【 TiDB 使用环境】生产环境
【 TiDB 版本】5.4
两张表数据相同,大概都有9000万左右数据,一张分区表一张全表,使用分区表进行groupby执行得不到count,使用普通表可以,怎么指定分区表不实用分区union all走全表查询呢。


TiDB 的分区表和非分区表在使用 GROUP BY 时是有一些区别的。在分区表上使用 GROUP BY 时,需要指定分区列,否则会出现类似您遇到的问题,即无法正确地统计分区表中的数据。下面是一个示例 SQL 语句,可以在分区表上正确地统计数据:
SELECT partition_column, COUNT(*) FROM partitioned_table GROUP BY partition_column;
其中,partition_column 是分区列的名称,partitioned_table 是分区表的名称。这个语句会对分区表进行全表扫描,但是只会统计每个分区的数据,而不是整个表的数据。如果您想要在非分区表上使用 GROUP BY,可以直接使用类似下面的 SQL 语句:
SELECT column, COUNT(*) FROM table GROUP BY column;
其中,column 是非分区表中的列名,table 是非分区表的名称。这个语句会对整个表进行全表扫描,并统计每个分组的数据。如果您想要在分区表上使用全表分组查询,可以使用 UNION ALL 将每个分区的结果合并起来,例如:
SELECT partition_column, COUNT(*) FROM partitioned_table WHERE partition_column = 'partition1' GROUP BY partition_column
UNION ALL
SELECT partition_column, COUNT(*) FROM partitioned_table WHERE partition_column = 'partition2' GROUP BY partition_column
UNION ALL
...
这个语句会对每个分区进行单独的 GROUP BY,然后将结果合并起来。但是这种方法需要手动指定每个分区的名称,比较麻烦。因此,建议您在分区表上使用第一种方法,即指定分区列进行 GROUP BY。
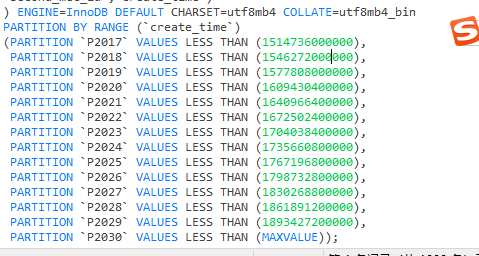
我使用的是按创建时间进行分区,但是我的groupby字段用不到分区字段,
使用union all 进行合并的话会oom,最终结果集数量有5000w左右
分区表的内部实现,就是每个分区都有一个独立的tableid。即你说的每个分区都是一个表,把它们union all在一起。
这个实现是没有办法改变的。
不过,你这个问题不是没法解决,关键的问题在于分区表的hashagg在tidb执行了没有下推到tiflash。
所以我觉得你可以考虑尝试mpp。mpp应该会直接算出一个结果给你而不必通过tidb hashagg。
https://docs.pingcap.com/zh/tidb/stable/use-tiflash-mpp-mode#控制是否选择-mpp-模式
你可以尝试在session级别开启mpp看看是否有提升。
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。