【 TiDB 使用环境】生产环境
【 TiDB 版本】v6.1.1
【复现路径】升级已经接近一年,最近未做过任何调整
【遇到的问题:问题现象及影响】
最近两天,tikv grpc duration 突然升高,导致整个集群访问急剧下降,感觉前面一堆sql全都堵着,完全不在执行。
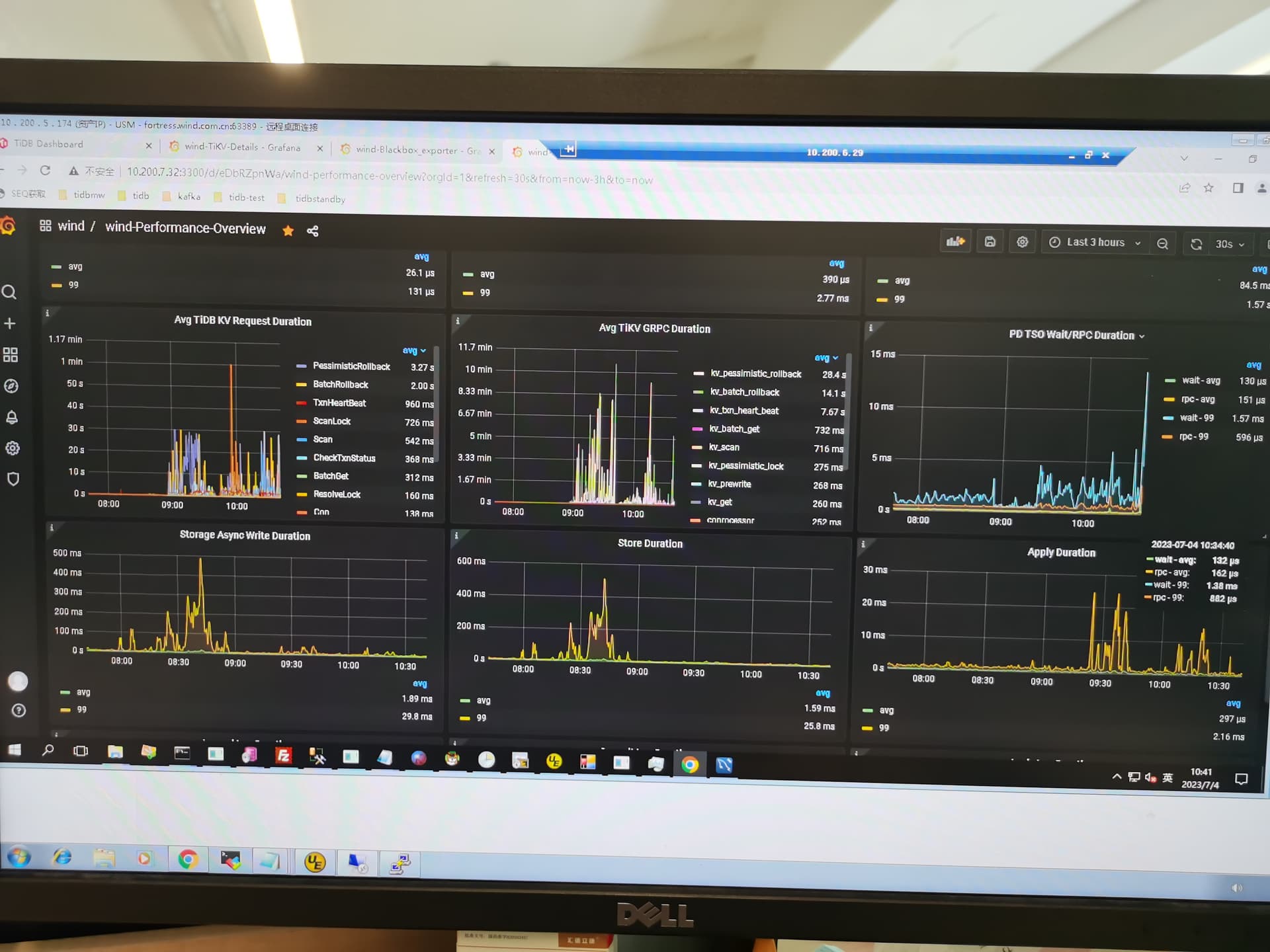
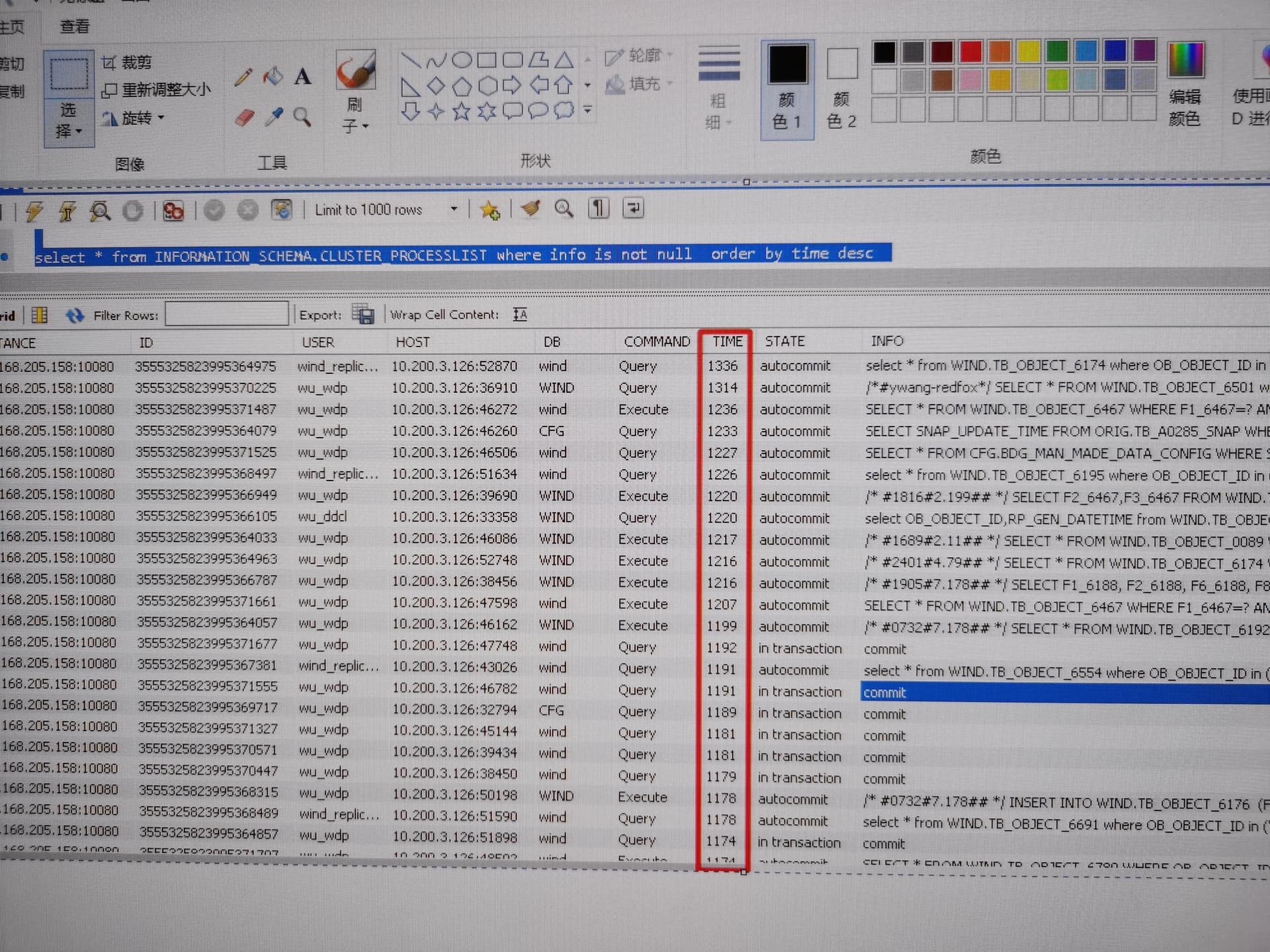
blackeexporter nodeexporter看下网络监控
1 个赞
网络未发现有延时情况, 集群节点间通信都是万兆光纤,看起来不是网络的问题
慢SQL排查过吗?还有 磁盘IO CPU
tikv 是ssd,io平时就比较高,最近也没有明显变化,看后面的 append log/commit log/apply log 等duration性能也都还行,没有明显增加。
cpu利用率就更低了,平均都在20% 以下
慢查询平时一直都很关注的,现在堵塞的那些sql执行计划看起来都是没有问题的
监控贴图上来,用数据说话可信度才会比较高
1 个赞
需要哪些监控图,谢谢
最好把详细路径也列一下,有劳了
帖子中你提到的和大佬提到的相关的监控
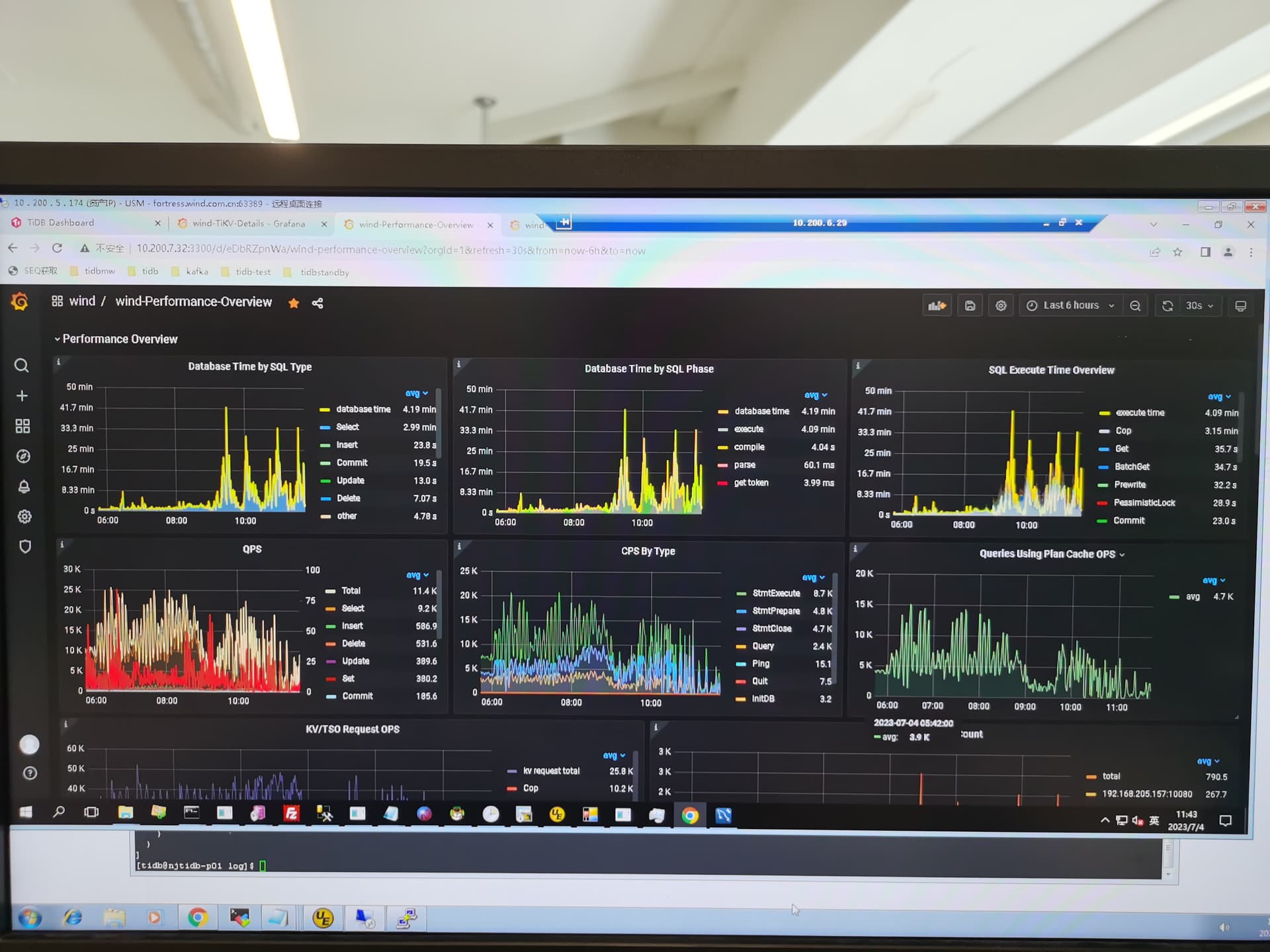
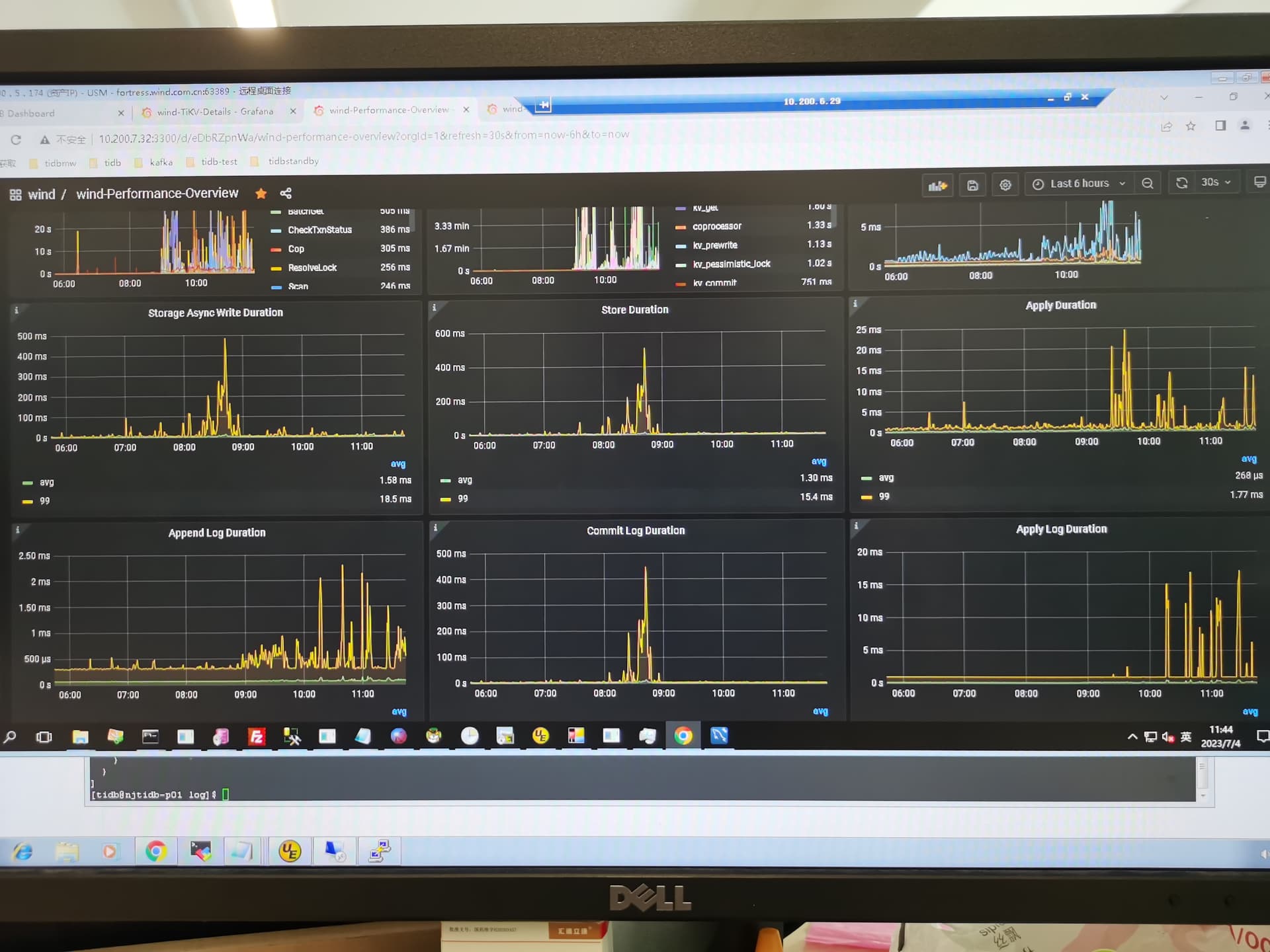
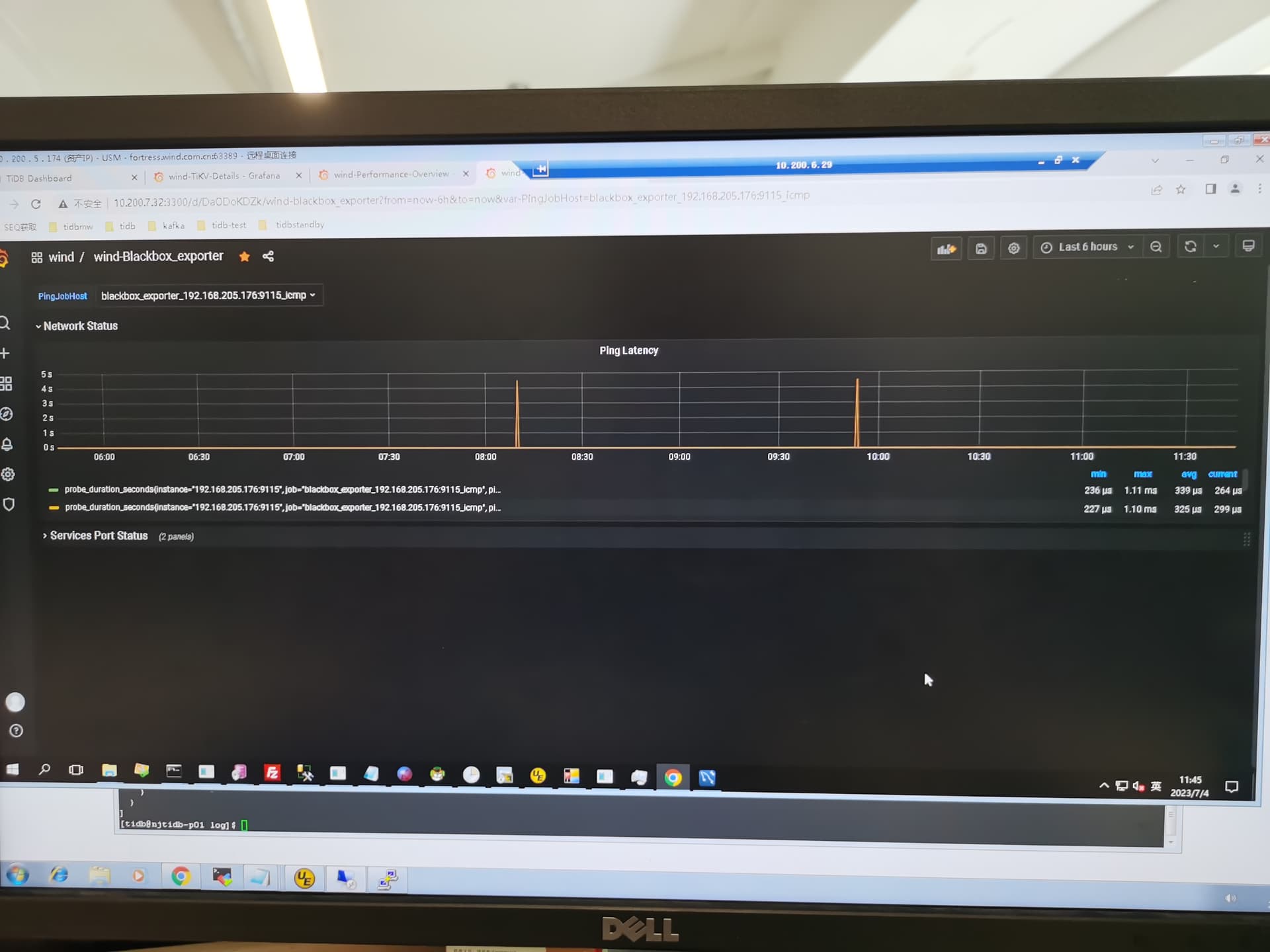

这个只是偶尔出现一次啊,看下面的avg数据,只有300多us啊
这个偶尔看上去都不正常 ,一般这种高的也就几毫秒
1 个赞
好的,我找IT看看网络方面有没有问题
其他还有什么优化的方向吗?
pd-ctl store 看下
昨天遇到一个 故障了2台机器的集群,region多副本失联,不能正常工作,启动一个以后正常了。
实例看起啦都正常的,最近也没有崩溃重启的情况
看下最近一段时间内的sql语句分析 看看是那些sql耗时长调用频繁
跪谢大佬,IT检测后发现有一个tikv节点的光模块有问题,有大量丢包,更换硬件之后,性能立马恢复了,非常感谢。
1 个赞
这种报错很像丢包,其实挺好查的
搞了半天是网络的锅
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。