【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】3.0.12
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
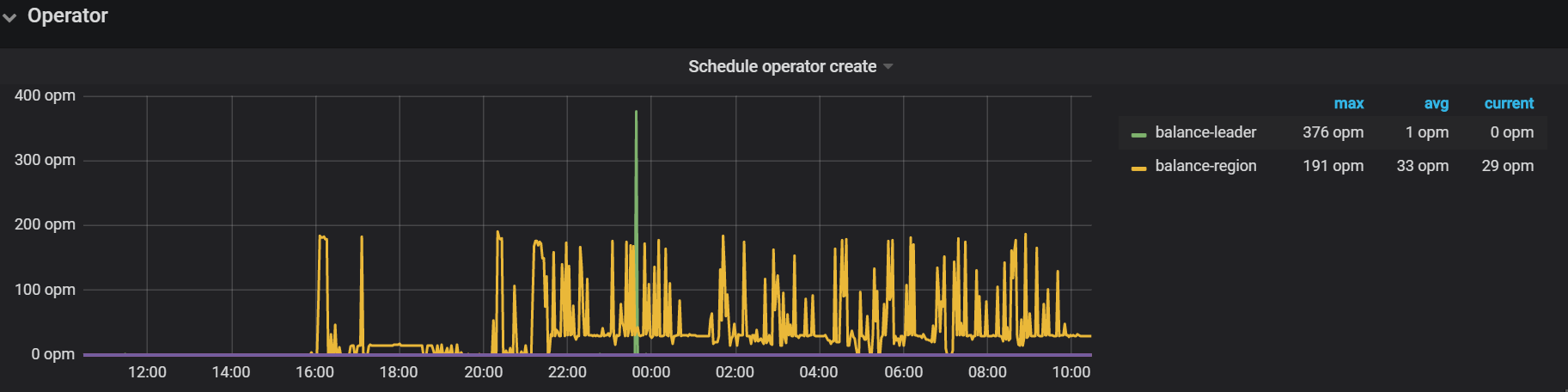
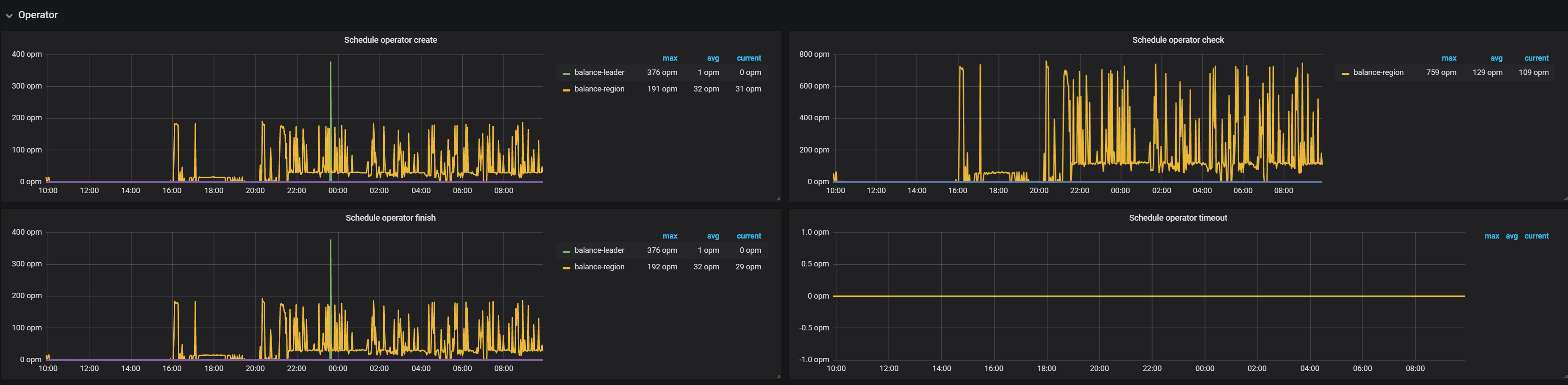
从昨天下午开始,一直在balance region,insert语句大量慢查询,大部分时间在prewrite阶段。
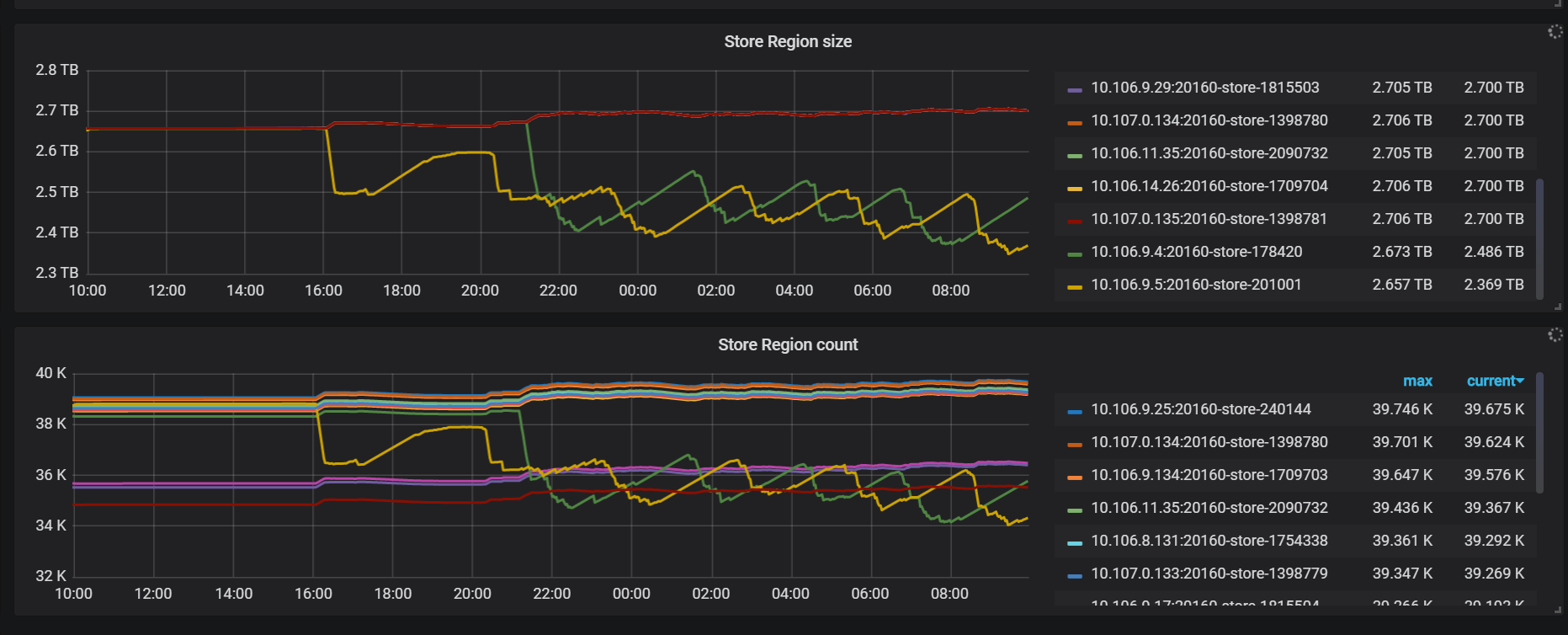
region score分数一直在波动,为什么分数一直在变呢?之前一直没有过这种情况,是因为使用空间大于60%了吗?

一直在平衡region,一天了也没完,这两个节点程锯齿状波动,上去再下来
导致现在有大量的insert慢查询
pd参数如下:
» config show
{
“replication”: {
“location-labels”: “”,
“max-replicas”: 3,
“strictly-match-label”: “false”
},
“schedule”: {
“disable-location-replacement”: “false”,
“disable-make-up-replica”: “false”,
“disable-namespace-relocation”: “false”,
“disable-raft-learner”: “false”,
“disable-remove-down-replica”: “false”,
“disable-remove-extra-replica”: “false”,
“disable-replace-offline-replica”: “false”,
“enable-one-way-merge”: “false”,
“high-space-ratio”: 0.6,
“hot-region-cache-hits-threshold”: 3,
“hot-region-schedule-limit”: 4,
“leader-schedule-limit”: 4,
“low-space-ratio”: 0.8,
“max-merge-region-keys”: 200000,
“max-merge-region-size”: 20,
“max-pending-peer-count”: 16,
“max-snapshot-count”: 3,
“max-store-down-time”: “30m0s”,
“merge-schedule-limit”: 8,
“patrol-region-interval”: “100ms”,
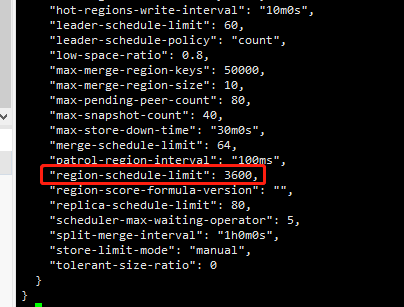
“region-schedule-limit”: 8,
“replica-schedule-limit”: 8,
“scheduler-max-waiting-operator”: 3,
“schedulers-v2”: [
{
“args”: null,
“disable”: false,
“type”: “balance-region”
},
{
“args”: null,
“disable”: false,
“type”: “balance-leader”
},
{
“args”: null,
“disable”: true,
“type”: “hot-region”
},
{
“args”: null,
“disable”: false,
“type”: “label”
}
],
“split-merge-interval”: “1h0m0s”,
“store-balance-rate”: 15,
“tolerant-size-ratio”: 5
}
}
»
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】