【 TiDB 使用环境】生产环境
【遇到的问题:问题现象及影响】
数据库内存在一个视图(View), 该视图进行了一个联表操作,将用大表左联元数据表,得到了一个视图user,user存在近五百万条数据,大小是 4G左右。
使用SELECT id, count(1) as total from user ui group by id order by total desc limit 100进行查询,tidb节点出现内存骤增的情况(短时间内增长了将近5G),但是在查看相关日志时发现监控的内存增量和日志中SQL的内存占用空间并不一致(该SQL只占用了250Mi左右)
想问一下SQL内存占用的计算逻辑是什么样的?
【附件:截图/日志/监控】


大致是,各个算子分配内存空间,中间结果的内存空间,加一起
监控(prometheus、granfana)中内存是整个实例的内存使用,是实际使用的内存包括还未GC的对象,是golang语言层面提供的统计数据,是准确的内存开销。
慢日志、information_schema.processlist中内存使用是tidb根据记录数等进行统计评估的只能做到“比较准确”,存在的问题是:1、统计的一些记录(如chunk)内存占用不一定很准,通常来说比较准确;2、可能存在一些内存开销没有统计进来的情况,但是更新的版本内存统计更全面;3、“销毁”的对象是没有办法统计进来的,但是在gogc未发生前还是会占用内存的。
SQL内存占用的计算逻辑(show processlist或者慢日志等看到的)是比较复杂的,主要是通过内存追踪的方式统计的:
什么是内存追踪
在tidb-server中引入了一套内存追踪框架,用于统计每一个连接中语句执行过程中内存使用情况,以方便当语句占用内存过大时触发oom-action的行为,保护实例整体资源可用。
内存追踪的最小单元是一个tracker,将其插入到语句执行的各个阶段,根据语句->算子->算子内数据处理形成树形层次,每一次数据处理产生的内存使用都会统计到tracker中,并把内存使用情况累加到parent tracker中,最终汇总到root tracker,因此就形成了一颗内存追踪树。
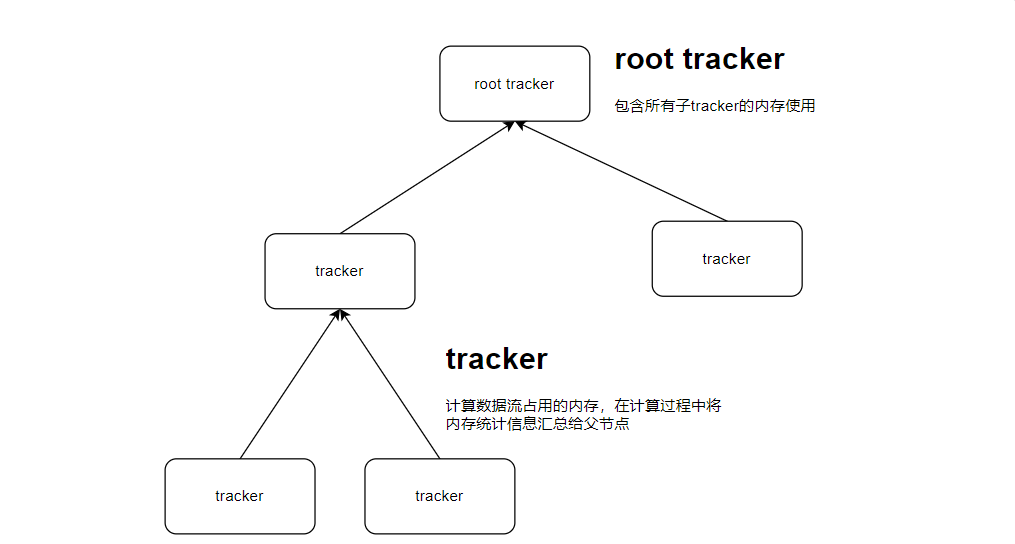
这里的root tracker获取到的内存就是你从慢日志中看到的语句内存占用大小。
内存追踪的实现
对于内存追踪最核心的结构体是Tracker:
type Tracker struct {
bytesLimit atomic.Value
actionMuForHardLimit actionMu
actionMuForSoftLimit actionMu
mu struct {
// The children memory trackers. If the Tracker is the Global Tracker, like executor.GlobalDiskUsageTracker,
// we wouldn't maintain its children in order to avoiding mutex contention.
children map[int][]*Tracker
sync.Mutex
}
parMu struct {
parent *Tracker // The parent memory tracker.
sync.Mutex
}
label int // Label of this "Tracker".
// following fields are used with atomic operations, so make them 64-byte aligned.
bytesConsumed int64 // Consumed bytes.
bytesReleased int64 // Released bytes.
maxConsumed atomicutil.Int64 // max number of bytes consumed during execution.
SessionID uint64 // SessionID indicates the sessionID the tracker is bound.
NeedKill atomic.Bool // NeedKill indicates whether this session need kill because OOM
NeedKillReceived sync.Once
IsRootTrackerOfSess bool // IsRootTrackerOfSess indicates whether this tracker is bound for session
isGlobal bool // isGlobal indicates whether this tracker is global tracker
}
其中比较重要的属性:
actionMuForHardLimit:硬限制动作链实现了ActionOnExceed接口,当内存使用bytesConsumed达到了硬限制上限后触发的oom-action行为,硬限制上限即为tidb_mem_quota_query参数设置值。
actionMuForSoftLimit:软限制动作链实现了ActionOnExceed接口,当内存使用bytesConsumed当达到了软限制上限后触发的oom-action行为,软限制上限即为0.8 * tidb_mem_quota_query参数设置值,目前软限制动作只有hashAgg算子落盘行为,其它均为硬限制动作。
bytesConsumed:当前tracker追踪的内存大小,并汇报给父节点,根节点包含了整个语句使用的内存大小,当大于语句级内存控制变量tidb_mem_quota_query时触发oom-action行为。
maxConsumed:曾经使用过的最大内存,主要用于processlist显示当前算子的最大内存消耗。
mu:记录父节点的tracker,用于形成追踪树。
该结构体最重要的一个方法是Consume(bs int64),用于将内存消耗bs加到bytesConsumed中。当bs为正数时说明正在消耗内存,比如从磁盘中读取chunk数据到内存就增加内存占用,当bs为负数时候说明正在释放内存,比如从内存中写入磁盘临时文件。其核心逻辑如下:
-
通过当前的tracker递归调用getParent()方法,将当前的内存消耗值tracker.bytesConsumed累加到父节点上。
-
对于层级中的每一个tracker判断其经过子节点累加后的tracker.bytesConsumed是否大于tracker.maxConsumed,如果大于,那么将tracker.maxConsumed设置为tracker.bytesConsumed。
-
循环结束后找到rootTracker(当前会话的顶层tracker),如果rootTracker的bytesConsumed比硬限制设置大,则记录找到rootExceed(=rootTracker),如果rootTracker的bytesConsumed比软限制设置大,则记录找到rootExceedForSoftLimit(=rootTracker)。
-
如果当前实例内存占用超过tidb_server_memory_limit,那么将占用内存最多的一条语句杀掉。这里会判断当前的rootTracker是否已经被系统标记为被执行对象,如果是则触发Cancel动作。
-
如果存在rootExceed,说明语句内存超过限制值,则触发硬限制的oom-action行为。
-
如果存在rootExceedForSoftLimit,说明语句内存超过限制值*0.8,则触发软限制的oom-action行为。
因此通过不停的调用Consume()方法对当前消耗的内存进行记录,对算子、语句内存消耗进行统计并触发oom-action行为。
3 个赞
这个怎么控制,我们之前也出现单个sql打死tikv的情况
我观察过也是有些sql会占用大量tidb的内存,从sql统计上看少得多
感谢,但是我还是比较疑惑,因为按照您的说明,Grafana的监控和Dashboard的记录结果应该是相近的,但是现在的差距明显很大,这个是因为某些算子的内存空间没有被统计到吗?
版本太老了。400w的表7.1.1做了测试没有复现。
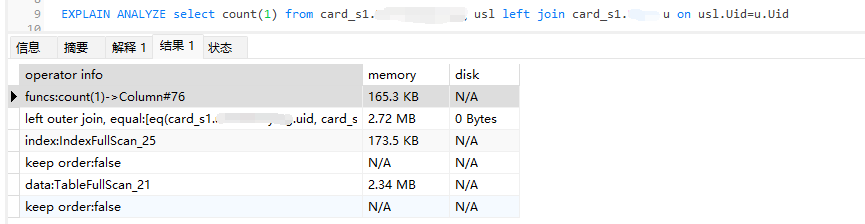

bashboard里面 TiDB Memory Usage基本看不出任何波动。应该没有计算错误。
我们的差距就在这个表的大小上,条数差100w,但大小你比我要大几倍。
我手头其他大表都加了tiflash,没有办法还原测试了。
是的。主要是HashAgg里面在低版本中一些内存消耗没有被追踪到。你可以换一个高版本比如7.1再用同样数据看看,我估计会好很多。