dba-kit
(张天师)
1
【 TiDB 使用环境】生产环境
【 TiDB 版本】v6.5.3
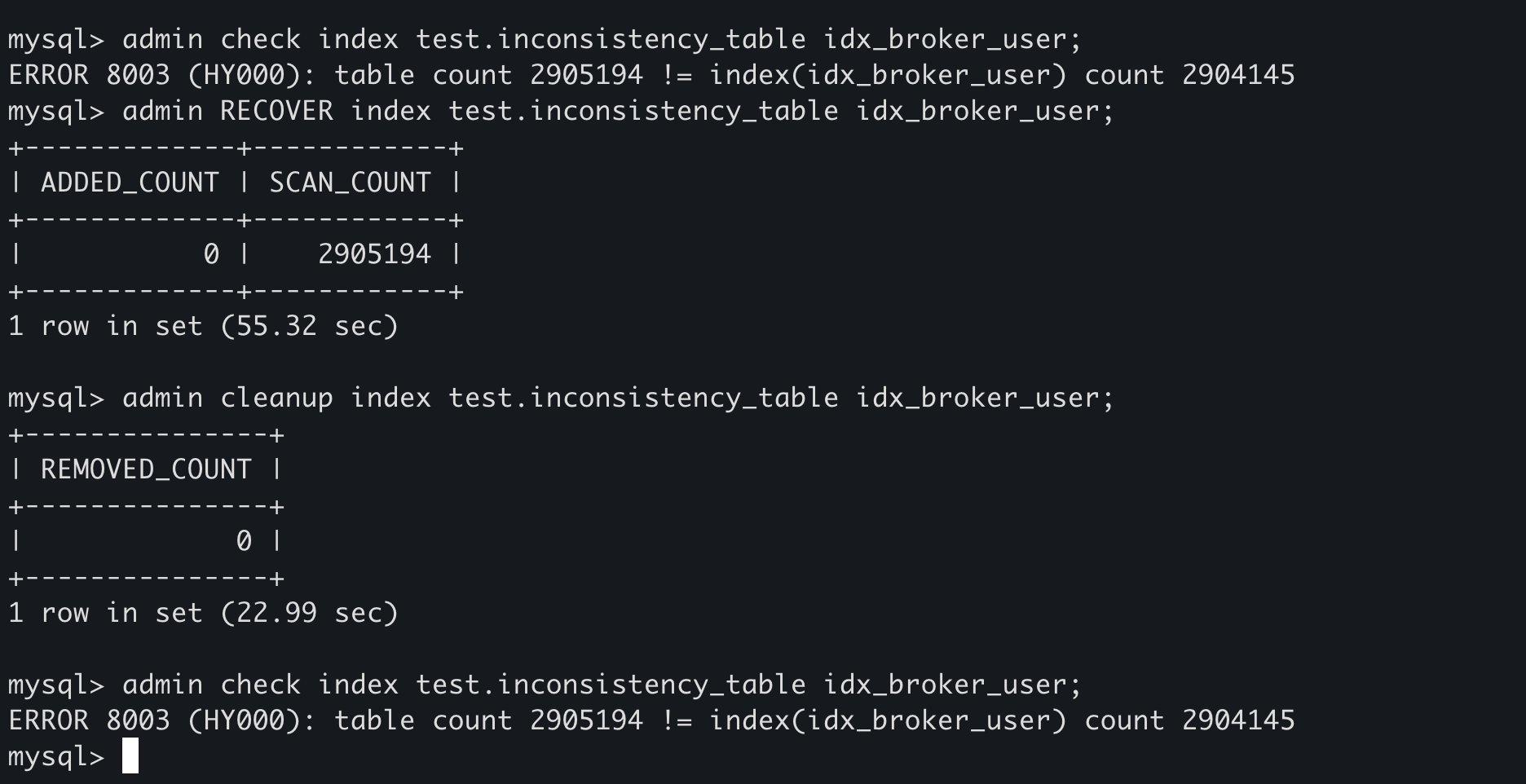
TiDB的索引和主表数据不一致,count和select * 返回条数不一致,通过ADMIN CHECK INDEX发现确实索引不一致
看到有两个命令ADMIN CLEANUP INDEX和ADMIN RECOVER INDEX来修复索引数据的,不知道有什么坑不?
https://docs.pingcap.com/zh/tidb/stable/sql-statement-admin-cleanup
https://docs.pingcap.com/zh/tidb/stable/sql-statement-admin-recover
dba-kit
(张天师)
2
这里的可能没办法正确处理数据,是仅仅指不一致的数据,还是说增量产生的索引数据也可能受影响呢?
PS: 我的场景发现索引多的数据都是历史数据,不会有修改。但是这个表正常还是有数据写入的,不知道能不能直接用CLEANUP来修复?
PPS: 怀疑可能还是搭建新集群从4.0升级到6.1时候,用tidb-lightning的物理模式多次导入时候遗留的一些问题
zhanggame1
(Ti D Ber G I13ecx U)
3
没操作过,看文档风险还是很大的,建议找维护时间先备份再做吧,有业务时候就别搞了。
关键的是这一句“ * 若你使用 TiDB 企业版,此时建议提交工单联系 PingCAP 支持工程师进行处理。” 可能要厂商来处理
aytrack
(Aytrack)
6
还有多次 lightning 重复导入,是使用了断点么?导入之后有没有用过 admin check table 检查呢, sync-diff 是不能检查出数据索引不一致的
dba-kit
(张天师)
7
这个确认了下,tidb-lightning在导入失败时候,确实可能会出现不一致的状态。
1 个赞
dba-kit
(张天师)
8
6.1到6.5是直接在线升级的,所以应该不是这个升级导致的。另外出现不一致的数据,都是很早之前的历史数据,也说明应该也是4.0导入6.1时候的报错导致的。
dba-kit
(张天师)
9
试了下, ADMIN CLEANUP/RECOVER INDEX执行后,并没有修复数据
1 个赞
knull
(Knull)
10
表有多大啊?如果不一致,是不是可以直接 drop index 然后再create index ?
dba-kit
(张天师)
11
出问题的表是个归档表,现在已经有100亿数据了,历史分区还都在SATA盘,重建索引的成本很高
1 个赞
有猫万事足
12
我也碰到过这个问题,当时数据还不多,也是lightning物理模式导入出错。
最后整个表重建了,蹲一个更好的解决方案。
dba-kit
(张天师)
关闭
14
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。