现象描述:
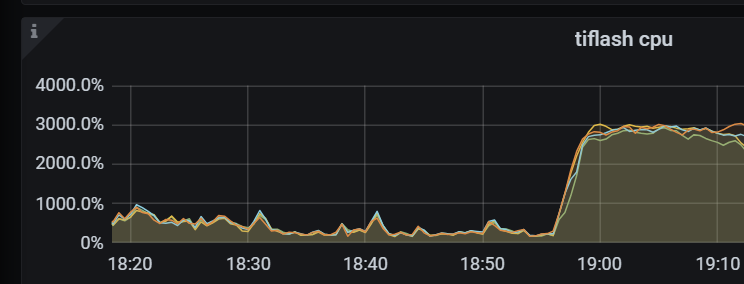
线上集群,tiflash的几个节点,cpu突然被打满
按照经验应该是一批烂SQL打进去的
问题:
从什么途径能够找到,tiflash中最占cpu的SQL?
dashboard的top sql里,只能看到tidb和tikv节点
现象描述:
线上集群,tiflash的几个节点,cpu突然被打满
按照经验应该是一批烂SQL打进去的
问题:
从什么途径能够找到,tiflash中最占cpu的SQL?
dashboard的top sql里,只能看到tidb和tikv节点
在慢sql日志里面找
查找日志文件路径show variables like’tidb_slow_query_file’;
SELECT QUERY, query_time, stats
FROM information_schema.slow_query
WHERE Plan LIKE ‘%tiflash%’
ORDER BY Query_time DESC;
看一下
感谢上面两位的帮助
慢SQL不好查的,CPU被打高了之后,所有sql都是慢SQL了
线上环境,qps在100多,很难肉眼排查,只能依赖于Top SQL这种统计信息
非常难找。
可以尝试用楼上这个sql列出所有可疑对象。
然后进plan这个执行计划字段里面,就找actRows 这一列对应很大数字的。
这个数字越大就越耗资源,cpu和内存都耗的多。
不过我发现内存的统计可能不准,有的时候内存都爆了,统计却很低。
但是共同点就是actRows 和estRows的数字都很大。越大就越容易炸。
找返回值多的,频繁执行的
其实 tiflash cpu 高对应的就是扫描的数据多,扫描数据多又分两种情况
可以参考以下sql(需要自行修改时间范围)
select sum(total_keys)/count(digest) avg_keys,digest,min(query)
from CLUSTER_SLOW_QUERY
WHERE Time > ‘2022/02/12 12:00:00’
AND time < ‘2022/02/12 13:00:00’
group by digest
ORDER BY avg_keys DESC
LIMIT 10;
select sum(Process_keys),digest,min(query) from CLUSTER_SLOW_QUERY
WHERE Time > ‘2022/02/12 12:00:00’
AND time < ‘2022/02/12 13:00:00’
group by digest
ORDER BY sum(Process_keys) DESC
LIMIT 10;
新版本 dashboard 里面有 top SQL,选下 tikv 节点会自动弹出 top SQL。
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。