【 TiDB 使用环境】生产环境
【 TiDB 版本】5.0.4
【遇到的问题:问题现象及影响】
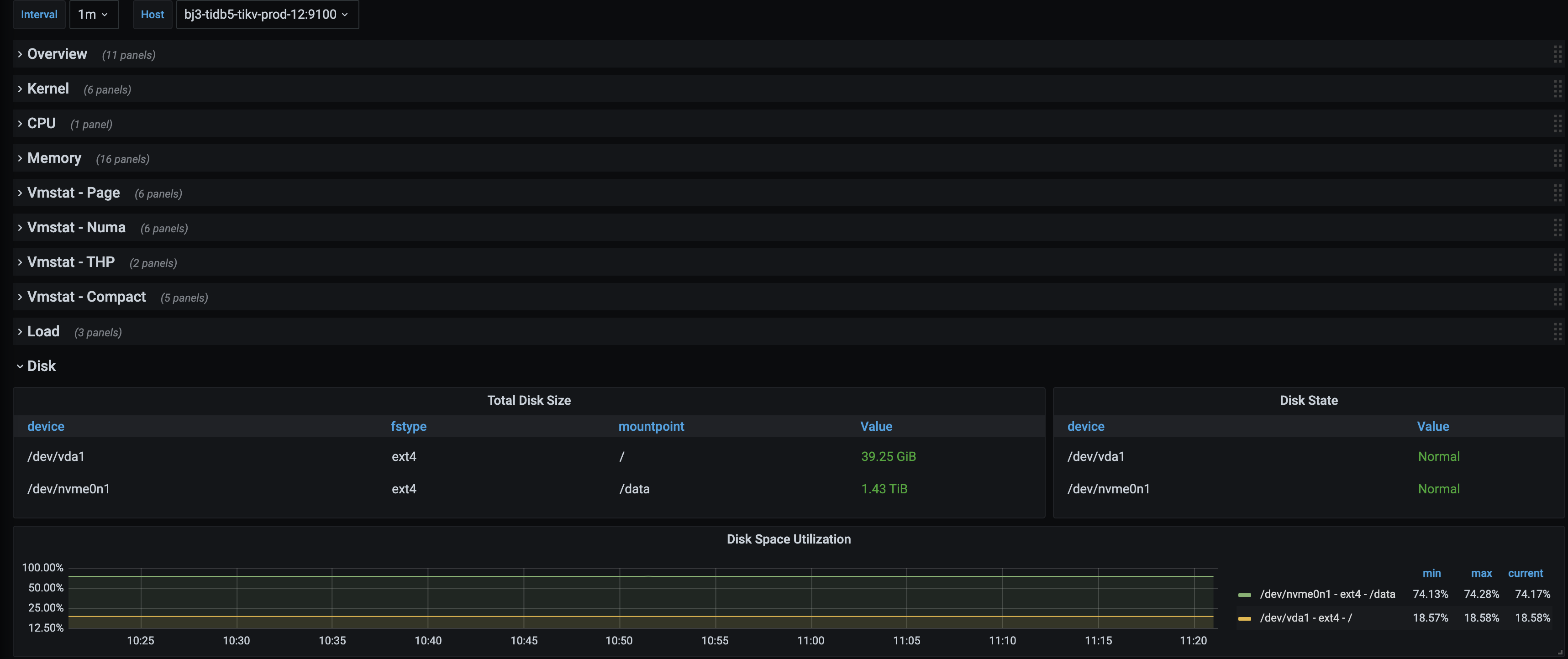
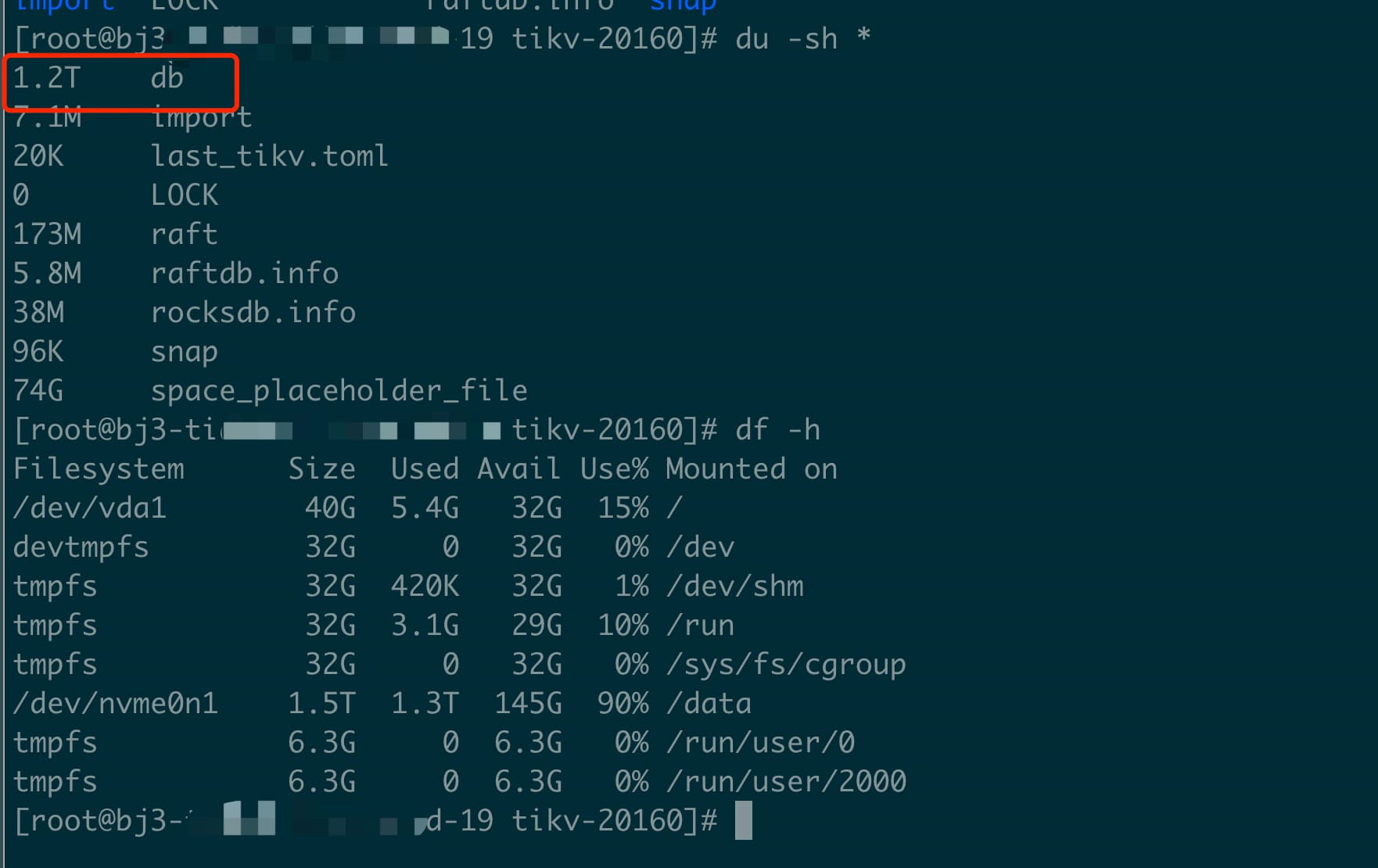
tikv-19 磁盘空间使用率90%,其余tikv使用率<75%
【附件:截图/日志/监控】
- tikv-19、tikv-12均是云厂商服务器,磁盘空间都是1.5T。
-
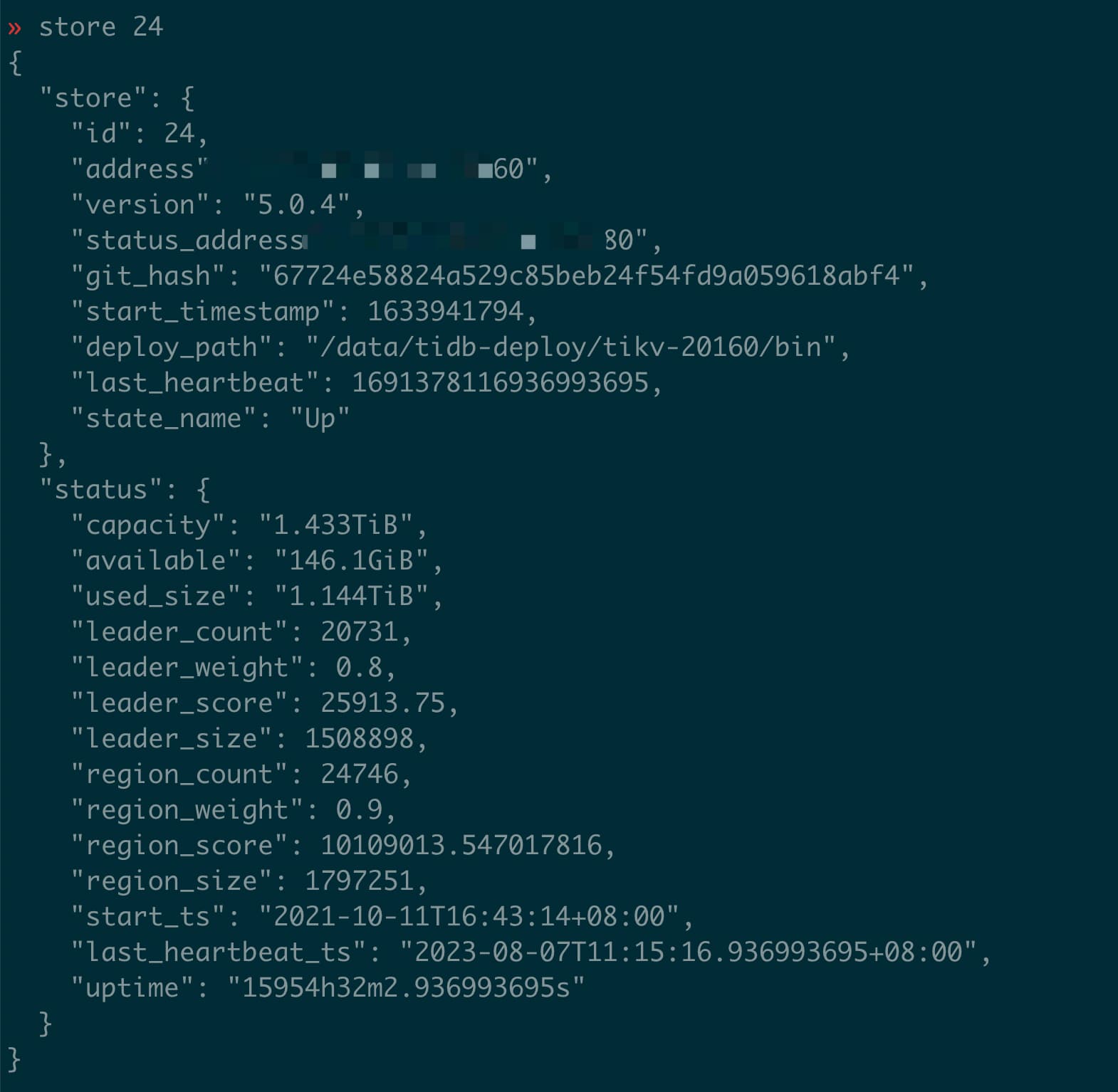
tikv-19 = store-24 tikv-12=store-7
1.确认一下机器配置
2.确认一下是不是都是tikv的占用
3.查看grafana tikv-detail dashboard
先检查一下磁盘吧,感觉tikv-19的磁盘不仅仅是tikv使用了。或者你可以看看tikv-19中的日志占用了多大的空间,是不是日志文件太多了导致磁盘使用太大
1、2 机器配置一致,tikv 单实例部署,只有tikv自己用
3. 看哪个图呢?
文件日志清理了,rock.log-202*, raft-log-202*.
cd db # 可以看到还有22年的sst文件,不知道是否正常。
是的,因为磁盘空间一直涨,改了weight store weight 24 0.8 0.9
region_weight 和 leader_weight的作用:
你这region_size看着不太对啊,store7的region_size都5T了?store24才不到2T。。。但是反而是store24的磁盘使用率较高,store7的磁盘使用率低?
是的,真是情况就是这样。怀疑tikv没有compact,手动执行compact,结果磁盘打爆,磁盘空间用光了。
GC,每10min一次,这个机器的gc 100%过
Aric
(Jansu Dev)
16
这个能导出一份 PD 的 全 metrics 吗? 想看看 Region Score 之类的东西
Aric
(Jansu Dev)
19
嗯嗯 metrics 默认保存 30d, 这个应该还在, 历史记录持久化在 prometheus 里的