【 TiDB 使用环境】生产环境
【 TiDB 版本】5.4.0
【 TiDB 配置】8台数据库8c16G集群
TiDB模糊查询时间过慢 数据量一亿,请教各位大神,这种查询还有优化空间吗?
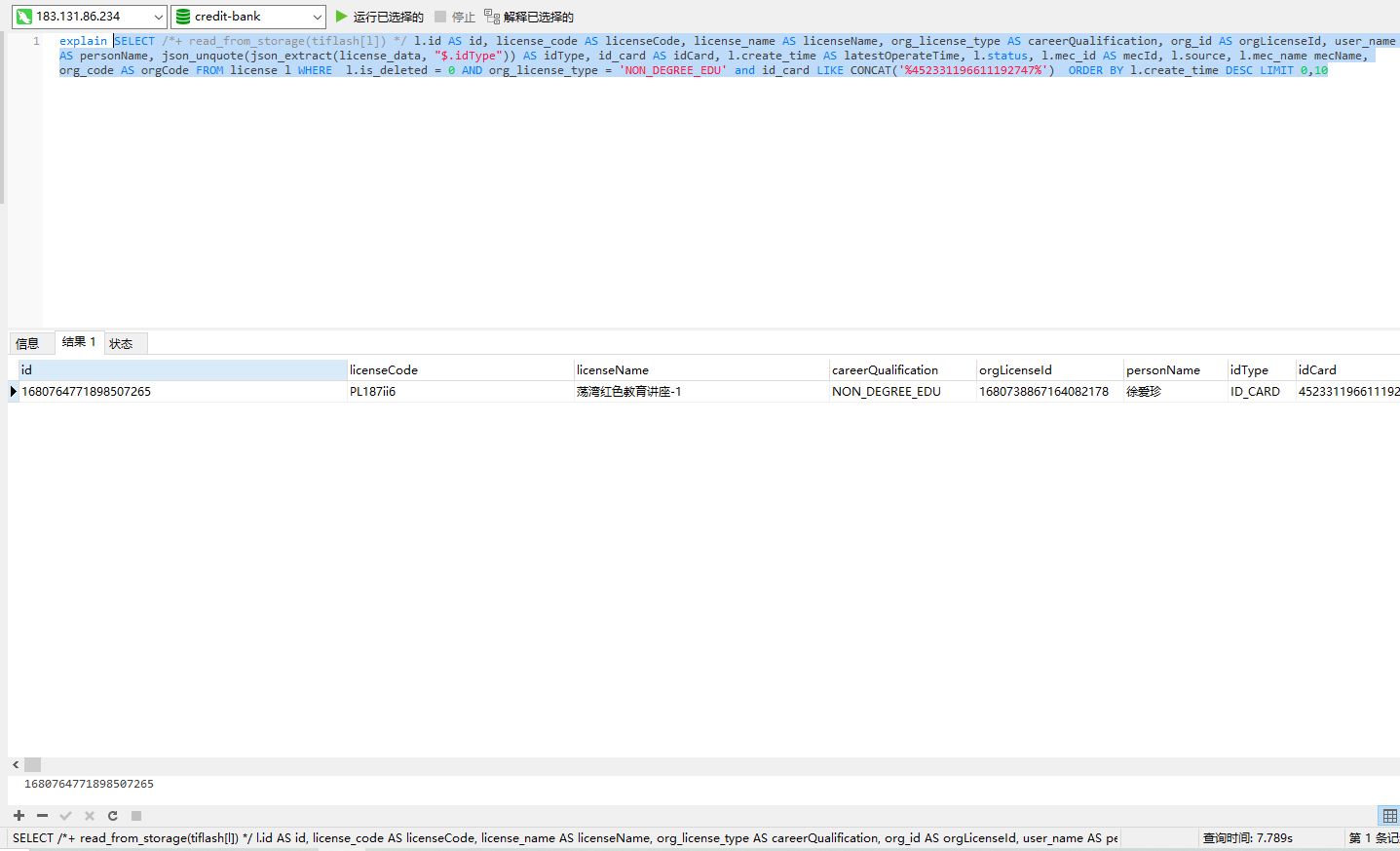

需要执行计划啊,兄弟。 ![]()
不然看结果是不多,不知道原因在哪里。
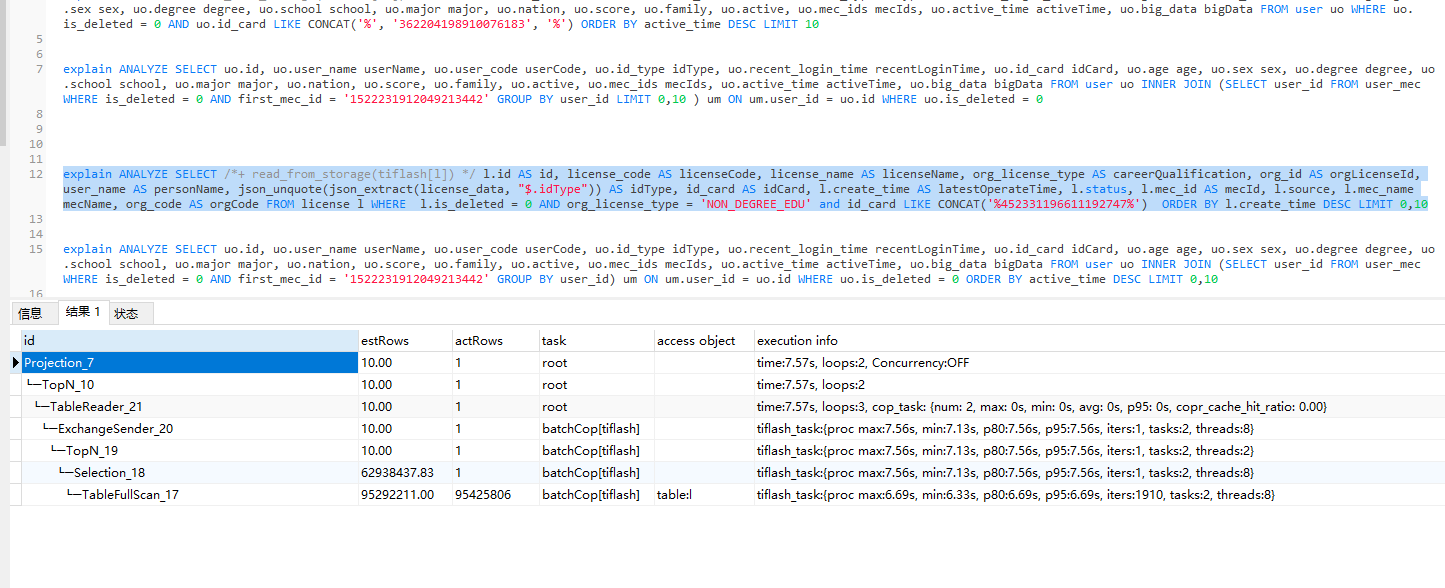
上次好像看到过了,我的建议是,还想提速,只有在所有你查询的字段,过滤的字段,包括排序的字段上建一个联合索引吧。。。这样不用回表,才能更快
上次按照您提的建议已经加上去了组合索引,现在列表不加查询条件很快。
但是,我这个sql里面可能会有很多的like查询条件,而且like是不走索引的吧
tiflash查询你要继续优化,如果不止一台tiflash可以试试MPP模式。
你的执行计划里面看到了ExchangeSender ,可已经已经用上MPP模式了。
https://docs.pingcap.com/zh/tidb/stable/use-tiflash-mpp-mode
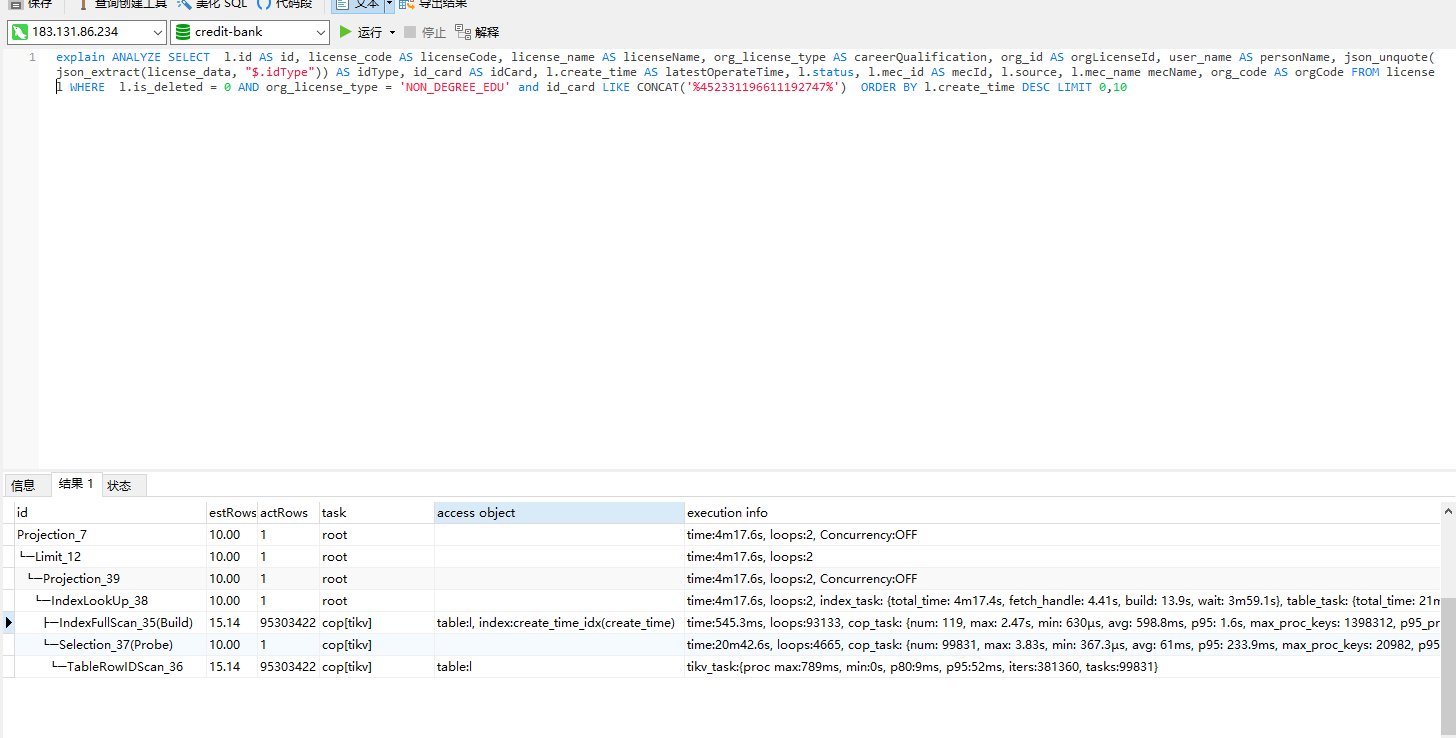
其实我感觉你这个查询,tikv可能更适合,特别是id_card这个字段应该是一个特别适合索引的字段。
但查询并没有走,原因可能是没有索引,或者%idcard%,前面这个%造成的。
如果可能,idcard有索引+idcard%这样添加条件,应该能利用到索引。
其他的条件如果能快速的锁定一个小范围值的,都可以加索引试试看。
CREATE TABLE license (
id varchar(20) NOT NULL,
create_time bigint(20) DEFAULT NULL,
update_time bigint(20) DEFAULT NULL,
is_deleted int(11) DEFAULT ‘0’,
user_id varchar(100) DEFAULT NULL COMMENT ‘用户id’,
zlb_user_id varchar(100) DEFAULT NULL COMMENT ‘浙里办id’,
ins_id varchar(20) DEFAULT NULL,
org_id varchar(20) DEFAULT NULL COMMENT ‘成果目录id’,
license_type varchar(255) DEFAULT NULL COMMENT ‘成果类型’,
license_data json DEFAULT NULL COMMENT ‘成果字段详情’,
org_license_type varchar(30) DEFAULT NULL COMMENT ‘成果org_license细分’,
course_id varchar(20) DEFAULT NULL COMMENT ‘课程id’,
course_name varchar(100) DEFAULT NULL COMMENT ‘课程名称’,
tran_time bigint(0) DEFAULT ‘0’ COMMENT ‘转化时间’,
apply_file json DEFAULT NULL COMMENT ‘申请文件’,
mec_id varchar(50) DEFAULT NULL COMMENT ‘机构id’,
status varchar(20) DEFAULT NULL COMMENT ‘审核状态’,
tran_status varchar(30) DEFAULT NULL COMMENT ‘转换状态’,
first_mec_id varchar(30) DEFAULT NULL COMMENT ‘一级机构id’,
second_mec_id varchar(30) DEFAULT NULL COMMENT ‘二级机构id’,
license_code varchar(50) DEFAULT NULL COMMENT ‘成果代码’,
hash_value varchar(256) DEFAULT NULL COMMENT ‘区块链hash’,
source varchar(30) DEFAULT NULL,
id_card varchar(50) DEFAULT NULL COMMENT ‘身份证’,
credit_hour varchar(30) DEFAULT NULL,
user_name varchar(50) DEFAULT NULL,
user_code varchar(30) DEFAULT NULL,
org_code varchar(50) DEFAULT NULL,
license_name varchar(100) DEFAULT NULL,
career_qualification_data json DEFAULT NULL COMMENT ‘证书,课程,专业信息’,
operation_phone varchar(50) DEFAULT NULL COMMENT ‘操作人手机号’,
operation_name varchar(50) DEFAULT NULL COMMENT ‘操作人姓名’,
mec_name varchar(50) DEFAULT NULL COMMENT ‘机构名称’,
is_old tinyint(3) DEFAULT ‘0’ COMMENT ‘是否老系统’,
old_id varchar(50) DEFAULT NULL COMMENT ‘老系统id’,
KEY zlbuserid_idx (zlb_user_id),
PRIMARY KEY (id) /*T![clustered_index] NONCLUSTERED */,
KEY id_card_idx (id_card),
KEY create_time_idx (create_time),
KEY idx_delete_type_mec_create (is_deleted,org_license_type,mec_id,create_time),
KEY idx_delete_type_first_mec_create (is_deleted,org_license_type,first_mec_id,create_time),
KEY idx_deleted_orgId (is_deleted,org_id),
KEY idx_delete_type_second_mec_create (is_deleted,org_license_type,second_mec_id,create_time)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
在被模糊查询的字段上创建前缀索引
前缀索引对%idCard%模糊查询有用吗?
like '%…%'这种确实是走不了索引的,like '…%'这种还行,tidb是不支持全文索引的, id_card这个字段确定需要like '%…%'这种查询条件吗?
1 个赞
是的,业务上要求的需要,还有另外类似user_name的也需要 '%…%'这种查询
%…%这种like无法优化,可以看看表达式索引,有没有可能把查询条件转换成某个表达式,然后创建索引
CREATE INDEX | PingCAP 文档中心
我们这种like %%的都是走es的
实在不行,把数据同步到Elasticsearch上试试吧。。。tidb本身对这种sql没啥优化的空间了
好的吧,我跟我们业务部门沟通下,不行了只能上es了
看你这个查询好像不需要用like吧
Tidb单纯使用 Like 会导致查询到有歧义的结果或满足搜索条件的结果无法返回,从Tidb索引角度无法更加优化了。更好的方式是通过其他方式,使用全文检索,比如ES