执行delete 操作,条件是主键,但是时间比较长,看了下执行计划主要时间耗费在prewrite 阶段,不是很理解执行计划

prewrite 阶段:主要是检测数据有没有上锁,想问下backoff 阶段呢?
执行delete 操作,条件是主键,但是时间比较长,看了下执行计划主要时间耗费在prewrite 阶段,不是很理解执行计划
你看执行计划里有提示backoff的内容没
实际你这图看着就有点问题,到底是prewrite耗时还是commit耗时啊,上面显示是prewrite耗时,但是下面的耗时又是在commit阶段的backoff耗时。。。
删了多少条数据?
是啥数据,资源使用情况如何
执行计划就是这样显示的,我也不知道到底是什么阶段的耗时
就删除一条数据,手动执行很快,但是应用反馈放在程序里面就很慢
是在哪个地方有显示?
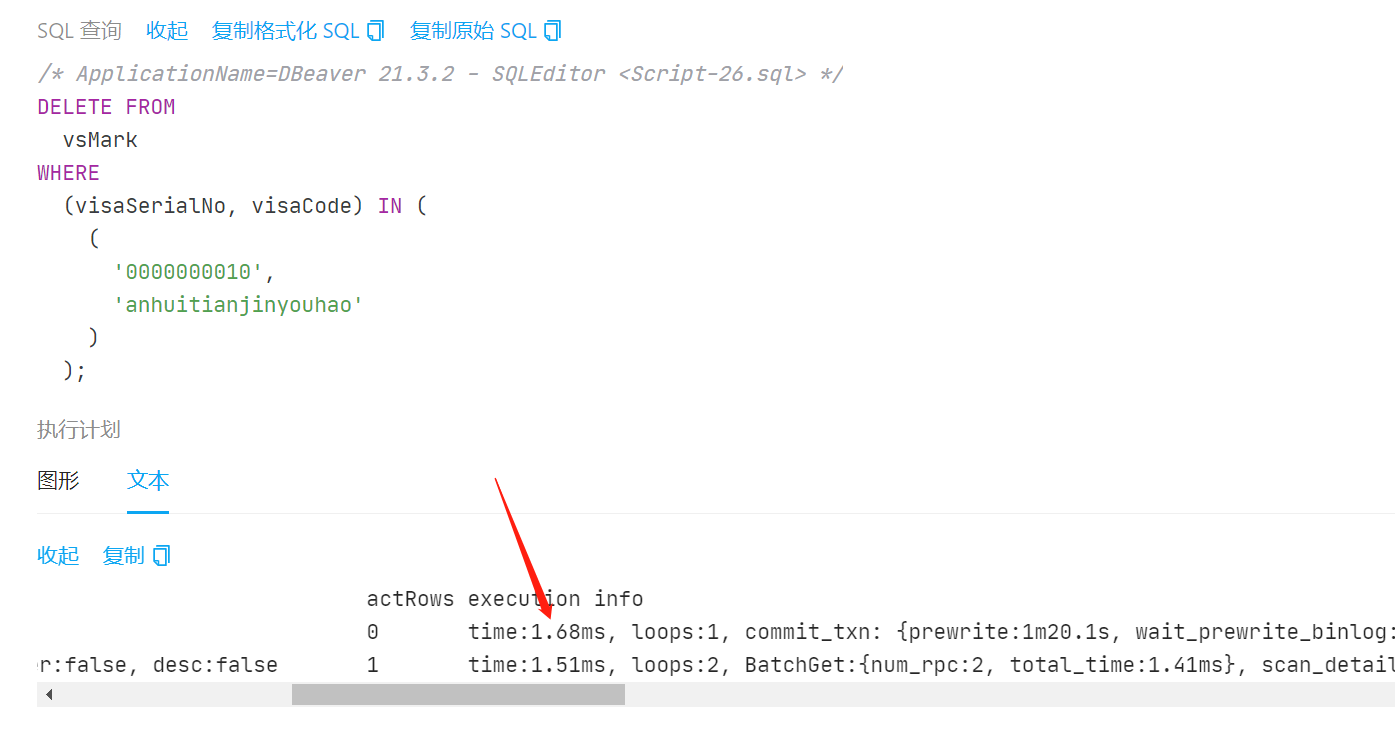
| id | task | estRows | operator info | actRows | execution info | memory | disk | |
|---|---|---|---|---|---|---|---|---|
| Delete_2 | root | 0 | N/A | 0 | time:1.68ms, loops:1, commit_txn: {prewrite:1m20.1s, wait_prewrite_binlog:800ns, backoff: {time: 1m20s, prewrite type: [txnLock]}, slowest_prewrite_rpc: {total: 0.002s, region_id: 137292, store: 9.1.65.131:20160, tikv_wall_time: 1.29ms, scan_detail: {get_snapshot_time: 301.7µs, rocksdb: {block: {cache_hit_count: 8, read_count: 1, read_byte: 10.4 KB, read_time: 182.4µs}}}, write_detail: {store_batch_wait: 5.78µs, propose_send_wait: 0s, persist_log: {total: 59.6µs, write_leader_wait: 50ns, sync_log: 29.4µs, write_memtable: 2.67µs}, commit_log: 259.4µs, apply_batch_wait: 16.7µs, apply: {total:68.2µs, mutex_lock: 0s, write_leader_wait: 0s, write_wal: 12.9µs, write_memtable: 18.9µs}}}, resolve_lock: 40ms, region_num:15, write_keys:15, write_byte:691} | 145.5 KB | N/A | |
| └─Batch_Point_Get_1 | root | 1 | table:vsMark, index:PRIMARY(visaSerialNo, visaCode), keep order:false, desc:false | 1 | time:1.51ms, loops:2, BatchGet:{num_rpc:2, total_time:1.41ms}, scan_detail: {total_process_keys: 2, total_process_keys_size: 367, total_keys: 2, get_snapshot_time: 368.5µs, rocksdb: {block: {cache_hit_count: 18}}} | N/A | N/A | |
|  |
锁的问题
好的 我看下 谢谢
好嘞 我这边让开发看看业务端能不能改下
DELETE 操作时间过长,您可以考虑以下优化策略:
prewrite 阶段的负担。DELETE 操作的性能,可能需要重新评估索引的设计。
