【 TiDB 使用环境】生产环境
【 TiDB 版本】5.4
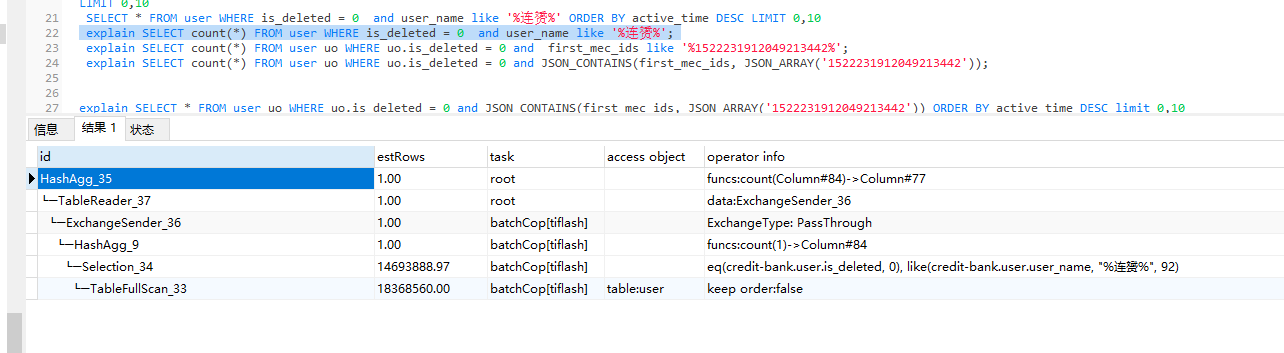
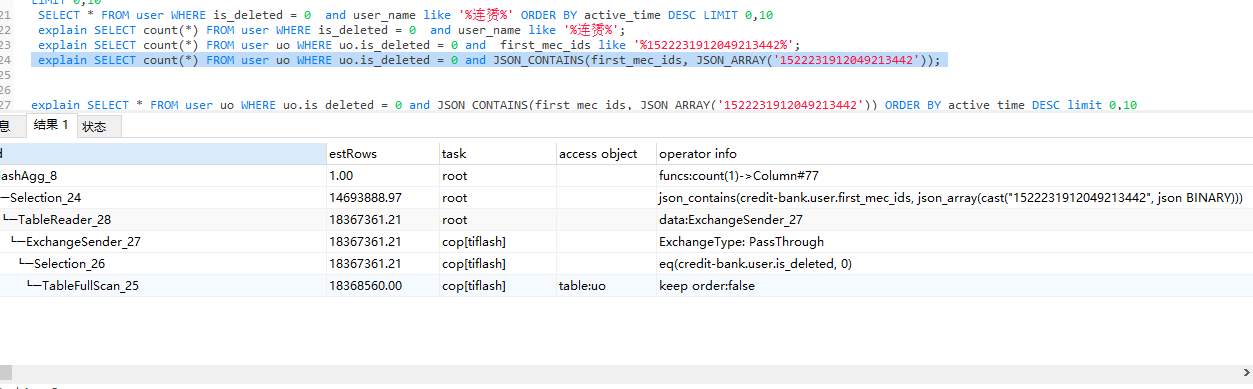
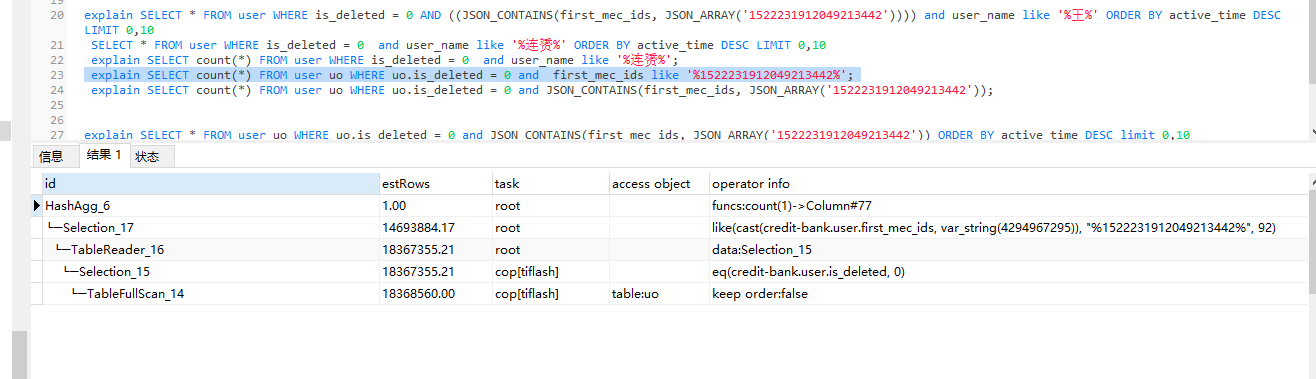
同一张表1800w数据,执行count(*) 操作 like模糊查询只需要0.2秒,json数据查询需要10秒,看执行计划,使用like比使用JSON查询的效率还要高一点,请教各位大神,这种需要怎么优化?
json函数是数据库中最慢的函数了,你用代表着每行数据都要执行下json函数,肯定比你直接查全表慢。。。
jason_contains 和 json_array 这两个函数都不被 tiflash 支持下推,这导致太多无用的数据被返回给 tidb-server 做进一步处理
我觉得可行的办法是增加新的 where 条件,降低中间结果集
我把json转成varchar类型,用like是不是会好一些,like的内容是唯一的
如果直接把字段转成varchar类型呢
https://docs.pingcap.com/zh/tidb/stable/generated-columns#生成列
tidb版本低了,5.4没有太好的办法。如果是7.1,常用的json查询节点,可以考虑使用生成列。
https://docs.pingcap.com/zh/tidb/stable/sql-statement-create-index#多值索引
如果节点内有多个值,还可以建立多值索引。
能升级就准备考虑升级吧。
1 个赞
JSON 生成列索引是个很不错的功能,我们生产环境使用了这个特性,对JSON 的查询过滤效率很高,业务方很满意响应速度,还是非常推荐使用的
索引是否合适呢
like肯定快,扫描字符串包含就返回成功,函数还要解析json文件
like会好一点,一个不需要json函数解析字段了,第二个like是可以下推的。
但json存数据库我一直都不理解,为啥业务不能直接把json解析了,把关键的字段直接存在表里呢?你要真的需要存很多json字段,直接用mongo不是更好?所谓的生成列不就是把json解析出来,把关键字段存表里然后建个索引,这个工作为啥要在数据库里做,业务层面做了不是更好。。
可以转成varchar吧
建议不要用json,非得模糊查询用单个like尽量走索引,如果大数据了模糊搜索最好用es吧
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。