TIDB6.5 在单线程下写入一条数据50ms,在多线程写入时平均每条需要400ms。有哪位大佬知道怎么优化?
怎么个写入法,表结构发一下,有写热点吗?

id怎么生成的,自增吗?
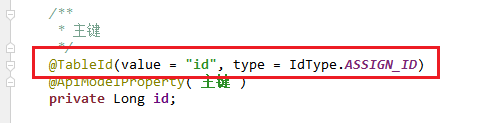
使用的mybatisplus的雪花算法id。
dashboard的流量可视化界面看下有没有写热点,
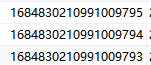
这种的肯定是回到同一个region里面的
怎么让它写在不同的region呢?或者我怎么优化呢?
直接不要应用侧写这个字段了,改成auto_random让系统自动生成
修改雪花算法,按照量级来翻转高位的,这样才能满足region 打散的要求。
auto_random 的原理也是如此。
什么叫高位呢,解释一下:
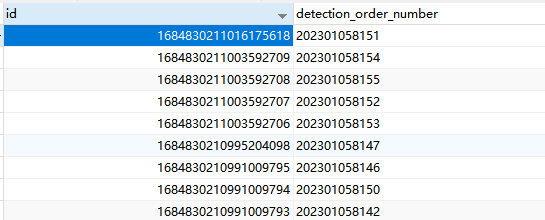
1684830211003592709
靠左边的,就是高位了,auto_random(X) 有个参数位的设定,就是翻转高位的个数。
设定为 auto_random(5),则 [16848]30211003592709
被 [] 起来的数字,会被高位翻转,符合region 的处理要求,,并且还要支持不重复… ![]()
![]()
![]()
是不是有热点问题,在一个region上,用雪花算法, 不用自增试下
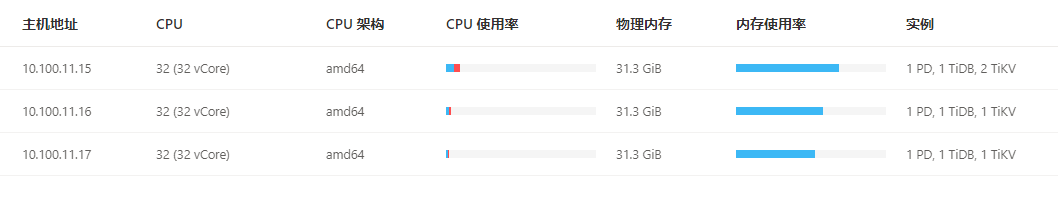
既然内存 cpu负载都很低,我觉得可能是硬盘性能问题,请检查下硬盘使用率是否到100%了
这个具体怎么改呢?求助
建新表的时候自增长的列,把关键字auto_increament改为auto_random就行了,其他保持不变。具体也可以搜一搜官网
CREATE TABLE ta (id BIGINT AUTO_INCREMENT , b VARCHAR(255), PRIMARY KEY (id));
SET tidb_allow_remove_auto_inc=1;
ALTER TABLE ta MODIFY COLUMN id BIGINT AUTO_RANDOM(5);
学习了
并发起了多少个?机器的io监控下呢,另外你15机器上的两台tikv是挂载在同一个磁盘下,还是不同的磁盘下?

除了写入热点的消除,强烈建议刷一遍下面这个视频:
这个视频思路非常清晰:
先是通过 Average Idle Connection Duration可以判断是数据库内慢,还是数据库外慢。
然后可以通过数据库内sql的拆解,整个sql的执行可以拆解为 get token,execute, compile,parse。
高并发的时候没有plan cache ,compile阶段的占比会比较高。
然后引入如何使用plan cache。外加各种连接池如何设置参数。
非常实用。
我的数据库使用的机械磁盘,不是SSD