【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】
【复现路径】在Dashboard上操作导出最近30分慢查触发OOM
【遇到的问题:问题现象及影响】
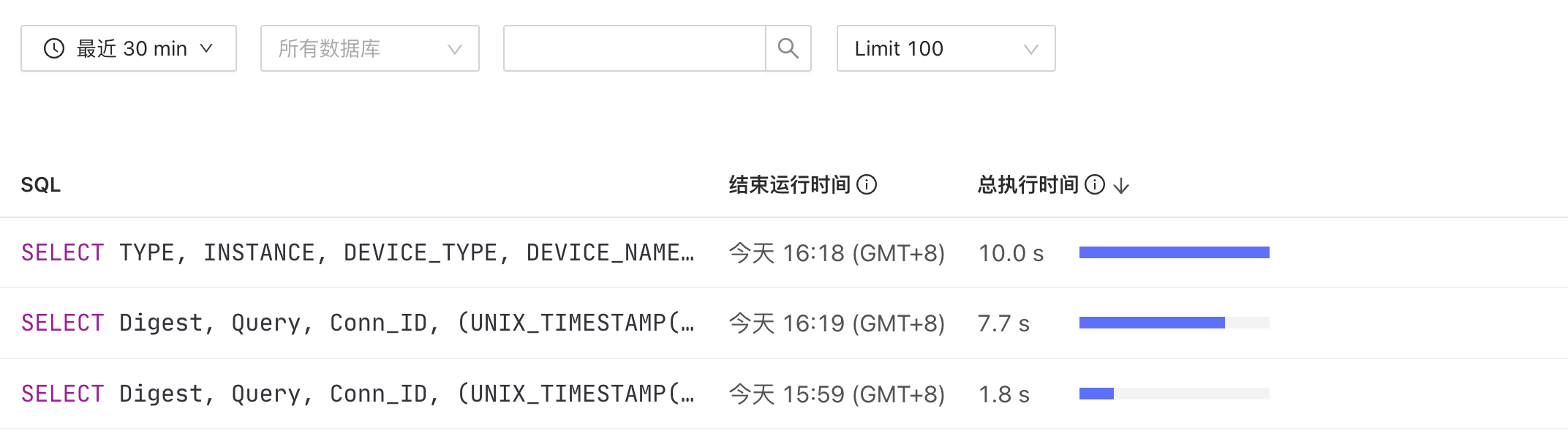
由于Dashboard中的慢查询功能只能一个一个的打开,所以就导出到本地,一个一个的优化。
选择了时间段,最近30分钟,导出没有反应。
查看监控
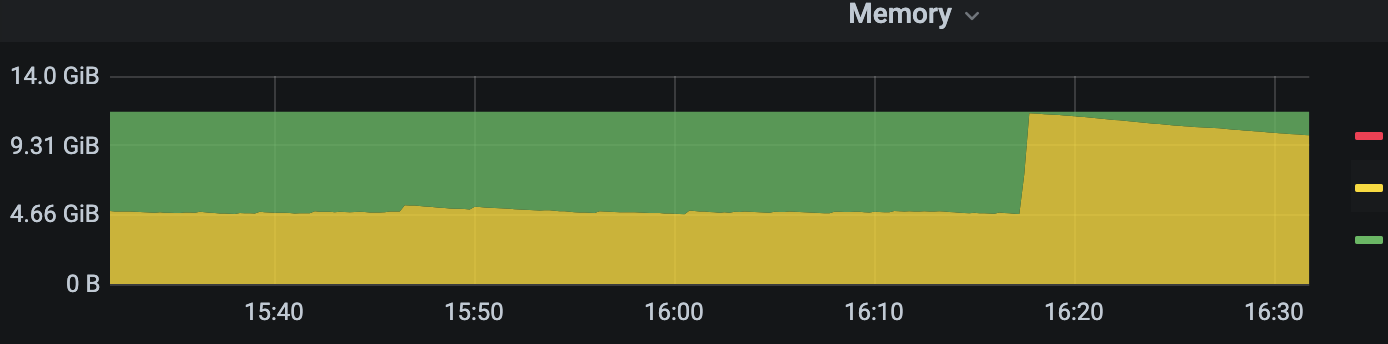

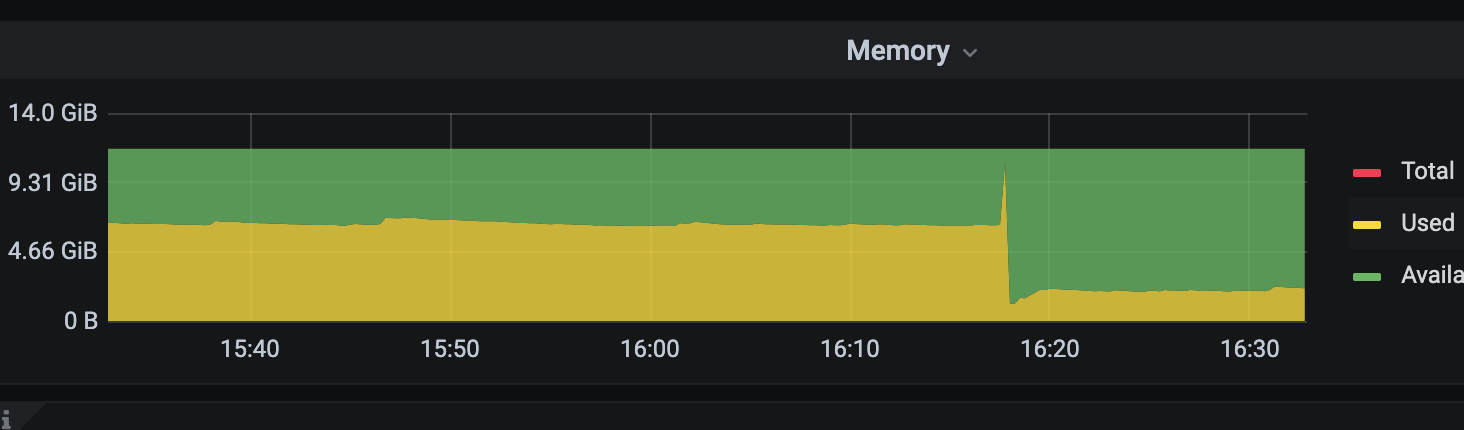
其中两台发生了OOM,幸好还剩一台
查看其中一台OOM的实例
The 10 SQLs with the most time usage for OOM analysis
SQL 0:
cost_time: 1.376497381s
conn_id: 206183
user: dashboard_user
table_ids: [4611686018427387951]
txn_start_ts: 443004339273596931
mem_max: 25276 Bytes (24.7 KB)
sql: SELECT Digest, Query, INSTANCE, DB, Conn_ID, Succ, (UNIX_TIMESTAMP(Time) + 0E0) AS timestamp, Query_time, Parse_time, Compile_time, Rewrite_time, Preproc_subqueries_time, Optimize_time, Wait_TS, Cop_time, LockKeys_time, Write_sql_response_total, Exec_retry_time, Mem_max, Disk_max, Txn_start_ts, Prev_stmt, Plan, Is_internal, Index_names, Stats, Backoff_types, User, Host, Process_time, Wait_time, Backoff_time, Get_commit_ts_time, Local_latch_wait_time, Resolve_lock_time, Prewrite_time, Wait_prewrite_binlog_time, Commit_time, Commit_backoff_time, Cop_proc_avg, Cop_proc_p90, Cop_proc_max, Cop_wait_avg, Cop_wait_p90, Cop_wait_max, Write_keys, Write_size, Prewrite_region, Txn_retry, Request_count, Process_keys, Total_keys, Cop_proc_addr, Cop_wait_addr, Rocksdb_delete_skipped_count, Rocksdb_key_skipped_count, Rocksdb_block_cache_hit_count, Rocksdb_block_read_count, Rocksdb_block_read_byte FROM `INFORMATION_SCHEMA`.`CLUSTER_SLOW_QUERY` WHERE Time BETWEEN FROM_UNIXTIME(?) AND FROM_UNIXTIME(?) ORDER BY Query_time DESC LIMIT 100
~
为什么这个查询危害那么大?

