zhimadi
(Zhimadi)
1
【 TiDB 使用环境】生产环境
【 TiDB 版本】V5.4.2
【复现路径】做过哪些操作出现的问题
1、集群原本有6个tikv节点,都是16核32G配置的云主机,运行正常。
2、打算先把4台逐个升级配置至24核48G内存,再缩容2台。
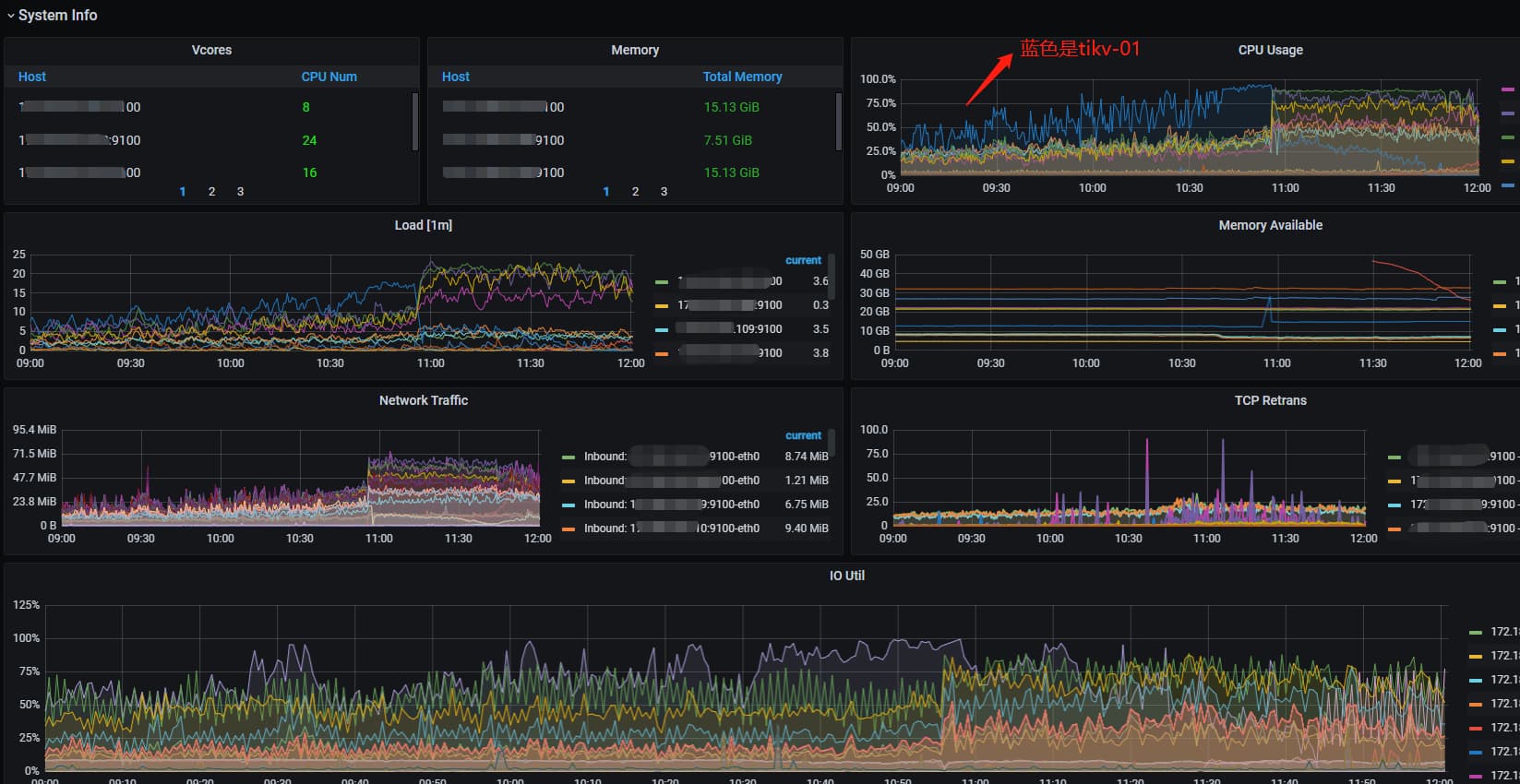
3、现已经把其中4台升配且缩容了1台。第6台还没来得及缩容。目前群集是5kv,4个24核,1个老kv(tikv-01)是16核的。
【遇到的问题:问题现象及影响】
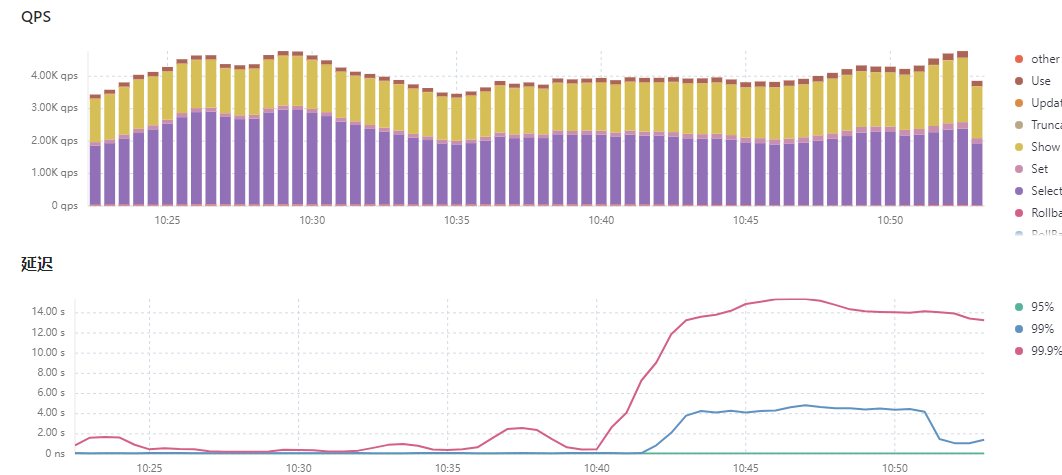
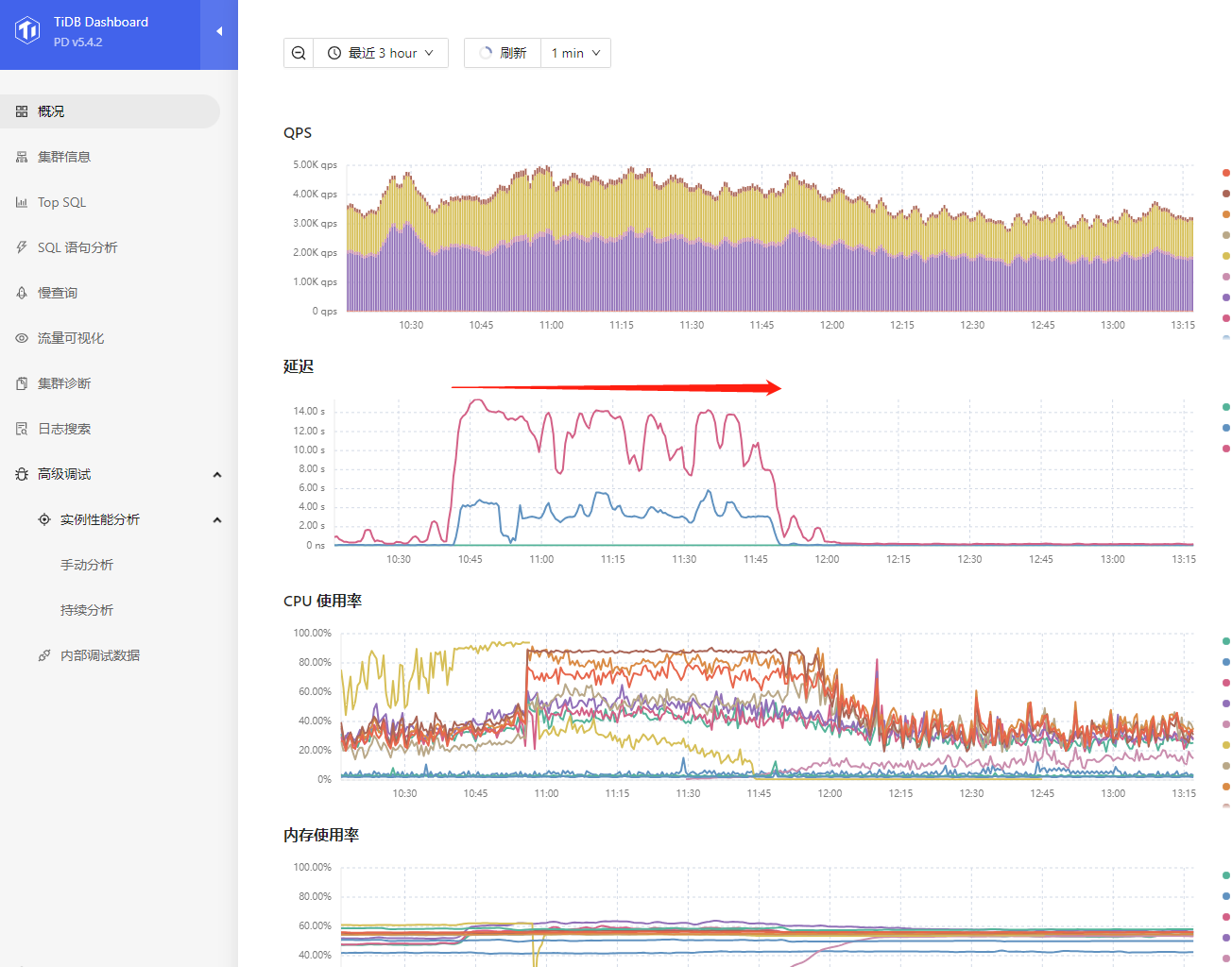
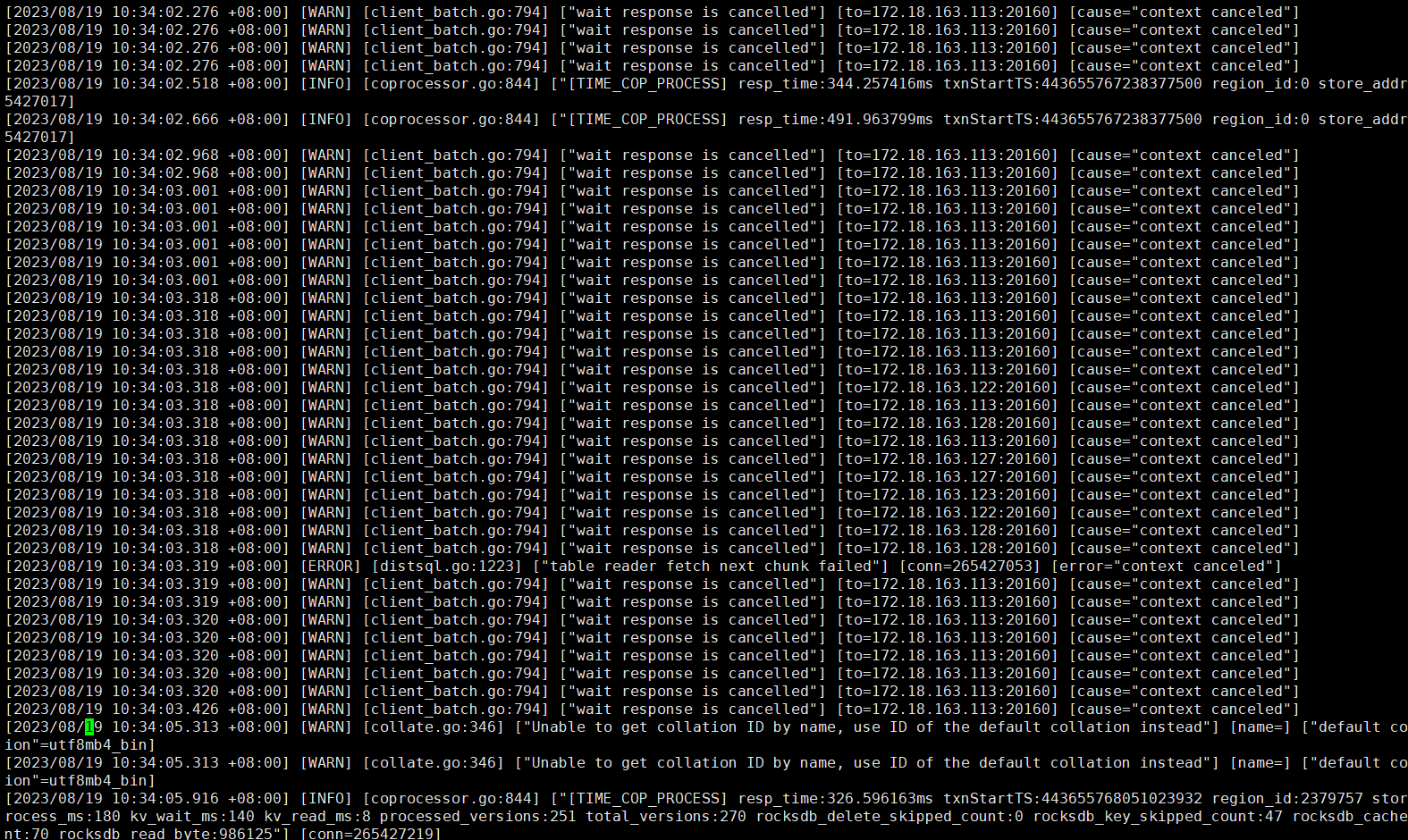
今天早上10点40业务高峰遇到16核的tikv-01节点负载奇高,系统出现延迟,大量8秒以上的慢查询。查看执行计划,几乎都是最长处理时间实例tikv-01节点。
在10点45分执行缩容tikv-01,结果就出现雪崩。业务卡顿长达一小时。直至tikv-01的region降到0才有所缓和。
在11点20分的时候紧急执行扩容新机器,到目前为止还没同步完region。
查看tidb.log发现大量请求转到tikv-01机器上处理。
此时跑路已经来不及了。遂立帖求救社区友友们,如何查出前因后果,以及后续应对的办法。
要看哪些参数和日志锁定原因?
【资源配置】
各节点磁盘使用量均在40%-50%;
tikv节点的region在4.5k左右。
【附件:截图/日志/监控】
附图1:
附图2:
附图3:
附图4:
redgame
(Ti D Ber Pa Amoi Ul)
4
缩容操作导致负载在其他节点上分布不均,导致性能下降
扩容缩容建议一个节点一个节点操作,且等region均衡了再执行下一个节点,业务时间点操作可以把store limit调得很小,可以把时间拉很长,否则region调度很耗io同时leader反复切换会造成大量backoff,对线上业务造成影响
1 个赞
zhanggame1
(Ti D Ber G I13ecx U)
7
猜测原因是缩容的时候leader分布不均,tikv-01上的leader太多,这个可以通过grafana的pd监控看到当时leader分布情况。
可以考虑开启follower read功能缓解leader集中到一个tikv上的问题
对生产环境的集群做扩容还好,缩容操作就尽量再业务低谷期进行或者把调度的region 数和leader数配置调低,否则容易出现楼主描述的集群资源被挤兑的现象
1 个赞
wakaka
(Wakaka)
9
io util之前就是50%—80%,加上缩容导致的额大量IO,有个节点一直都是80%–100%。导致大量SQL变慢,进而血崩。
zhimadi
(Zhimadi)
10
可是缩容1个TIKV超过24小时了,也没出问题。1天后才出现的性能问题。
zhimadi
(Zhimadi)
11
会不会跟缩的两个tikv是最初创建集群的tikv有点关系?
zhimadi
(Zhimadi)
12
是一个节点一个节点操作,第1个TIKV缩容都超过24小时后,才出现的性能问题。
zhimadi
(Zhimadi)
14
是手动执行那个scheduler add evict-leader-scheduler 调整吗?
你相当于6个tikv节点,先通过重启的方式升级了4个tikv节点的内存和cpu,重启完成之后,并没有看是否leader是否均衡,然后下线了2台没升级的tikv中的一个,在24小时之后,才开始出现性能问题
那这里就需要查看当时的leader分布情况,以及当时是否有热点信息了。
zhimadi
(Zhimadi)
17
对,操作步骤就是这样。当时并没有看leader。这种情况下,是要等上一段时间再下线吗?还是可以手工干预?使用什么命令?
扩容完,可以先看下grafana的leader分布监控页面,一般所有节点资源一致的话leader数也是基本一致的,像你这种部分配置扩容的,应该leader更多,然后选低配置中的leader节点较少的节点下线,下线之前可以先通过pdctl来执行scheduler add evict-leader-scheduler store_id驱逐掉要下线的tikv的leader