【 TiDB 使用环境】生产环境
【 TiDB 版本】6.4.0
【复现路径】delete表中大量数据后手动compact
【遇到的问题:手动campact后确实释放了部分磁盘空间但是整个系统负载长时间八十五左右,反应缓慢,导致业务被影响,手动停止以后发现compact的指令变成了僵尸进程,切cpu负载没有什么明显变化
【资源配置】

tikv.log (6.8 MB)


【附件:截图/日志/监控】
【 TiDB 使用环境】生产环境
【 TiDB 版本】6.4.0
【复现路径】delete表中大量数据后手动compact
【遇到的问题:手动campact后确实释放了部分磁盘空间但是整个系统负载长时间八十五左右,反应缓慢,导致业务被影响,手动停止以后发现compact的指令变成了僵尸进程,切cpu负载没有什么明显变化
【资源配置】
【附件:截图/日志/监控】
这是compact并没有停止,还没跑完
kv都失联了?
rocksdb.rate-bytes-per-sec 这个参数调低看看
直接全部tikv执行的compact?
一会就过去了吧,不会一真这样。
在每个tikv节点上都跑了一下compact
这是执行的命令
nohup ./tikv-ctl --host xxx compact -d kv -c write &
nohup ./tikv-ctl --host xxx compact -d kv -c default &
nohup ./tikv-ctl --host xxx compact -d kv -c lock --bottommost force &
nohup ./tikv-ctl --host xxx compact -d kv -c write --bottommost force &
有一个已经恢复了,但是还是有两个没办法在dashboard看到
compact tikv的数据,很耗io和cpu,建议一个节点一个节点做,同时需要在业务低峰期做,同时应该考虑对业务的影响针对性的设置–threads参数
你这直接全量做,而且是下午2点,出现这样的情况也在清理之中吧。。。
这个本来是从凌晨十二点开始做的,然后一直到第二天下午两点还没有结束,cpu长时间占用太高了,只能先手动kill了,但是他似乎并没有停止的意思,cpu负载还是很高,找了一下文档还有论坛的其他的帖子,也没有看见类似的彻底的解决方案
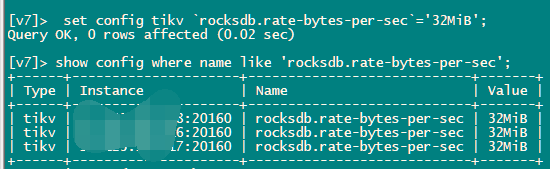
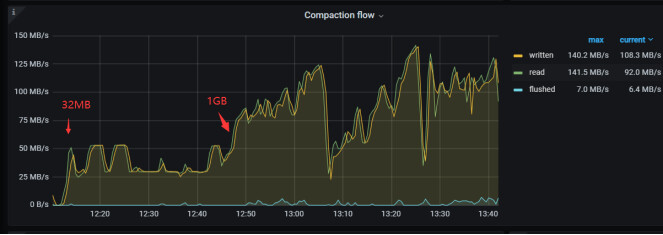
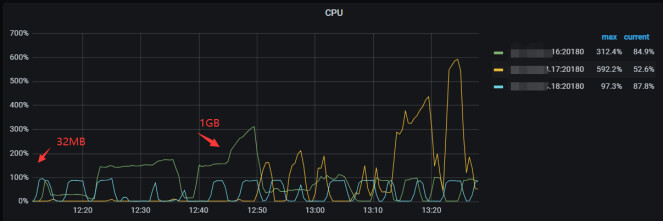
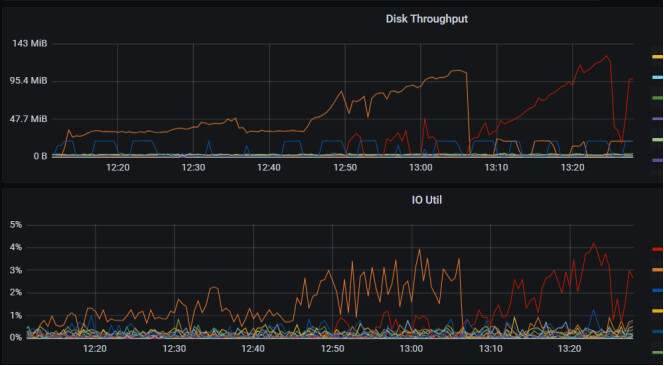
这个参数的意义是什么呢?
这边最后因为cpu占用实在是太高了,且有僵尸进程导致不断告警,最后进行了tikv单节点重启系统现在恢复了
启动了再杀tikv-ctl命令应该没用了,得重启tikv才行
嗯嗯,最后还是tikv单节点重启了,重启以后系统逐渐恢复正常
限速,磁盘读写速度
因为现在系统恢复了,不方便再复现当时的场景,这个参数对于compact的效果现在不太清楚,如果有下次delete数据的话可以试一下,还有一个问题,这个参数设置后需要重启吗?
在线设置
了解🫡,感谢🙏

