vincent
(Ti D Ber Ou5 Pvnh X)
1
【 TiDB 使用环境】生产环境
【 TiDB 版本】v5.4.0
【遇到的问题:问题现象及影响】
使用场景:我们生产环境使用tikv作为分布式事务存储引擎,对tikv的使用都是基于事务的机制。
集群拓扑:集群一共13 tikv节点,每个tikv节点有24个tikv server实例,隔离级别是host。
机器配置:每台机器 64c 256G 内存,每个tikv节点有24块ssd磁盘,每个tikv server实例单独使用一块SSD磁盘。
tikv数据:88TB
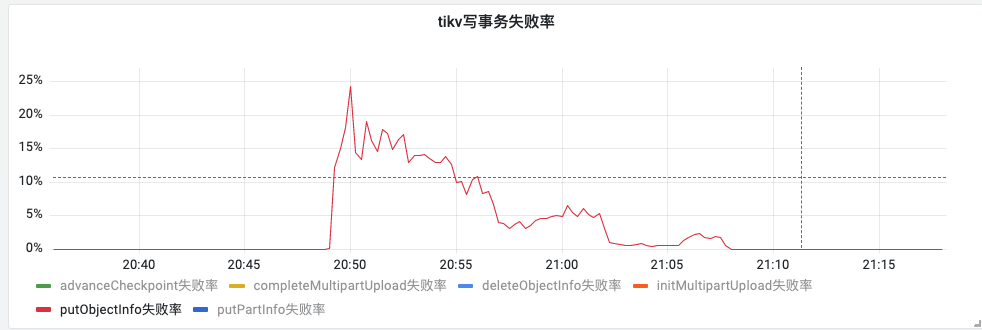
问题现象:某天晚上出现了1台tikv 节点宕机,发现受影响的请求占比25%,客户端存在重试行为,因为tikv回滚,请求成功率完全恢复花费了18分钟之久。故障时read qps:45k, 写qps:800
受影响的put请求占比:
事务回滚:
问题:
1、为什么一台tikv节点宕机会影响25%的请求呢?这个影响范围可能和tikv自身的均衡程度差距太大?
2、tikv节点宕机,影响了24个tikv-server实例,为什么事务的回滚机制需要耗费这么长时间?
3、有没有什么办法可以加速事务的回滚?
h5n1
(H5n1)
3
1、 tikv损坏的数量 并不能和业务端的影响做等比例的对比
2、tikv坏了理论不会影响tidb的事务回滚,tikv侧没有回滚一说,tikv 主机down了后会有Leader转移 ,再次期间tidb访问tikv 会有重试backoff,你看下overview → tiikv中 leader的监控。
vincent
(Ti D Ber Ou5 Pvnh X)
4
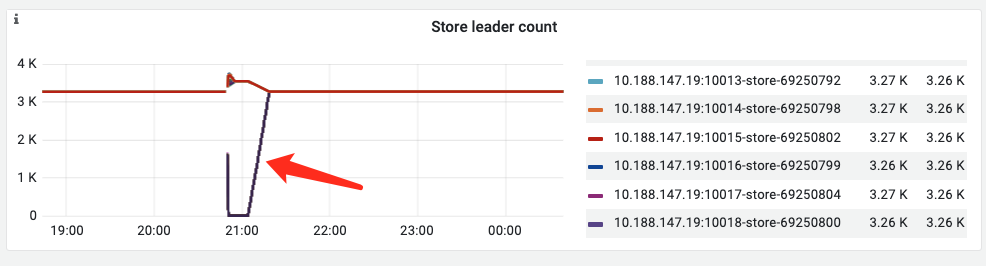
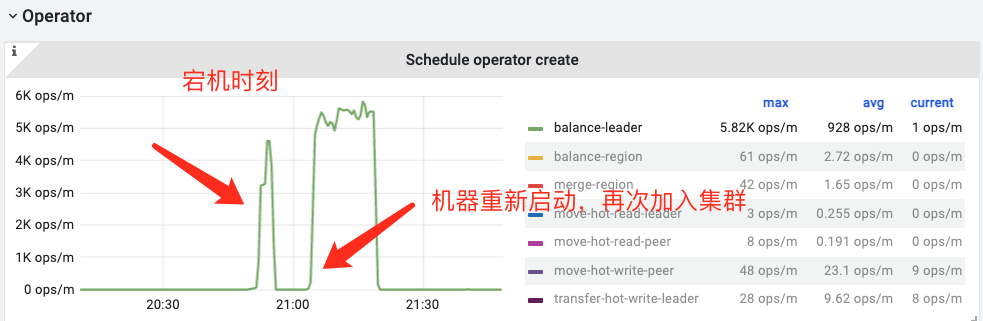
leader确实是转移了,但是转移后并没有立即恢复,而是一个缓慢的恢复过程。
leader转移:
可以看到机器重启之前,故障tikv store的leader数量已经变成0了,说明是切走了。
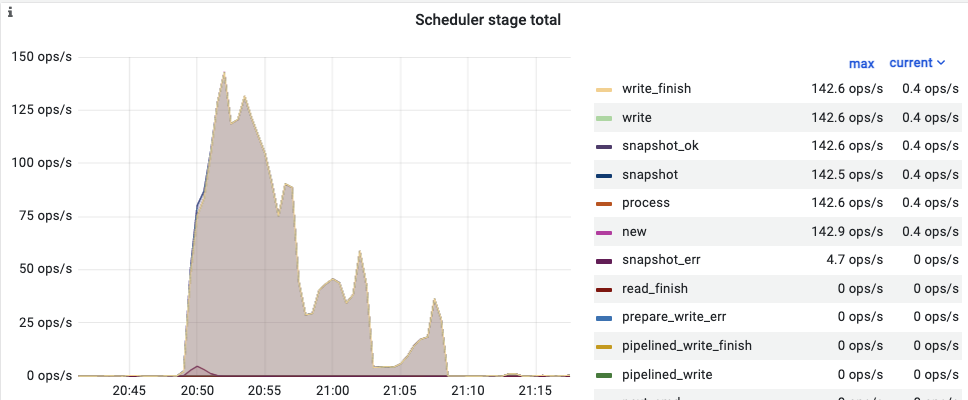
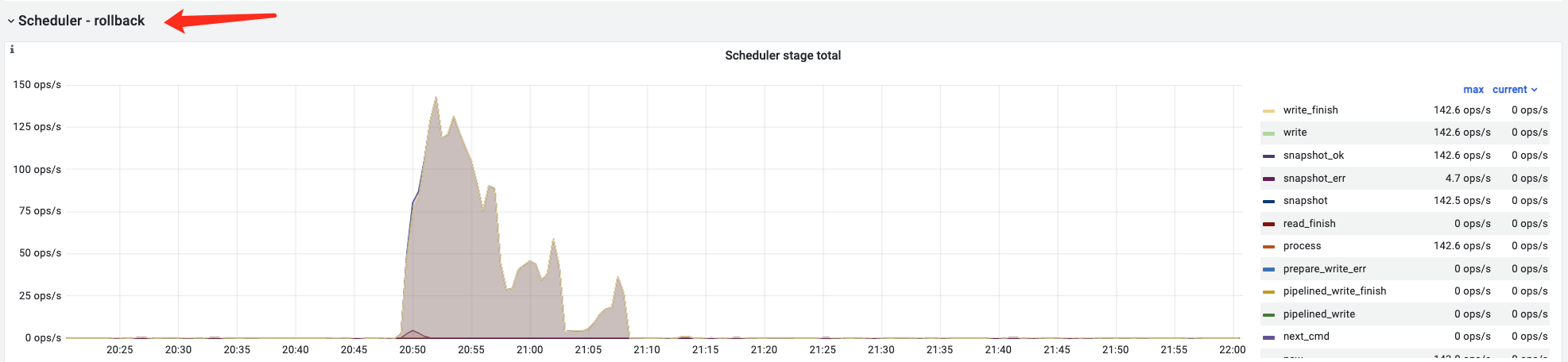
另外这是我在故障期间看到的scheduler-rollback的监控,刚好和故障影响时间是吻合的:
h5n1
(H5n1)
5
正常行为,调整leder转移速度的方式就是调整store limit 和 几个schedule limit,可以分别通过pd-ctl store limit 和pd-ctl config show 查看
vincent
(Ti D Ber Ou5 Pvnh X)
6
所以说其实是因为balance leader期间,有请求而导致的影响时间变长了
h5n1
(H5n1)
7
会 的 ,tidb 侧有region cache,里面记录的leader是down的tikv ,这是tidb访问就会返回一个错误 ,tidb会用返回的信息进行访问重试,
h5n1
(H5n1)
8
现在是一个tikv主机宕后 导致你前段业务有报错了,这个量在25%左右? scheduler-rollback监控是事务rollback命令在tikv的消耗
vincent
(Ti D Ber Ou5 Pvnh X)
9
是的,业务的报错在25%左右,并且持续18分钟才全部恢复,就是一个机器重启了导致的,我们觉得这个影响时间太长,影响范围也比较大。
zhanggame1
(Ti D Ber G I13ecx U)
10
我也不是太懂这么复杂的架构,我看到一个机器上有24个tikv实例,是不是太多了影响到恢复速度。另外tikv节点负载怎么样,cpu或者io是不是特别高。
不太理解只有一个ssd为啥会有这么tikv用,io不会有问题吗
1 个赞
redgame
(Ti D Ber Pa Amoi Ul)
11
试下优化 TiKV 的配置,以加快恢复速度。例如,调整相关参数(如 raft-store-max-peer-count、raft-apply-pool-size 等)来提高恢复速度。此外,确保节点之间的网络连通性和带宽充足也是关键。
vincent
(Ti D Ber Ou5 Pvnh X)
12
一个机器上有24个SSD磁盘,每个磁盘作为一个tikv store的数据分区。
cpu的负载还好,64c的,平均负载30左右。磁盘IO集群整体在70%的样子。
1 个赞
vincent
(Ti D Ber Ou5 Pvnh X)
13
嗯,这个调整了,我们会演练一下,因为现在这种情况模拟不出来,得集群有一定数据量并且适当的规模。
我们使用场景都是采用tikv事务,一个事务包含多个操作,比如先get某个key,然后put,再get等,节点宕机的时候应该是有很多事务失败了。
raft-store-max-peer-count、raft-apply-pool-size这些值我们演练的时候会验证下。
h5n1
(H5n1)
14
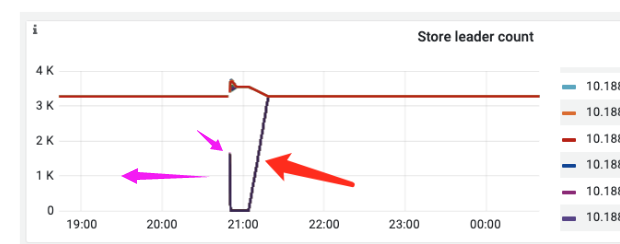
这里leader的黑线 是一堆tikv实例叠加一起的吗?这个监控前面没有数据 看起来像之前就有问题了,然后开始有监控数据的时候是起来了,之后又down掉重启了。能看看这个黑线再前面有数据吗 ?
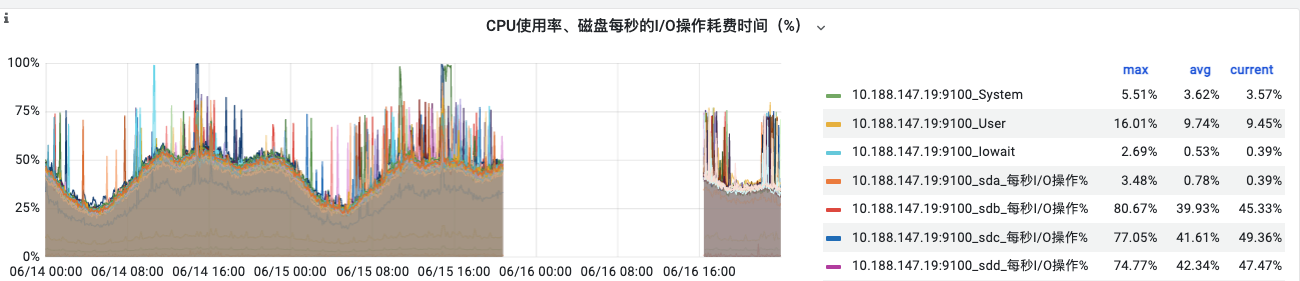
另外看下tikv节点再出问题时间段的CPU利用率 IO情况
vincent
(Ti D Ber Ou5 Pvnh X)
15
是的,这里的黑线是这台机器上24个tikv store.
监控前面没有数据是机器故障了,也就30s,然后直接就挂掉重启了。
cpu的负载如下:
磁盘的IOps:
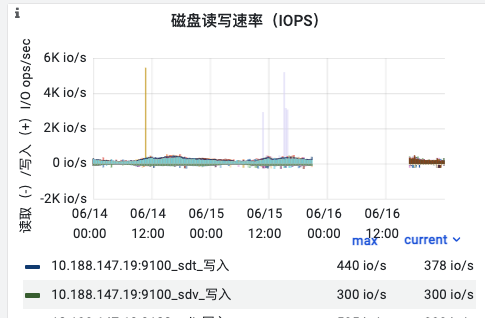
磁盘利用率:
cpu使用率:
h5n1
(H5n1)
18
要看其他节点的 ,因这个已经宕了,正常节点资源不足可能影响leader election ,不过根据官网描述这个最大超时时间也只有20秒。另外有一个静默region的特性 默认开启后是5分钟发一次心跳,有可能影响election。
1 个赞
dba-kit
(张天师)
19
你们是RawKV模式部署的,没有部署tidb-server组件?
vincent
(Ti D Ber Ou5 Pvnh X)
20
没有部署tidb。
我们使用的go client: github.com/tikv/client-go/v2/tikv
使用其:KVTxn,对应:transaction.KVTxn