3副本tikv如果挂掉一个节点,剩下的2个会是强同步吗?
这个时候需要在补充一个节点…
剩下的2个节点就是强同步的,因为 raft 协议本身就是强一致性的
这样的话意味着3个tikv,挂掉一个tikv。变成强一致,过一段时间再挂掉一个tikv,无法服务。
然后用单个tikv执行unsafe recover,大概率不会丢数据?
会的,多数派原则,剩余2个节点,只有1个节点同步不满足多数
副本没丢,为啥要用 unsafe recover? 补节点,会补齐副本的,
如果副本都丢了,那就需要 unsafe recover
3个,down一个,变2副本,过一段时间,再down一个。就只剩1副本了。这种情况下unsafe recover
会丢还是不会丢?
数据写不进去了也读不出来了,有啥丢不丢的?
丢的概念是什么?是服务停止导致的丢失,还是数据写进入后的问题,导致的丢失? 还是什么?
3个,down一个,剩下两个强一致,可以继续对外提供服务,想补齐副本只需要新增节点就会自动补齐
3个,down一个,变2副本,过一段时间,再down一个,这时集群直接停止对外服务了,无法访问,想对外提供服务,必须起码再新增一个节点,补成2副本,也不需要unsafe recover
3个,一次性down两个,这时是无法对外服务,且极有可能丢失数据的,这时单单加节点无法自动补充副本了,需要unsafe recover
这2种情况,差别在过了一段时间,所以这个过一段时间是多大一段时间?为什么最终结果都是只剩下1个副本,一个不需要unsafe recover 一个需要unsafe recover?
假如说:
3副本变成了2副本,刚变成2副本的一瞬间,可能其中1副本还没跟上raftlog。这时候进度靠前的副本又down了,只剩下没跟上的了。这时候靠副本unsafe recover是不是就丢了一些?
我说的down就是彻底消失了,不是还能起来的down。
3个节点,根据大多数原则,其中可能有2个或三个节点数据准,如果一次性挂两个,有可能挂的都是准的,留下的刚好是不准的,就会丢失数据,如果一次挂一个,这时假如挂的也是准的那个,剩下一个准,一个不准,这时需要将准的那个先同步给不准的那个,如果同步完成,这时再挂,那还是剩下1个也是准的,但是如果同步没完成,挂了准的那个,就废了,但是理论上同步应该很快的,而且一次挂一个,然后紧接着又挂一个,中间时间如果连同步都没来得及的话,那基本也就相当于同时挂了两个了。。。
说再多不如撸一把 ![]()
应该是别管挂掉的时间先后,都得用unsafe recover吧。只是哪一种方式丢数据的可能性更小。
3个节点,你如果先挂了一个节点,过了5年,你再挂一个节点,不会丢失数据的啊。。。剩下2个节点的数据肯定是一致的。。。你所谓的3个挂了一个,又挂了一个,主要看这中间的时间,是否剩下的两个节点已经完成了同步数据。
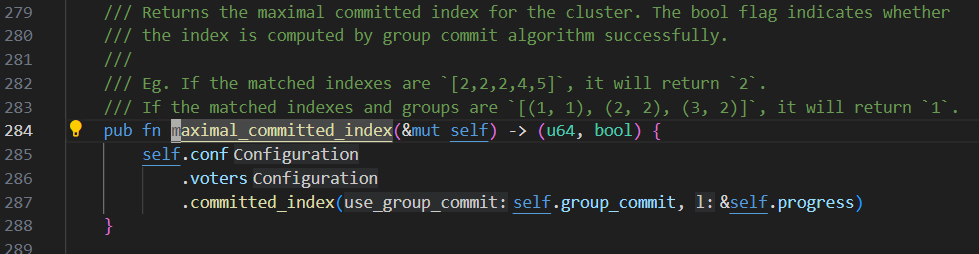
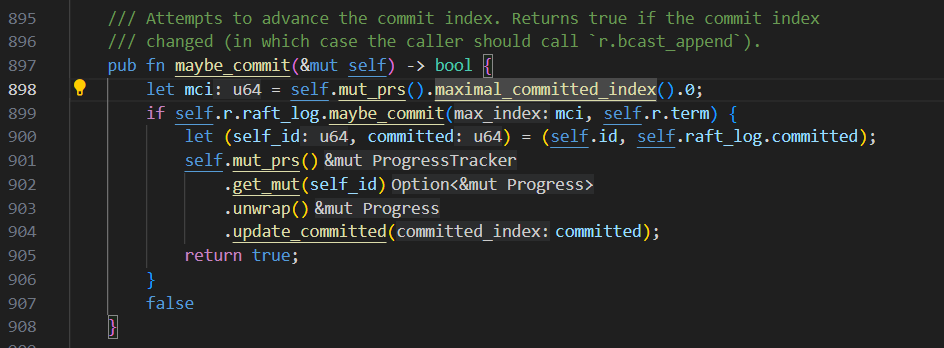
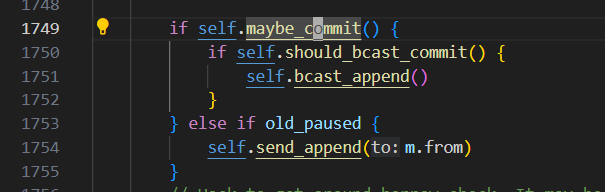
看代码,大概是这样的:
A\B\C 3个副本,挂掉C以后,剩下AB两副本
假设A选为了leader,再进行propose的时候,如果B的进度总也跟不上,那commit index的始终无法向前推进。
相当于写不进去。
如果B进度差太多,A可能给B发快照。
所以,如果3副本,挂掉了C,剩下2副本,没法保证A\B的数据是一致的。
如果这个region能写入数据,那就代表A\B是一致的了。
也就是说:A\B\C一直正常工作,如果C挂了。集群所有的region都写入了一条数据,都能保证提交成功。那代表A\B是强一致的了。这种情况下,B再挂掉,用unsafe recover就不会丢数据。
但是,没法保证集群所有region在2副本的时候都写入了一条数据,也有可能挂掉C后,A给B发送快照,B始终没应用成功,那B始终跟不上,那这个region始终是不可写的,A再挂掉,剩下进度跟不上的B去做unsaferecover,那数据就不是最新的了。
一个region在非常大的集群中占比很小,一个region不可写入,也不一定表就不可写入。所以没有办法知道A\B 2副本是不是一致了。
以上只是看了一小片代码,是不是还有其他逻辑能达到和我说的不一样的效果也不好说。
坐等其他人讲解讲解这一片逻辑。
5年不丢,4年丢不丢?3年呢?2年呢?1年呢?1个月呢?1天呢?这个时间多长算长?没有一个标志性事件标志这个集群可靠了,那就是不可靠 ![]() 。
。
只是时间越久丢数据的概率越低。概率为0的事情也是有可能发生的。
研究原理是为了更好的掌控,为了更好的应用,避开深坑,提供更好的实践路径和体验。
基于这个目标呢,肯定是需要设定场景的,空谈没太多意义
场景就是有一个集群,10+个 tikv, 2月份下线了一台tikv(运维人员没太多经验,直接销毁dokcer)
然后前几天又下线了一台tikv(直接销毁docker)
结果服务不可用了。
经过region过滤,发现有1000+region的2个副本在这2个上面。
经过unsafe recover,现在能正常提供服务,但是无法确定是否丢了数据。
所以抛出这个问题讨论下。
当然这个事儿肯定不是我干的 ![]() ,但是他就是发生了。
,但是他就是发生了。
所以说,这还是空谈吗? ![]()
至于中间这么久为什么没补上那个副本,我也不清楚,看store信息,region信息,就是这样的。
如果有场景,请在发帖时,就说明这些背景,避免无效的回答和猜测…
如果是生产环境,会放给小白去运维和处理么? 或者说数据如果很重要,公司也不敢这么操作吧?
另外对于整体的规划和使用方式,肯定是在上线之前就要做好的,包括运维和处理的流程和方案,不会等到发现问题了再去想办法解决吧?(你的客户或者用户等不了那么久…)
不过商业订阅用户例外,因为是 Vvvvvvvip 用户… ![]()
![]()
![]()
![]()
![]()