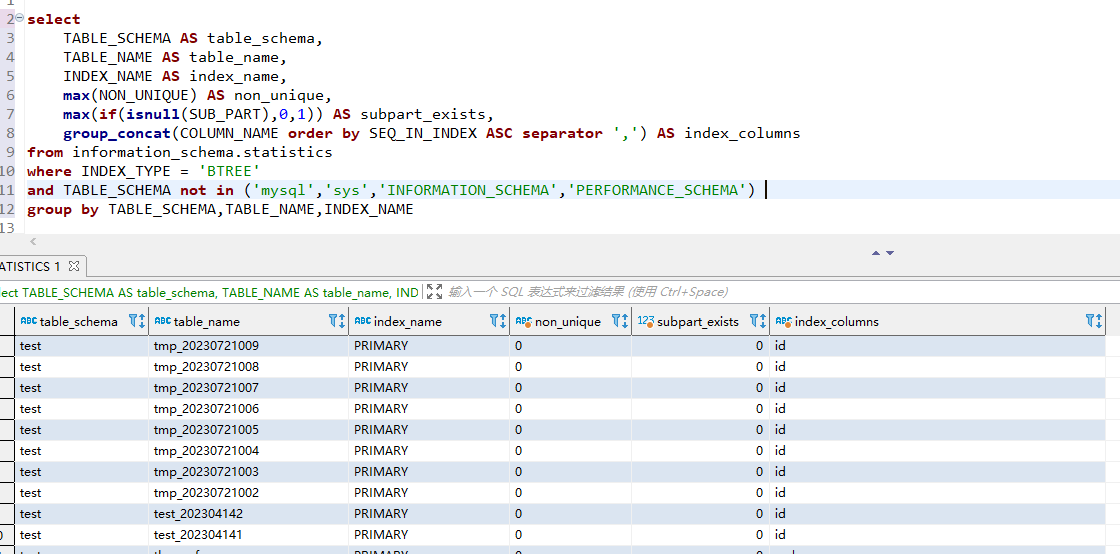
我比葫芦画瓢,参照mysql.sys.schema_redundant_indexes的查询,可以过滤一些冗余索引,未使用过的索引目前好像无法查询,另外优化冗余索引时删除一个索引时,可以先改名处理,避免有查询使用了force index,如果有查询报错,还可以再改名原来的名字,而不需要重新创建索引:
SELECT
redundant_keys.table_schema,
redundant_keys.table_name,
redundant_keys.KEY_NAME AS redundant_index_name,
redundant_keys.index_columns AS redundant_index_columns,
redundant_keys.non_unique AS redundant_index_non_unique,
dominant_keys.KEY_NAME AS dominant_index_name,
dominant_keys.index_columns AS dominant_index_columns,
dominant_keys.non_unique AS dominant_index_non_unique,
IF(redundant_keys.subpart_exists OR dominant_keys.subpart_exists, 1 ,0) AS subpart_exists,
CONCAT(
'ALTER TABLE `', redundant_keys.table_schema, '`.`', redundant_keys.table_name, '` DROP INDEX `', redundant_keys.KEY_NAME, '`'
) AS sql_drop_index
FROM
(SELECT
TABLE_SCHEMA,
TABLE_NAME,
KEY_NAME,
MAX(NON_UNIQUE) AS non_unique,
MAX(IF(SUB_PART IS NULL, 0, 1)) AS subpart_exists,
GROUP_CONCAT(COLUMN_NAME ORDER BY SEQ_IN_INDEX) AS index_columns
FROM INFORMATION_SCHEMA.TIDB_INDEXES
WHERE
TABLE_SCHEMA NOT IN ('mysql', 'sys', 'INFORMATION_SCHEMA', 'PERFORMANCE_SCHEMA', 'METRICS_SCHEMA')
GROUP BY
TABLE_SCHEMA, TABLE_NAME, KEY_NAME) AS redundant_keys
INNER JOIN
(SELECT
TABLE_SCHEMA,
TABLE_NAME,
KEY_NAME,
MAX(NON_UNIQUE) AS non_unique,
MAX(IF(SUB_PART IS NULL, 0, 1)) AS subpart_exists,
GROUP_CONCAT(COLUMN_NAME ORDER BY SEQ_IN_INDEX) AS index_columns
FROM INFORMATION_SCHEMA.TIDB_INDEXES
WHERE
TABLE_SCHEMA NOT IN ('mysql', 'sys', 'INFORMATION_SCHEMA', 'PERFORMANCE_SCHEMA', 'METRICS_SCHEMA')
GROUP BY
TABLE_SCHEMA, TABLE_NAME, KEY_NAME
) AS dominant_keys
USING (TABLE_SCHEMA, TABLE_NAME)
WHERE
redundant_keys.KEY_NAME != dominant_keys.KEY_NAME
AND (
(
/* Identical columns */
(redundant_keys.index_columns = dominant_keys.index_columns)
AND (
(redundant_keys.non_unique > dominant_keys.non_unique)
OR (redundant_keys.non_unique = dominant_keys.non_unique
AND IF(redundant_keys.KEY_NAME='PRIMARY', '', redundant_keys.KEY_NAME) > IF(dominant_keys.KEY_NAME='PRIMARY', '', dominant_keys.KEY_NAME)
)
)
)
OR
(
/* Non-unique prefix columns */
LOCATE(CONCAT(redundant_keys.index_columns, ','), dominant_keys.index_columns) = 1
AND redundant_keys.non_unique = 1
)
OR
(
/* Unique prefix columns */
LOCATE(CONCAT(dominant_keys.index_columns, ','), redundant_keys.index_columns) = 1
AND dominant_keys.non_unique = 0
)
);