【 TiDB 使用环境】生产环境
【 TiDB 版本】6.5.0
【复现路径】未知
【遇到的问题:问题现象及影响】
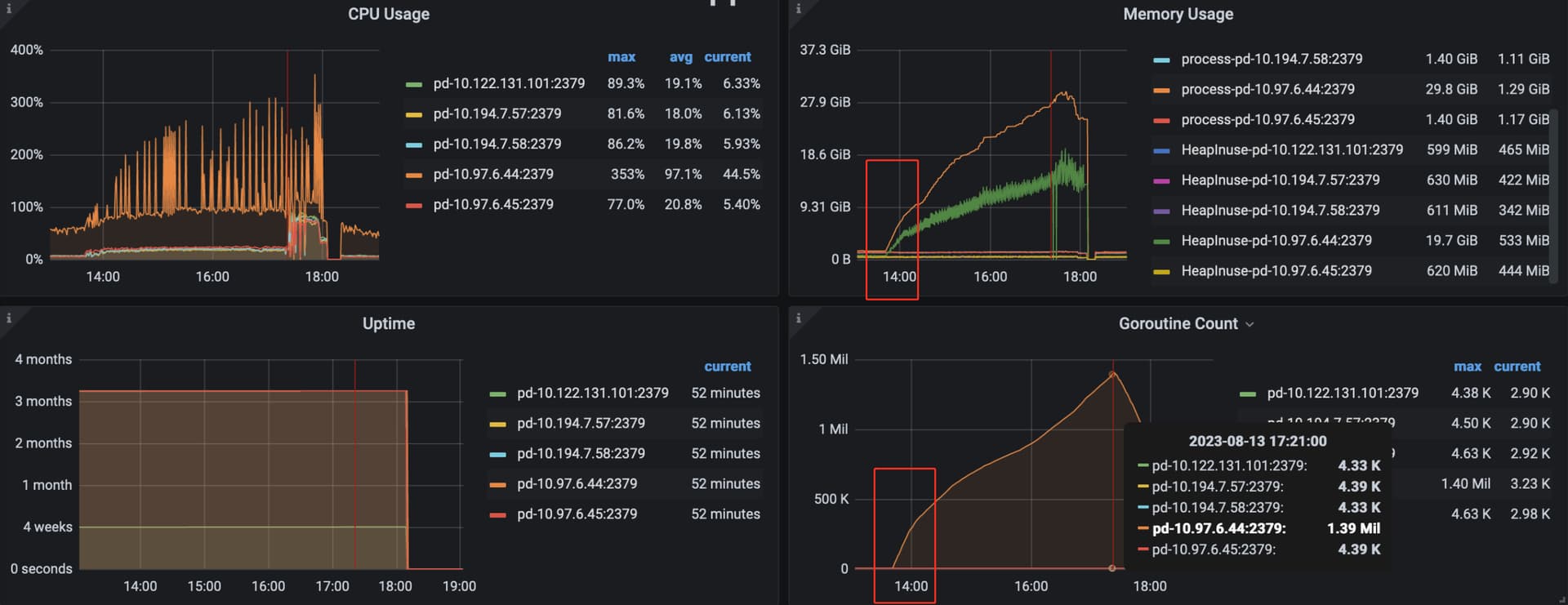
内存大量增加,最终触发swap后,整个tidb集群不可用。能查到是什么原因导致的突然内存升高吗?
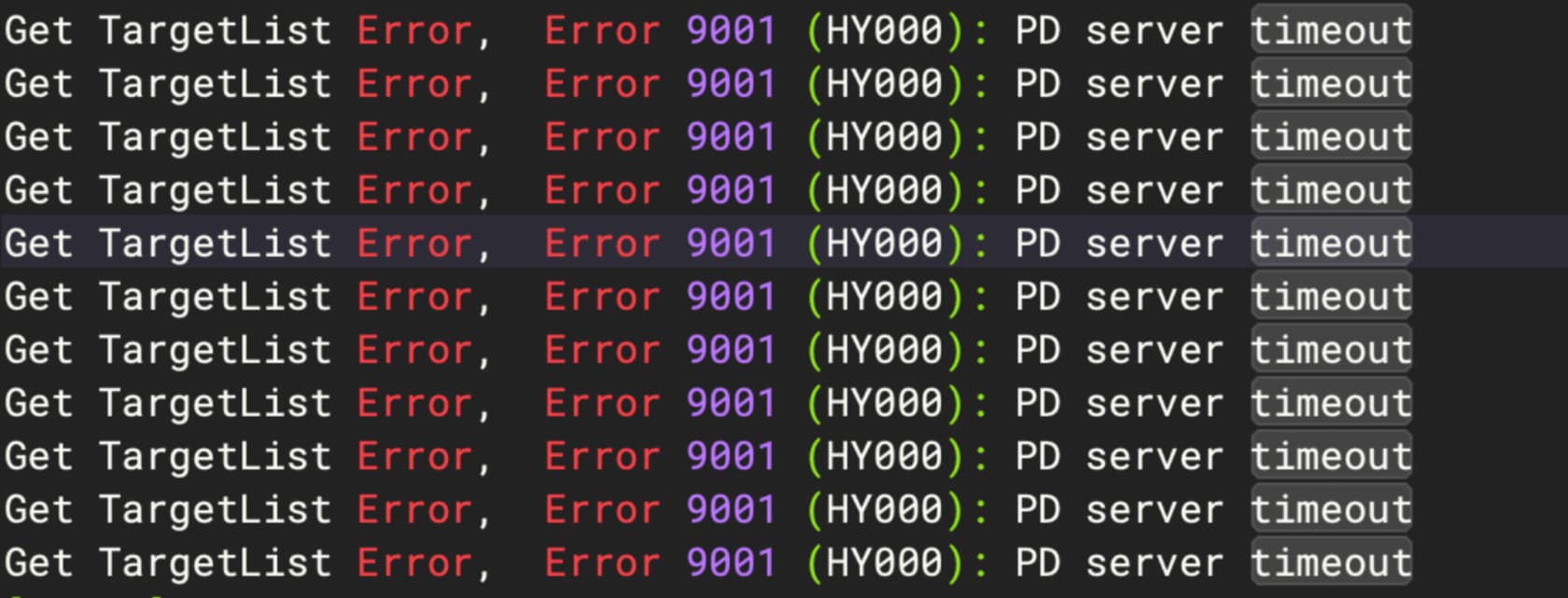
客户端报
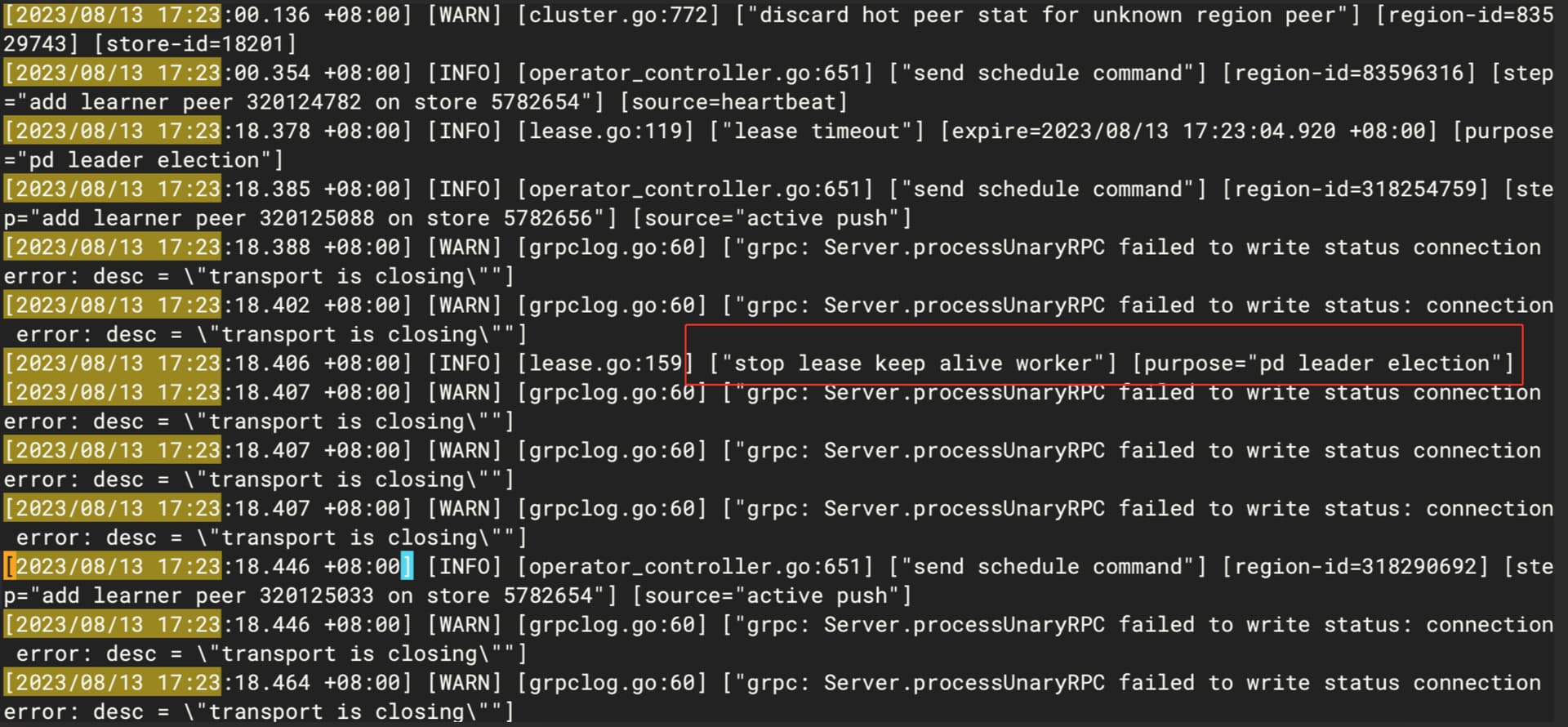
从pd的leader日志看,出现了pd选举,但是从最终结果看,没有leader没有切换
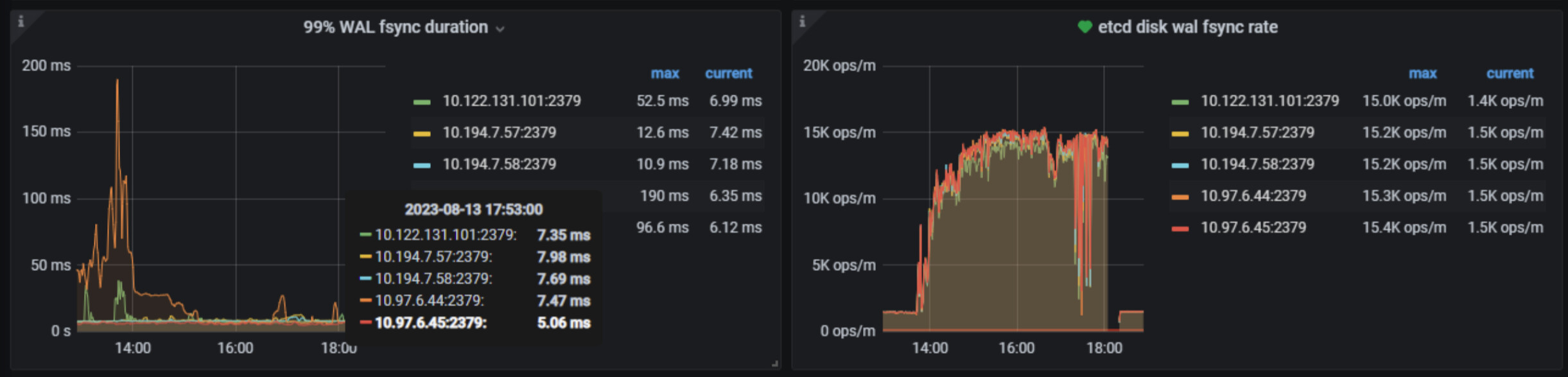
etcd有大量的fsync操作
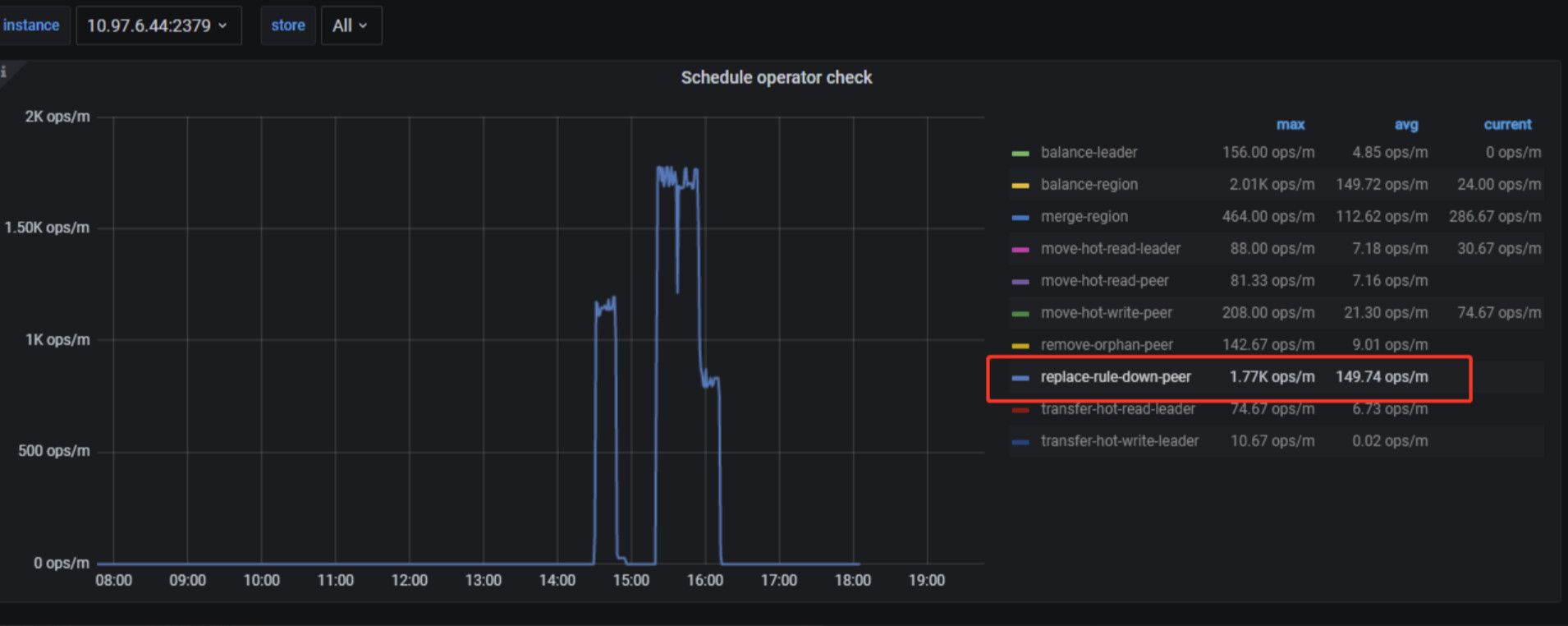
有很多schedule operator的操作
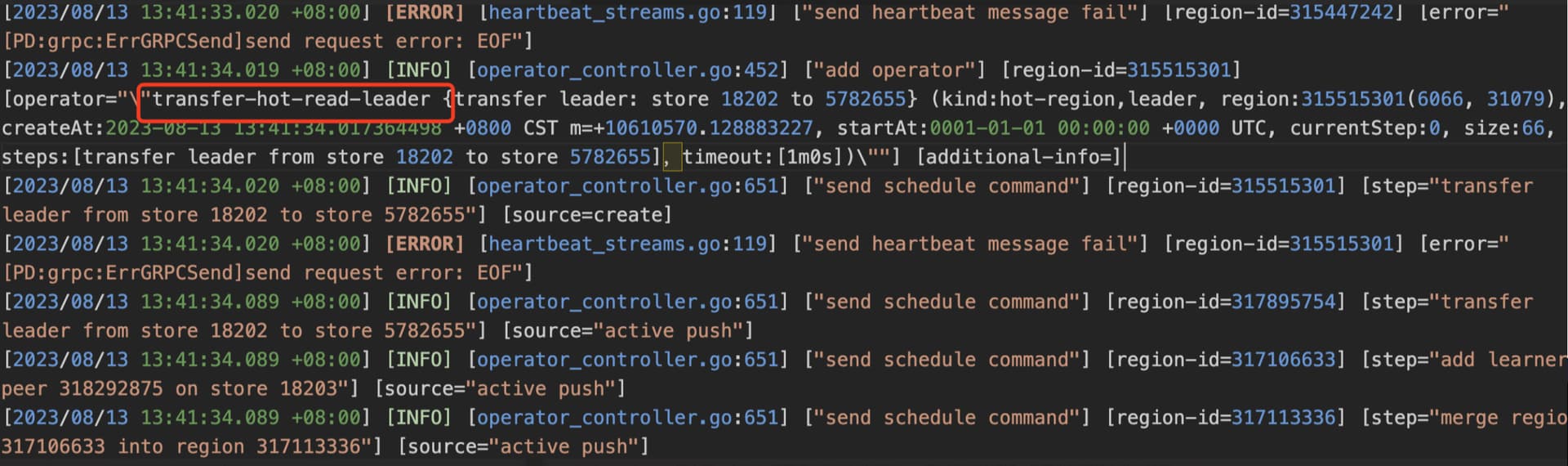
pd日志,有大量的心跳超时的报错
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
