开心大河马
2023 年7 月 31 日 07:31
1
【 TiDB 使用环境】生产环境
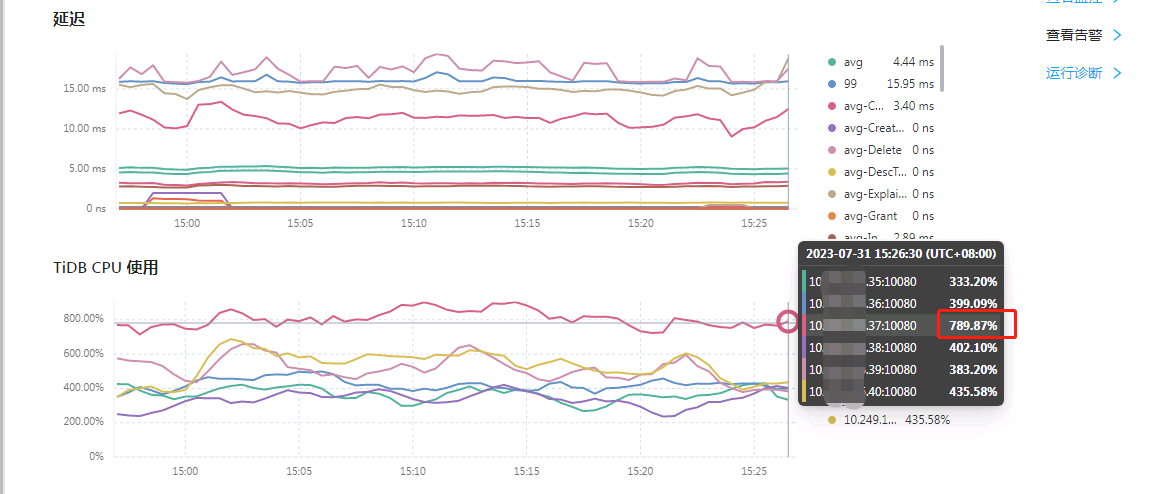
harproxy监控:tidb server-37的看着与节点连接差不多。
tidb server的CPS可以看到差距:
CPU可以看到明显的差别,可以翻倍:
就是想请问下,这个怎么看,为啥差别那么多啊?
有猫万事足
2023 年7 月 31 日 08:08
2
https://docs.pingcap.com/zh/tidb/stable/top-sql#访问页面
可以尝试打开topsql,看看这台tidb的topsql是否和其他几台有显著差异。
开心大河马
2023 年7 月 31 日 09:05
3
topsql的cpu 占比,37比其他节点多了很多,就跟其他正常运行的sql一样,他也比别人高,另外也多一个9%的sql,
其他节点的:
开心大河马
2023 年7 月 31 日 09:07
4
是不是本身就不均匀,底层看到的这个command的,好想就是差距,比别的节点多
有猫万事足
2023 年7 月 31 日 09:16
5
37的sql类型和其他服比,感觉差异不大。前3都差不多。累计cpu耗时长比其他服长,我还是倾向于是37本来就慢。
每一类sql选中后,下面还有
你看看同一类sql,call/sec,latency/call 和其他服对比是个什么情况。如果call/sec差不多,但是latency/call就是比其他的长,应该就说明这个37执行同样的任务就是慢。
如果call/sec已经比别的服高了不少,那就证明是haproxy分配给这个机器的sql多了。或者怀疑是否有些应用不通过haproxy来访问了这个tidb。
开心大河马
2023 年8 月 1 日 02:21
6
目前看着应该是这个节点有点问题,跑的SQL以及执行计划是一致的,他的call值多了还挺多,延迟多了1ms.暂时看不出来是不是请求的分发有问题,haproxy好像是连接数均匀,不是按活跃连接说来;
37节点:cpu最高的节点。
第一个sql:sqlid:7b78200c38238d611ea8bfc1be449427d69e8360d832127fdab452f6ffb4cc3d
call/sec:266.6,lantency/call:6.2ms
第二个sql:sqlid:3a725d4f20843ff3eb0ff8fdeb3b7df463071ba5e31db40b26c2cc6c04b68cb7
call/sec:266.8,lantency/call:6.1ms
35节点:cpu一般的节点
第一个sql:sqlid:7b78200c38238d611ea8bfc1be449427d69e8360d832127fdab452f6ffb4cc3d
call/sec:206.4,lantency/call:5.1ms
第二个sql:sqlid:3a725d4f20843ff3eb0ff8fdeb3b7df463071ba5e31db40b26c2cc6c04b68cb7
call/sec:195.2,lantency/call:5.3ms
36节点:cpu较低的节点
第一个sql:sqlid:7b78200c38238d611ea8bfc1be449427d69e8360d832127fdab452f6ffb4cc3d
call/sec:127.4,lantency/call:5.0ms
第二个sql:sqlid:3a725d4f20843ff3eb0ff8fdeb3b7df463071ba5e31db40b26c2cc6c04b68cb7
call/sec:116.3,lantency/call:5.1ms
有猫万事足
2023 年8 月 1 日 03:19
7
这么看37还真的是任务分的多了。
可以去INFORMATION_SCHEMA.CLUSTER_PROCESSLIST这个表看看每个服连接的host是否有什么变化。HOST这个字段应该都是haproxy的地址。
到这里基本可以肯定是haproxy的分配问题,还是有其他应用没有通过haproxy直连了37.
开心大河马
2023 年8 月 1 日 06:11
8
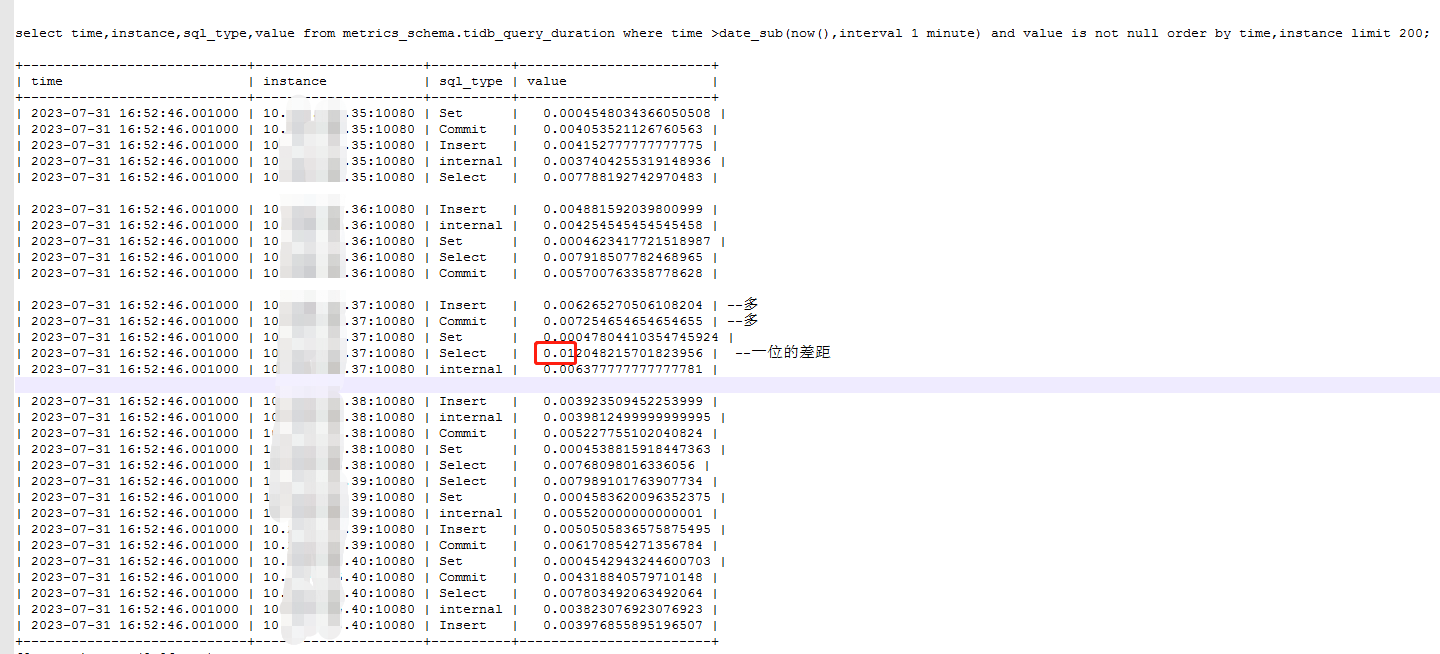
目前已经把37挪到了其他宿主机,37的CPU消耗的确比其他节点高,连续挪2次到最低负载的宿主机,CPU有下来,但是CPS就是没有下来的,后面查看top sql,call/sec 也还是比其他节点多的。
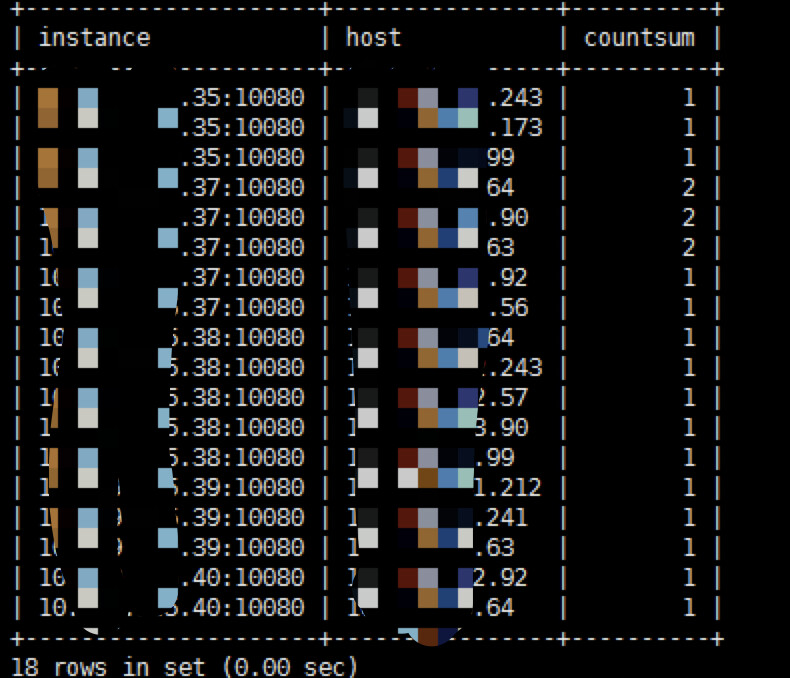
haproxy的话,我们只对外开放了总入口的VIP,目前查看各应用在各个节点基本都有。目前能看到的是haproxy显示的各tidb server的总连接数是一致的,但是各节点不定时的并发人为查看的时候是不太一样的。37还是比较多,不太清楚为啥他的比较多。仅有一个用户(除了root)。select instance,substring(host,1,length(host)-length(substring_index(host, ':',-1))-1) host,count(substring(host,1,length(host)-length(substring_index(host, ':',-1))-1)) countsum from information_schema.cluster_processlist where info is not null and user='xxxx' group by instance,substring(host,1,length(host)-length(substring_index(host, ':',-1))-1) order by instance limit 100;
有猫万事足
2023 年8 月 1 日 08:53
9
https://docs.pingcap.com/zh/tidb/stable/haproxy-best-practices
balance leastconn # 连接数最少的服务器优先接收连接。
从haproxy最佳实践来看,这个平衡策略确实是以保证连接均衡为主。
http://docs.haproxy.org/2.8/configuration.html#4.2-balance
haproxy的文档也贴一下,你也可以找找看,是否有其他更好的平衡策略。
1 个赞
开心大河马
2023 年8 月 1 日 10:25
10
十分感谢,我后面再继续观察看下,你的解决思路很清晰,也很好的处理我这个问题。
我们用haproxy是2.6,具体balance配置路径这里:我在自己看看测试下。https://docs.haproxy.org/2.6/configuration.html#4.2
1 个赞
system
2023 年10 月 1 日 07:35
11
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。