【 TiDB 使用环境】生产环境
【 TiDB 版本】 v5.4.0
【复现路径】
【遇到的问题:问题现象及影响】 tikv的一个节点很早前down掉,无法重启,没有及时处理,目前tidb还能使用
【资源配置】
【附件:截图/日志/监控】



------------ 分割线----------------------------------------------------------------------------------------------------
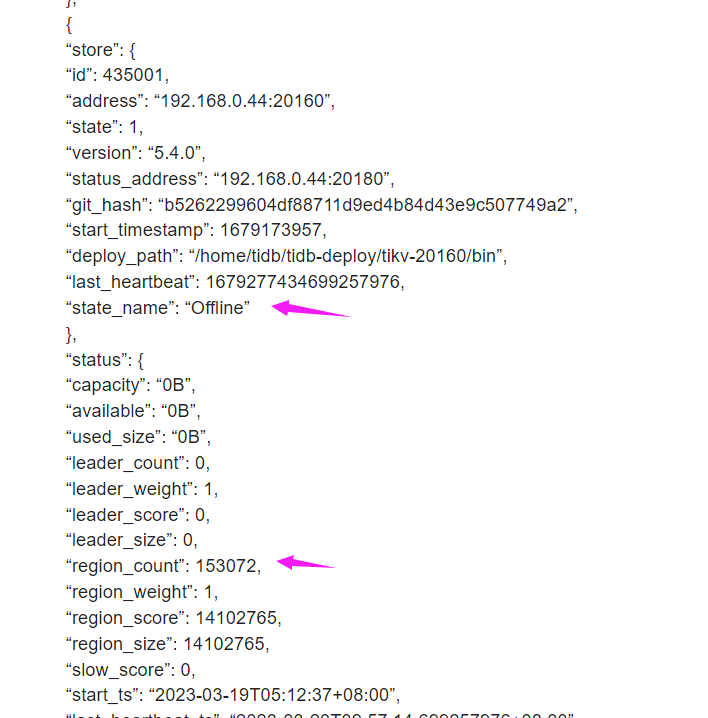
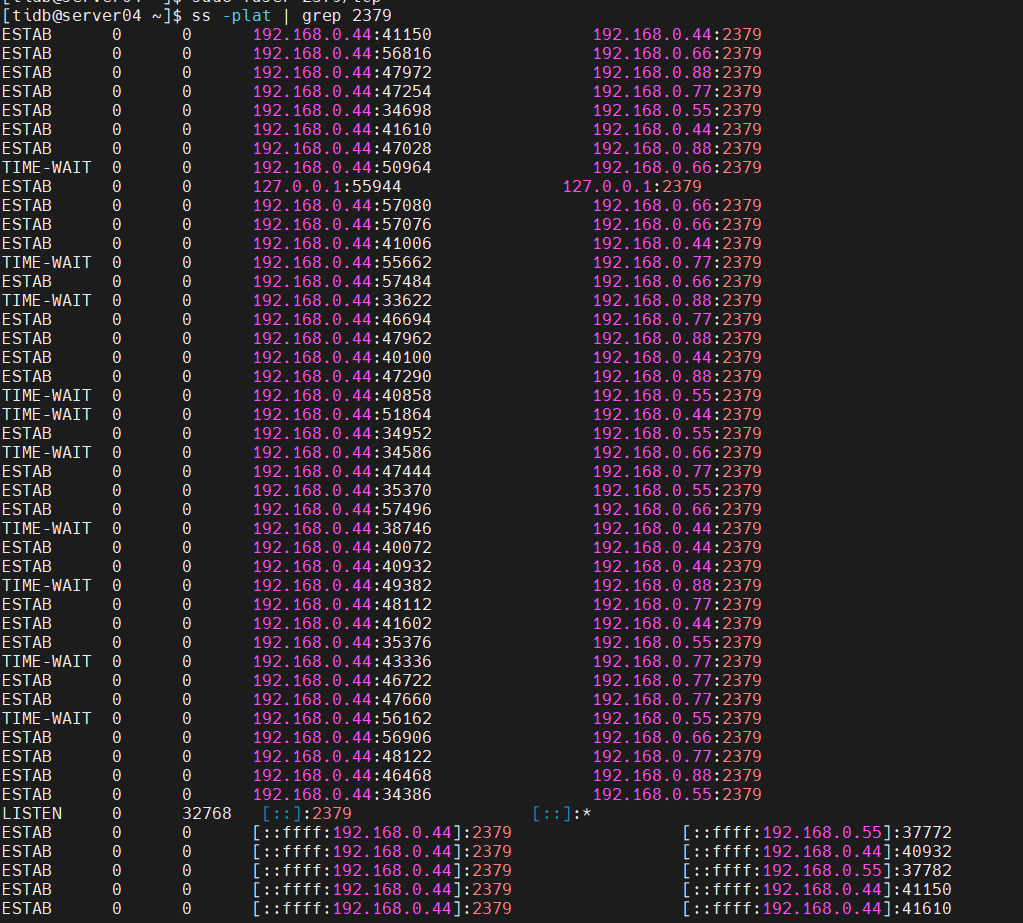
在7-20号,进行缩容操作之后,该tikv节点一直处于pending offline状态,一直没有转为Tombstone,运行命令: tiup ctl:v5.4.0 pd store -u http://192.168.0.44:2379 查看了以下,信息如下,有大神能给点指点嘛?本小白还是第一次接触tidb,之前集群也不是自己搭起来的,临时接手运维,会不会是其他tikv节点的容量不足,导致无法迁移region呢?非常感谢各位大佬的意见。
{
“count”: 5,
“stores”: [
{
“store”: {
“id”: 54569104,
“address”: “192.168.0.77:20160”,
“version”: “5.4.0”,
“status_address”: “192.168.0.77:20180”,
“git_hash”: “b5262299604df88711d9ed4b84d43e9c507749a2”,
“start_timestamp”: 1688780698,
“deploy_path”: “/home/tidb/tidb-deploy/tikv-20160/bin”,
“last_heartbeat”: 1689855671702792664,
“state_name”: “Up”
},
“status”: {
“capacity”: “3.581TiB”,
“available”: “504GiB”,
“used_size”: “2.846TiB”,
“leader_count”: 63632,
“leader_weight”: 1,
“leader_score”: 63632,
“leader_size”: 5944706,
“region_count”: 151913,
“region_weight”: 1,
“region_score”: 25440050.958300572,
“region_size”: 14185296,
“slow_score”: 1,
“start_ts”: “2023-07-08T09:44:58+08:00”,
“last_heartbeat_ts”: “2023-07-20T20:21:11.702792664+08:00”,
“uptime”: “298h36m13.702792664s”
}
},
{
“store”: {
“id”: 54570781,
“address”: “192.168.0.88:20160”,
“version”: “5.4.0”,
“status_address”: “192.168.0.88:20180”,
“git_hash”: “b5262299604df88711d9ed4b84d43e9c507749a2”,
“start_timestamp”: 1688780748,
“deploy_path”: “/home/tidb/tidb-deploy/tikv-20160/bin”,
“last_heartbeat”: 1689855676107451361,
“state_name”: “Up”
},
“status”: {
“capacity”: “3.581TiB”,
“available”: “518GiB”,
“used_size”: “2.832TiB”,
“leader_count”: 63629,
“leader_weight”: 1,
“leader_score”: 63629,
“leader_size”: 5854555,
“region_count”: 152668,
“region_weight”: 1,
“region_score”: 25096307.24491983,
“region_size”: 14087928,
“slow_score”: 1,
“start_ts”: “2023-07-08T09:45:48+08:00”,
“last_heartbeat_ts”: “2023-07-20T20:21:16.107451361+08:00”,
“uptime”: “298h35m28.107451361s”
}
},
{
“store”: {
“id”: 435001,
“address”: “192.168.0.44:20160”,
“state”: 1,
“version”: “5.4.0”,
“status_address”: “192.168.0.44:20180”,
“git_hash”: “b5262299604df88711d9ed4b84d43e9c507749a2”,
“start_timestamp”: 1679173957,
“deploy_path”: “/home/tidb/tidb-deploy/tikv-20160/bin”,
“last_heartbeat”: 1679277434699257976,
“state_name”: “Offline”
},
“status”: {
“capacity”: “0B”,
“available”: “0B”,
“used_size”: “0B”,
“leader_count”: 0,
“leader_weight”: 1,
“leader_score”: 0,
“leader_size”: 0,
“region_count”: 153072,
“region_weight”: 1,
“region_score”: 14102765,
“region_size”: 14102765,
“slow_score”: 0,
“start_ts”: “2023-03-19T05:12:37+08:00”,
“last_heartbeat_ts”: “2023-03-20T09:57:14.699257976+08:00”,
“uptime”: “28h44m37.699257976s”
}
},
{
“store”: {
“id”: 441829,
“address”: “192.168.0.55:20160”,
“version”: “5.4.0”,
“status_address”: “192.168.0.55:20180”,
“git_hash”: “b5262299604df88711d9ed4b84d43e9c507749a2”,
“start_timestamp”: 1689145062,
“deploy_path”: “/home/tidb/tidb-deploy/tikv-20160/bin”,
“last_heartbeat”: 1689855666887176027,
“state_name”: “Up”
},
“status”: {
“capacity”: “3.581TiB”,
“available”: “490.6GiB”,
“used_size”: “2.853TiB”,
“leader_count”: 63626,
“leader_weight”: 1,
“leader_score”: 63626,
“leader_size”: 5817870,
“region_count”: 153919,
“region_weight”: 1,
“region_score”: 25474172.258108985,
“region_size”: 14090076,
“slow_score”: 1,
“start_ts”: “2023-07-12T14:57:42+08:00”,
“last_heartbeat_ts”: “2023-07-20T20:21:06.887176027+08:00”,
“uptime”: “197h23m24.887176027s”
}
},
{
“store”: {
“id”: 443528,
“address”: “192.168.0.66:20160”,
“version”: “5.4.0”,
“status_address”: “192.168.0.66:20180”,
“git_hash”: “b5262299604df88711d9ed4b84d43e9c507749a2”,
“start_timestamp”: 1689144954,
“deploy_path”: “/home/tidb/tidb-deploy/tikv-20160/bin”,
“last_heartbeat”: 1689855668354806741,
“state_name”: “Up”
},
“status”: {
“capacity”: “3.581TiB”,
“available”: “477.2GiB”,
“used_size”: “2.865TiB”,
“leader_count”: 63636,
“leader_weight”: 1,
“leader_score”: 63636,
“leader_size”: 5884687,
“region_count”: 152082,
“region_weight”: 1,
“region_score”: 25589442.485215813,
“region_size”: 14047393,
“slow_score”: 1,
“start_ts”: “2023-07-12T14:55:54+08:00”,
“last_heartbeat_ts”: “2023-07-20T20:21:08.354806741+08:00”,
“uptime”: “197h25m14.354806741s”
}
}
]
}