【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】
【复现路径】做过哪些操作出现的问题
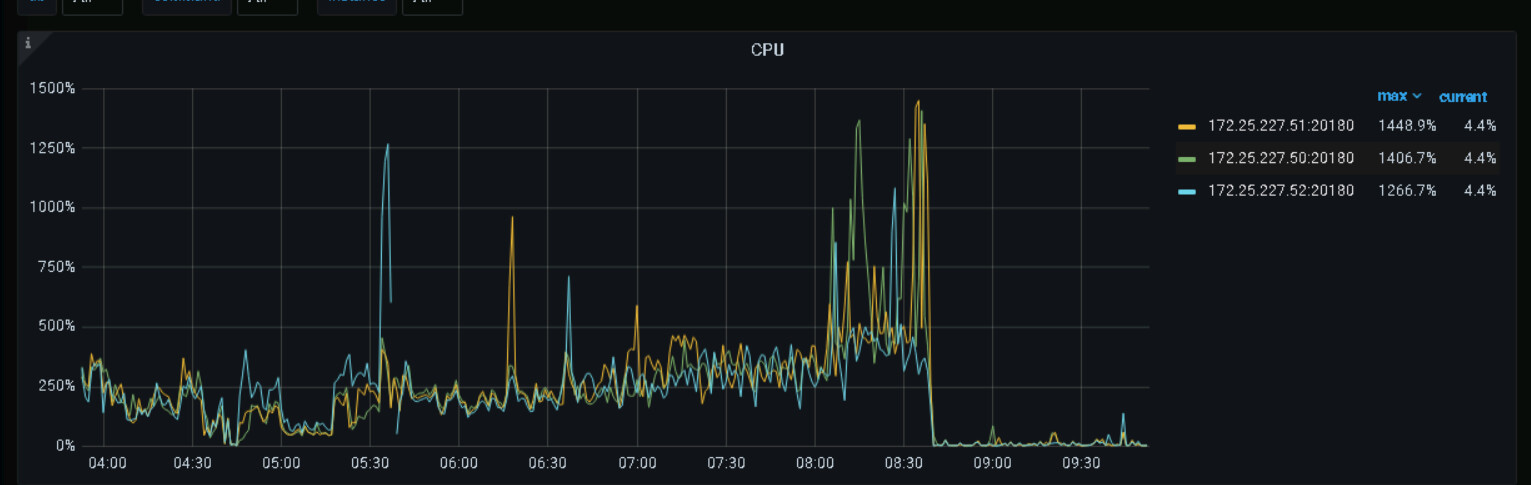
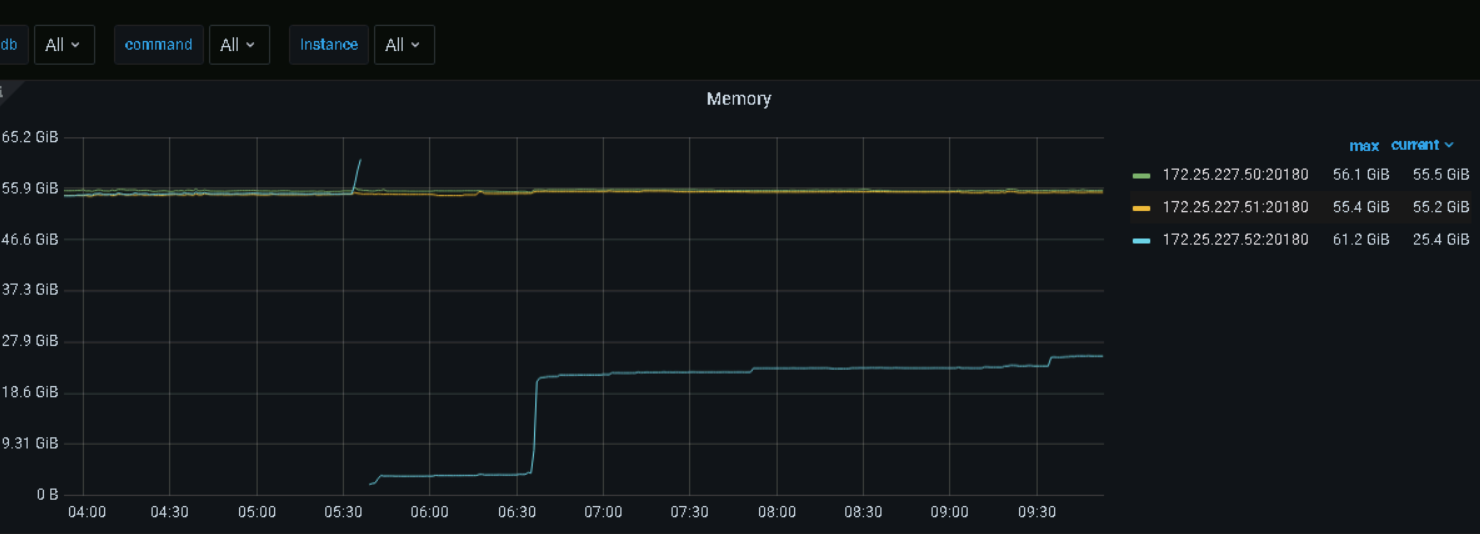
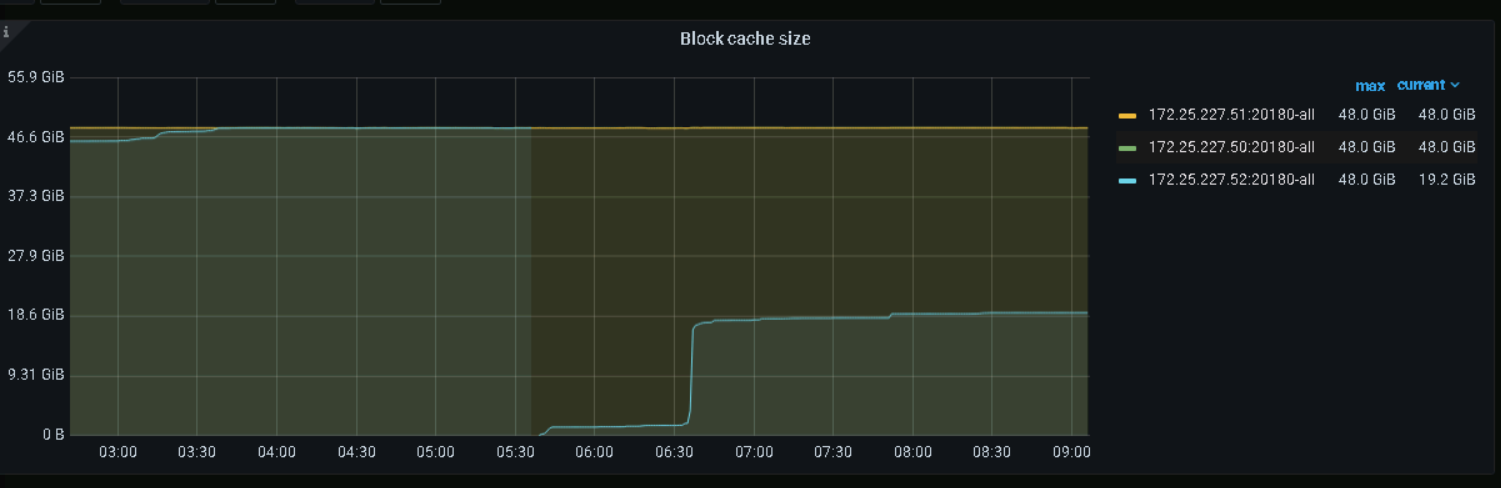
tikv的内存和cpu在凌晨突然飙升,导致一台tikvoom重启了,通过dashbord面板查看改时间段并没有什么大sql在执行,其他的一些监控指标也没有异常,想问下大家在这种情况下如何定位的(blockcache设置的是48G,我看官网说6.6以后这个弃用了)
【遇到的问题:问题现象及影响】
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
tidb日志中有 EXPENSIVE_QUERY么?
你要查慢sql,或者楼上说的EXPENSIVE关键字。你可以自己看看语句分析相关说明,查不到sql的情况是有可能的
没有这个
![]() 还有一种情况,这个语句在INFORMATION_SCHEMA.CLUSTER_PROCESSLIST里。
还有一种情况,这个语句在INFORMATION_SCHEMA.CLUSTER_PROCESSLIST里。
慢查询只会记录执行完成的sql。
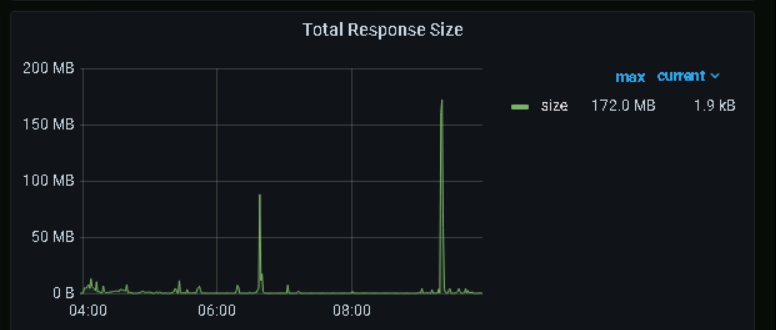
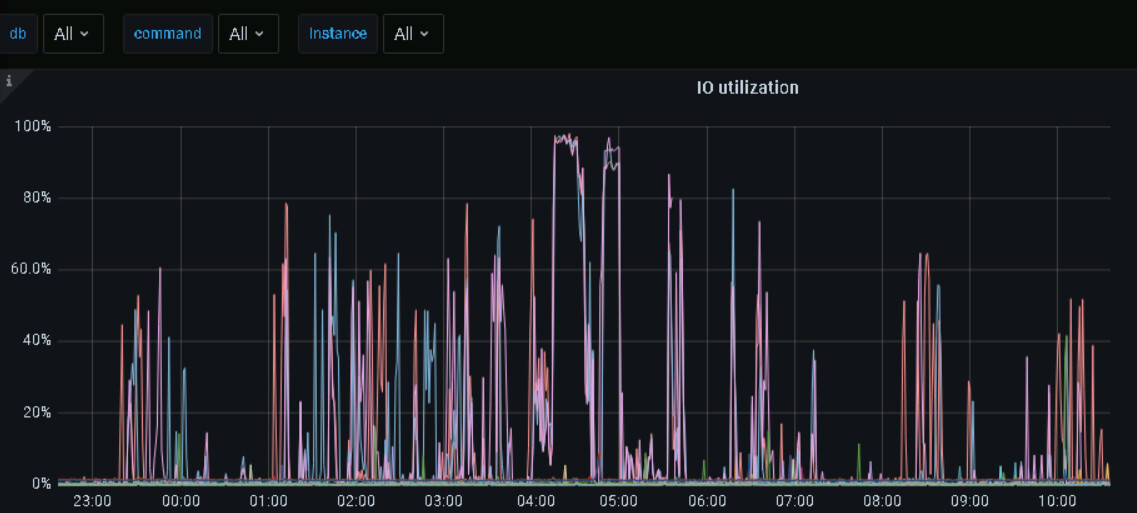
看这个图不像OOM吧,感觉是重启了,OOM应该是一条斜线,看监控直接就是直上直下的。
慢查询会记录未完成的sql,之前oom,我都是到慢查询看执行计划的,sql页还有是否执行成功的显示,显示的是0

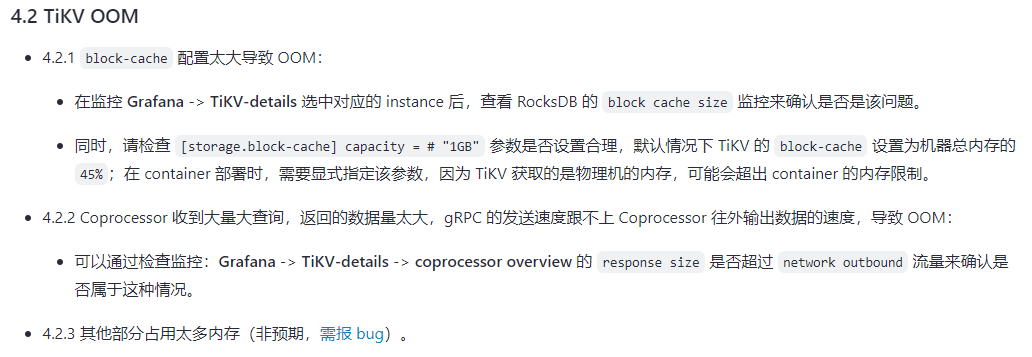
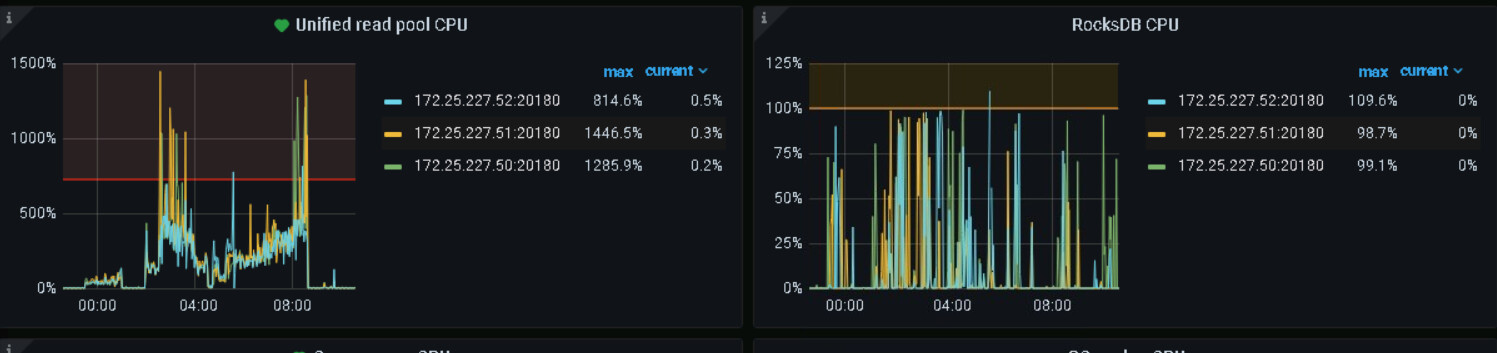
64G内存,设置了48G,有点高。我一般设置60%。
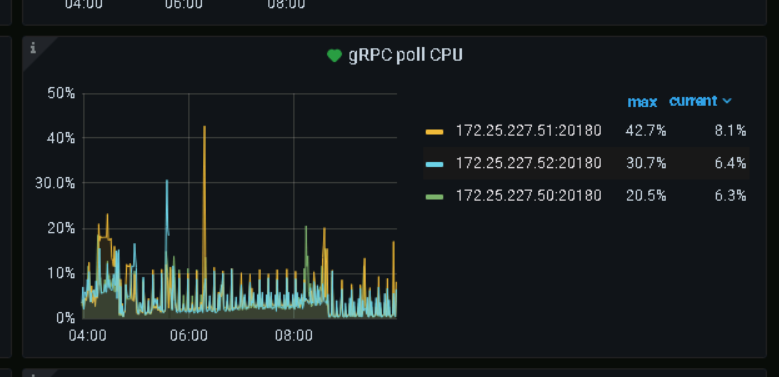
看监控,tikv内存是突然增高的,最好能查到原因,但是根据其他监控,好像也没啥异常,你发的这几个监控,在5.30的时候都不是很高。
调查下,那个时间段有没有定时任务再跑,比如备份,跑批;
业务在前一天有没有升级,变更
我之前设置的是40G,但是一天之后看监控的block-cache-size就超出了40g达到48G左右
SHOW config WHERE NAME LIKE ‘storage.block-cache.capacity’
这个参数设置的多少?
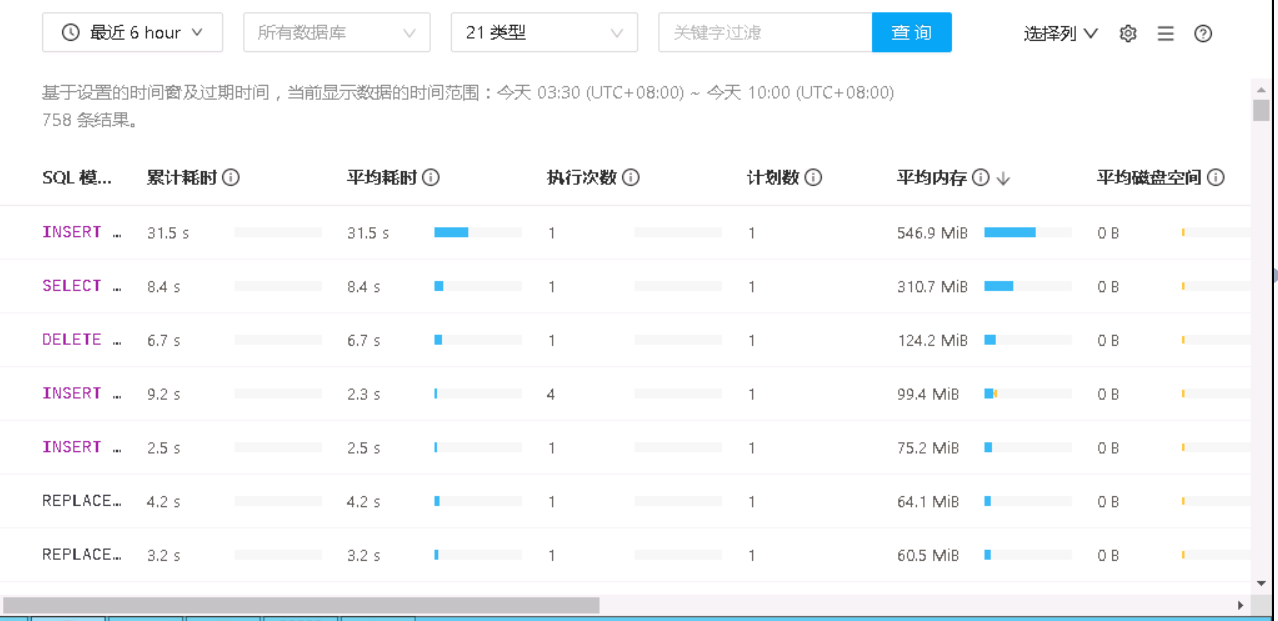
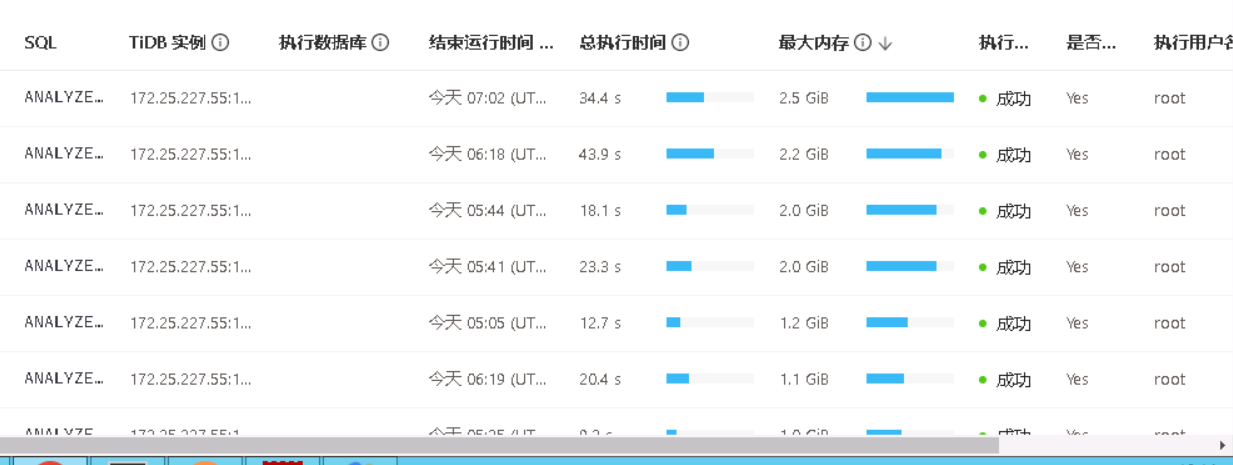
你这图里排第一个的sql单个500m 执行十几个 这不就是原因吗 oom是大家用缓存 先把最大的sql优化了
原来设置的是48G,刚刚改成了38G,不过好像与这个无关,只是之前看到哪篇帖子说设置成内存的75%左右的。
tikv没有混部的话,这个值设置为机器内存的45%就行,这个用来缓存数据的,光它占75%的话,oom很正常。。。
好的谢谢,可能我之前看错了。
大佬真的超级无敌
tidb的调参数最好别调 默认就很好了