCEEDED, details: Some("Deadline Exceeded") }))”]
[2023/08/22 18:03:09.380 +08:00] [ERROR] [util.rs:416] [“request failed, retry”] [err_code=KV:PD:gRPC] [err=“Grpc(RpcFailure(RpcStatus { status: 4-DEADLINE_EXCEEDED, details: Some("Deadline Exceeded") }))”]
[2023/08/22 18:03:09.380 +08:00] [ERROR] [util.rs:416] [“request failed, retry”] [err_code=KV:PD:gRPC] [err=“Grpc(RpcFailure(RpcStatus { status: 4-DEADLINE_EXCEEDED, details: Some("Deadline Exceeded") }))”]
[2023/08/22 18:03:09.380 +08:00] [ERROR] [util.rs:416] [“request failed, retry”] [err_code=KV:PD:gRPC] [err=“Grpc(RpcFailure(RpcStatus { status: 4-DEADLINE_EXCEEDED, details: Some("Deadline Exceeded") }))”]

