【 TiDB 使用环境】生产环境
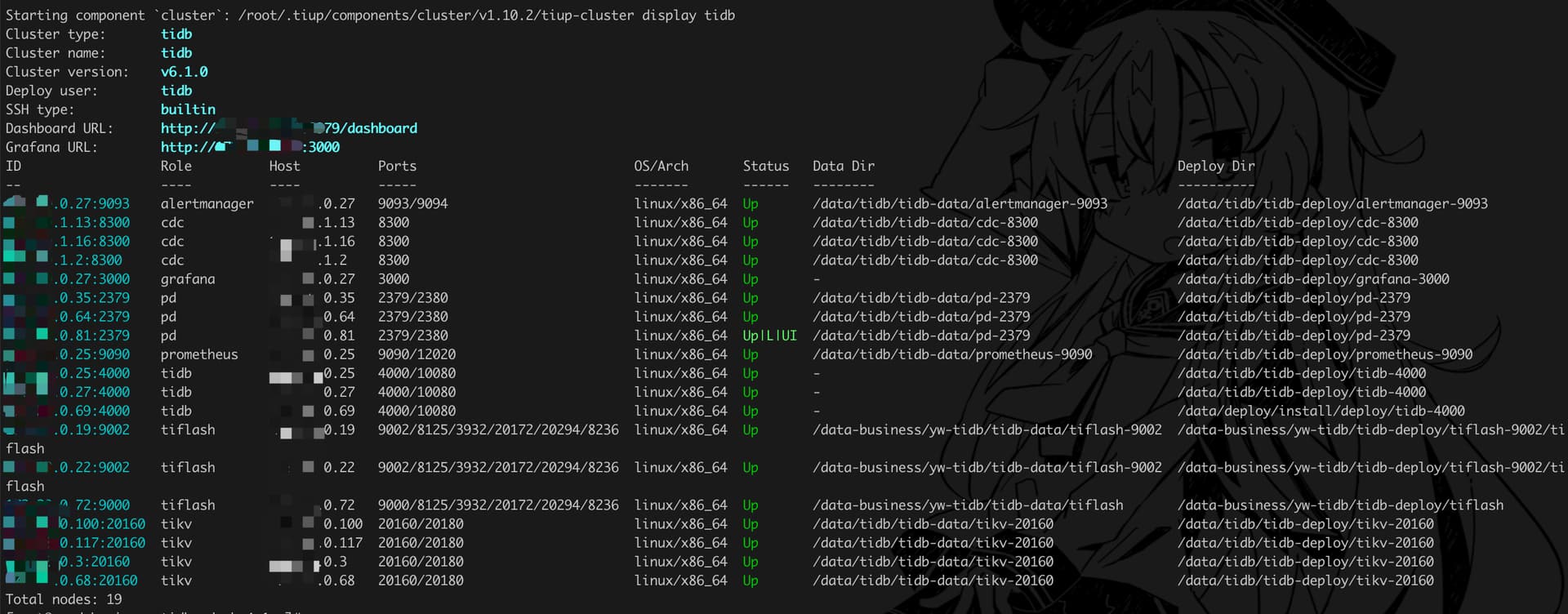
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
配置如下:
» config show
{
"replication": {
"enable-placement-rules": "true",
"enable-placement-rules-cache": "false",
"isolation-level": "",
"location-labels": "",
"max-replicas": 3,
"strictly-match-label": "false"
},
"schedule": {
"enable-cross-table-merge": "true",
"enable-joint-consensus": "true",
"high-space-ratio": 0.8,
"hot-region-cache-hits-threshold": 3,
"hot-region-schedule-limit": 4,
"hot-regions-reserved-days": 7,
"hot-regions-write-interval": "10m0s",
"leader-schedule-limit": 4,
"leader-schedule-policy": "count",
"low-space-ratio": 0.9,
"max-merge-region-keys": 300000,
"max-merge-region-size": 20,
"max-pending-peer-count": 64,
"max-snapshot-count": 64,
"max-store-down-time": "30m0s",
"max-store-preparing-time": "48h0m0s",
"merge-schedule-limit": 10,
"patrol-region-interval": "10ms",
"region-schedule-limit": 2048,
"region-score-formula-version": "v2",
"replica-schedule-limit": 64,
"split-merge-interval": "1h0m0s",
"tolerant-size-ratio": 0
}
}
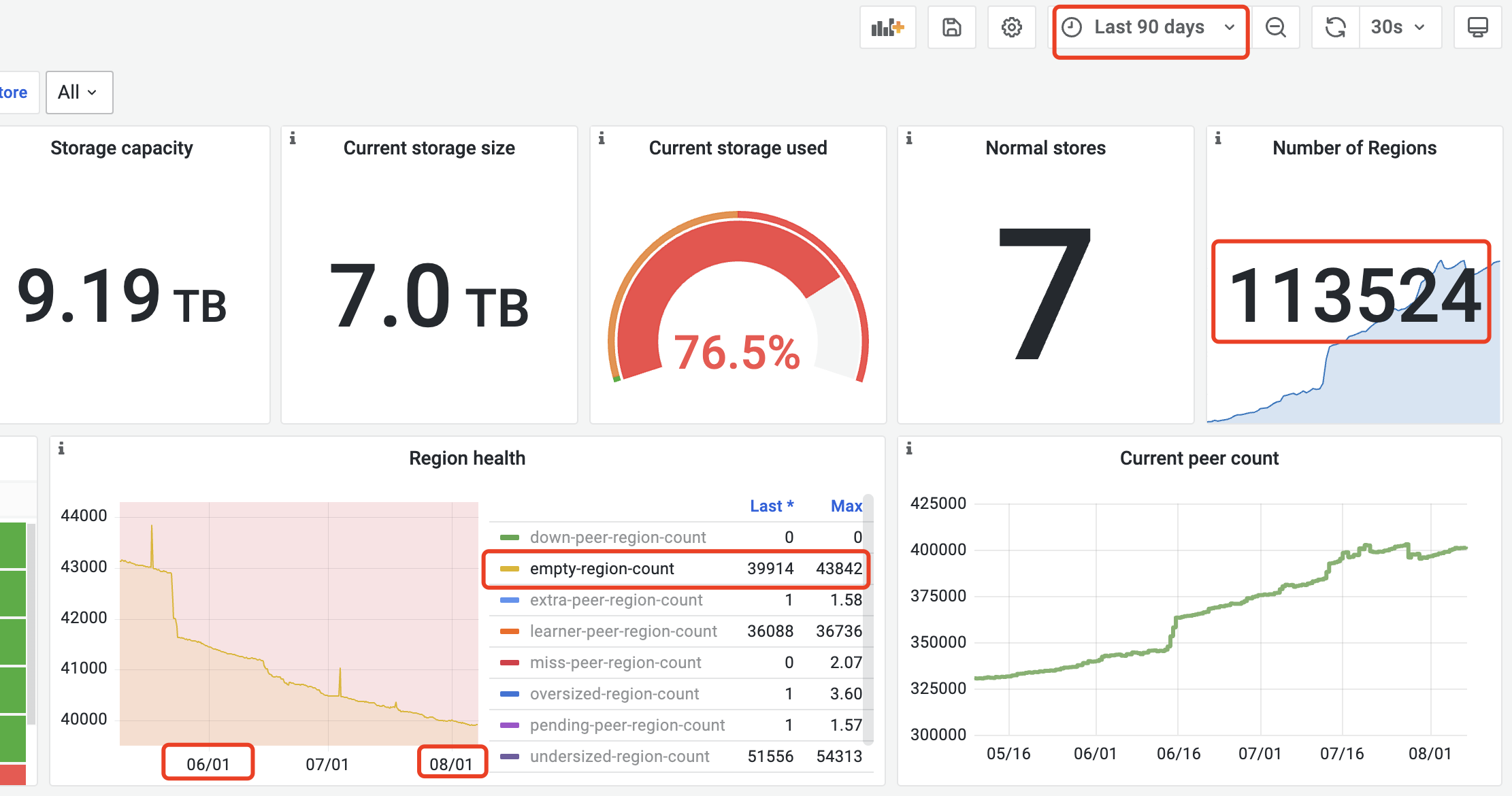
通过 region 表查询到的数据量为:12TB,实际磁盘占用是7.1TB
MySQL [INFORMATION_SCHEMA]> select sum(APPROXIMATE_SIZE) from tikv_region_status;
+-----------------------+
| sum(APPROXIMATE_SIZE) |
+-----------------------+
| 12892933 |
+-----------------------+
1 row in set (3.81 sec)
部署信息
h5n1
2023 年8 月 7 日 09:19
2
经常有truncate 或drop操作吗? 没有tiflash吧
有 tiflash,半年之前有 truncate 操作,最近应该没有。
h5n1
2023 年8 月 7 日 09:35
5
设置为tiflash的表 会导致相邻边界的不能被合并,如果只有一次truncate 合并速度看起来是很慢,系统忙吗,磁盘压力大不,除了pd-config的limit外 还有store limit会现在region的调度速度,可以Pd-ctl store limit调整下
1 个赞
tilash 磁盘iops 现在平均2w 左右(盘的上限是6w,之前平均4w 系统都比较正常),cpu,内存都比较充裕。 tikv只有几千的iops.
region 信息里 table_id 为 null,keys 为0的能否排除和 tiflash 有关?
MySQL [INFORMATION_SCHEMA]> select count(*) from tikv_region_status where APPROXIMATE_KEYS=0 and TABLE_ID is null;
+----------+
| count(*) |
+----------+
| 18230 |
+----------+
1 row in set (4.45 sec)
是不是有很多小表或很多 partitions,另外设置 tiflash 副本的都是哪些类型的表呢
redgame
2023 年8 月 7 日 21:31
8
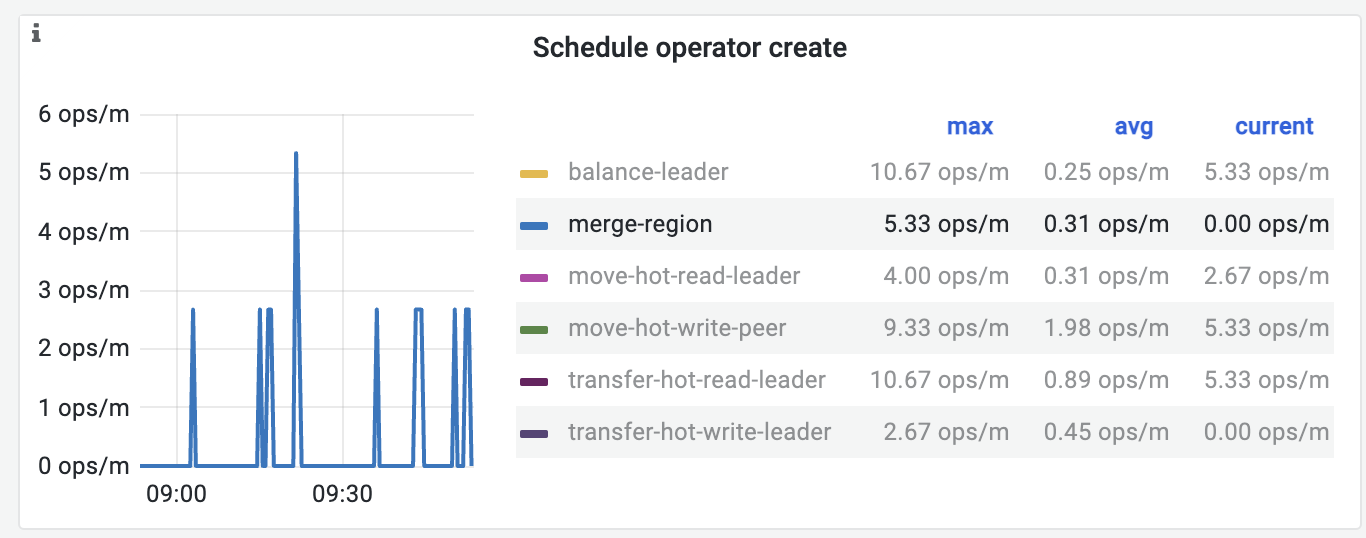
如果你的 TiDB 集群一直处于高负载状态,那么 Merge 进程可能没有足够的资源进行操作
有比较多的 partitions,也有比较大的用了 partitions 表的相关的 tiflash 副本
store limit 默认每分钟是15 可以适当调大试试
tiflash 这边不允许垮表 merge region,如果带有 tiflash 副本的比较小的 partitions/tables 数量基本和当前 empty regions 数量一样的话。估计就是这个限制了
1 个赞
select * from INFORMATION_SCHEMA.TIKV_REGION_STATUS
前期有大量的操作region,单个region 大于20M(默认20M),就没有触发merge
MySQL [INFORMATION_SCHEMA]> select count(1),sum(APPROXIMATE_SIZE), avg(APPROXIMATE_SIZE) as SIZE,avg(APPROXIMATE_KEYS) from TIKV_REGION_STATUS where TABLE_ID is null and APPROXIMATE_SIZE > 50;
+----------+-----------------------+---------+-----------------------+
| count(1) | sum(APPROXIMATE_SIZE) | SIZE | avg(APPROXIMATE_KEYS) |
+----------+-----------------------+---------+-----------------------+
| 28051 | 2500873 | 89.1545 | 543835.7832 |
+----------+-----------------------+---------+-----------------------+
1 row in set (2.69 sec)
现在 table_id null的 region,大于50MB 占用了2.5T空间,如果 merge 不到,这部分空间有办法释放出来吗?
Aric
2023 年8 月 11 日 02:09
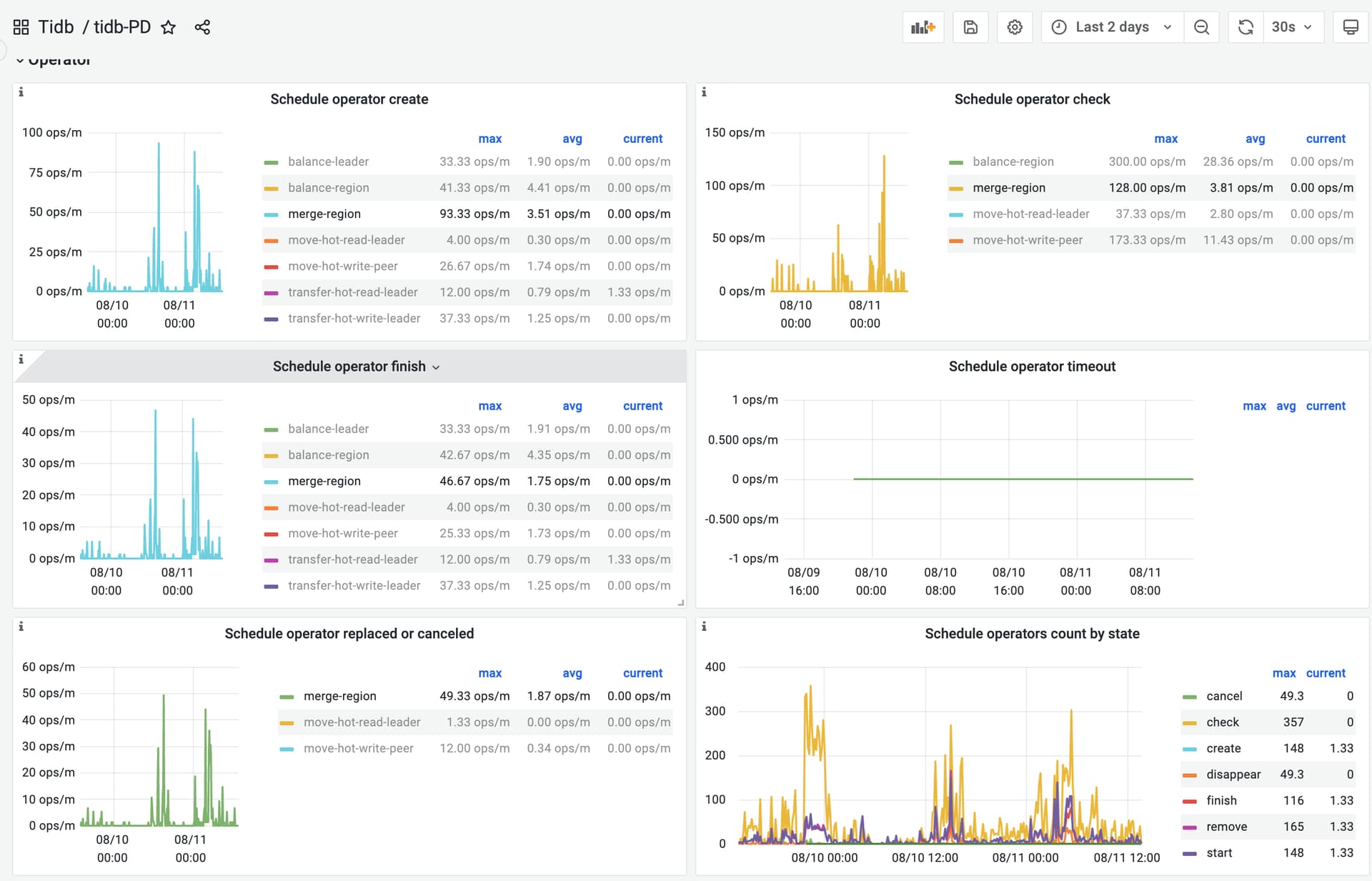
18
operator 有 create 有被 cancel 吗?PingCAP MetricsTool