【 TiDB 使用环境】生产环境
【 TiDB 版本】6.1.6
【复现路径】
【情况:
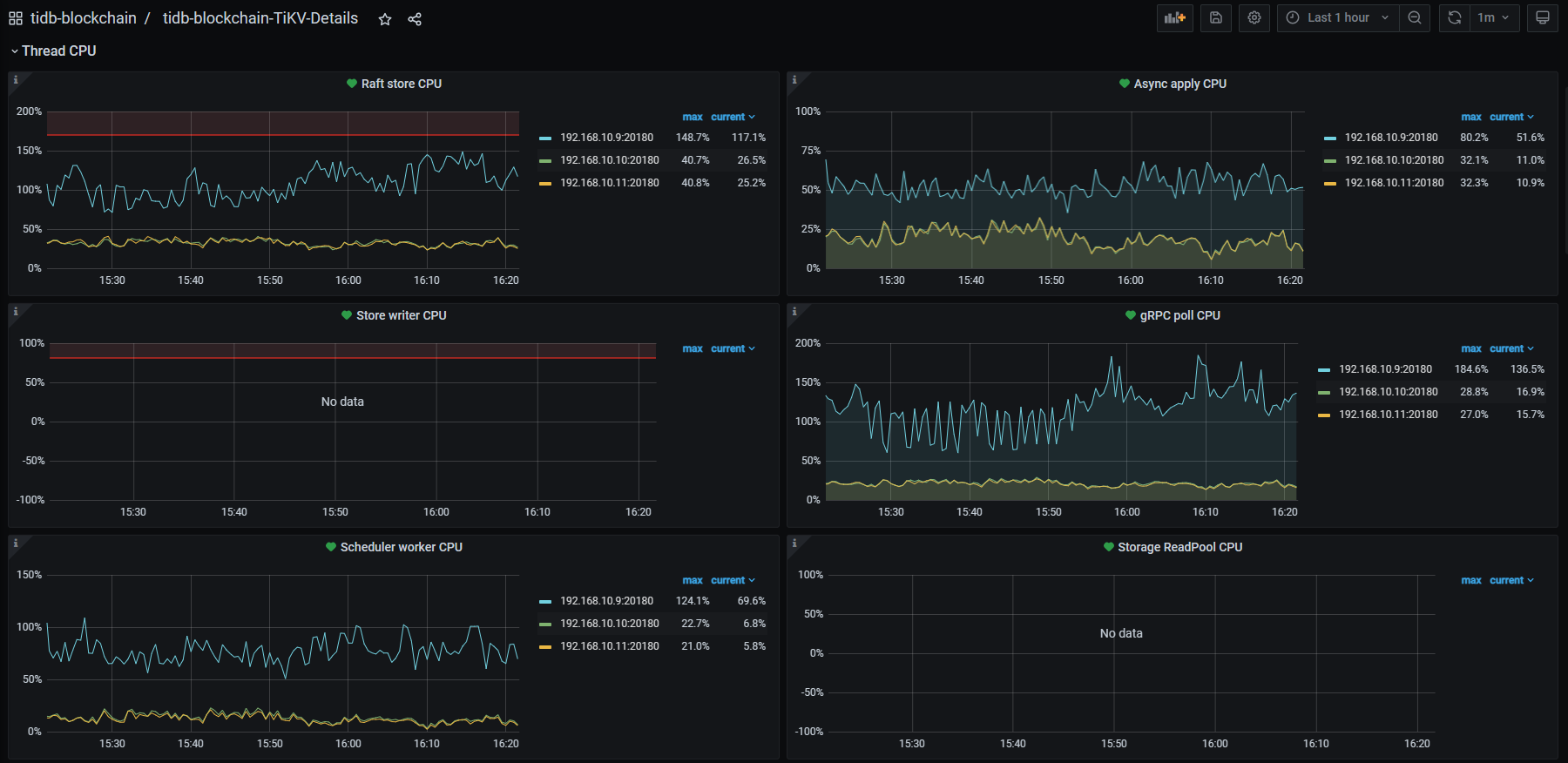
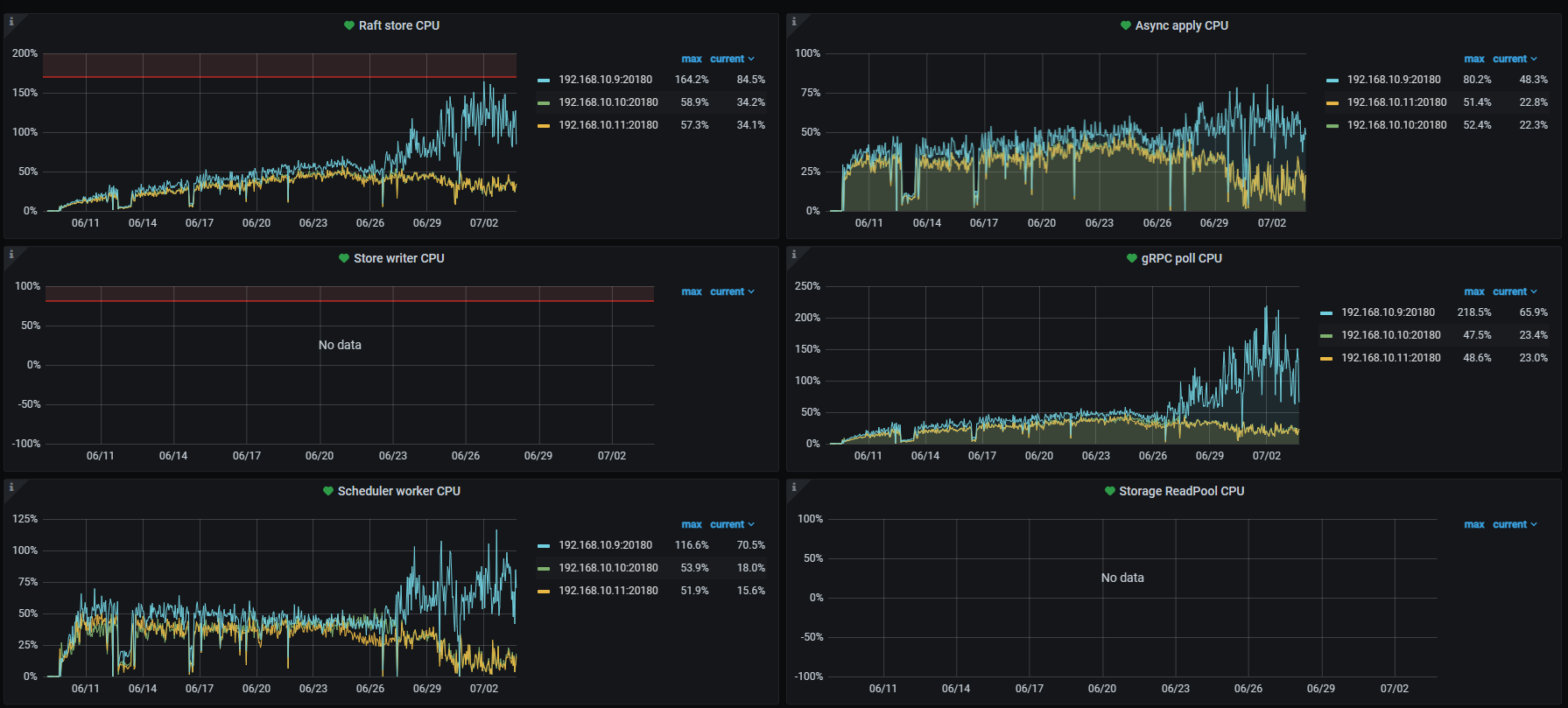
a. 三个TiKV结点中有一个的各项CPU指标都很高,从项目启动开始即这样。6月26日这一现象被放大了数倍。
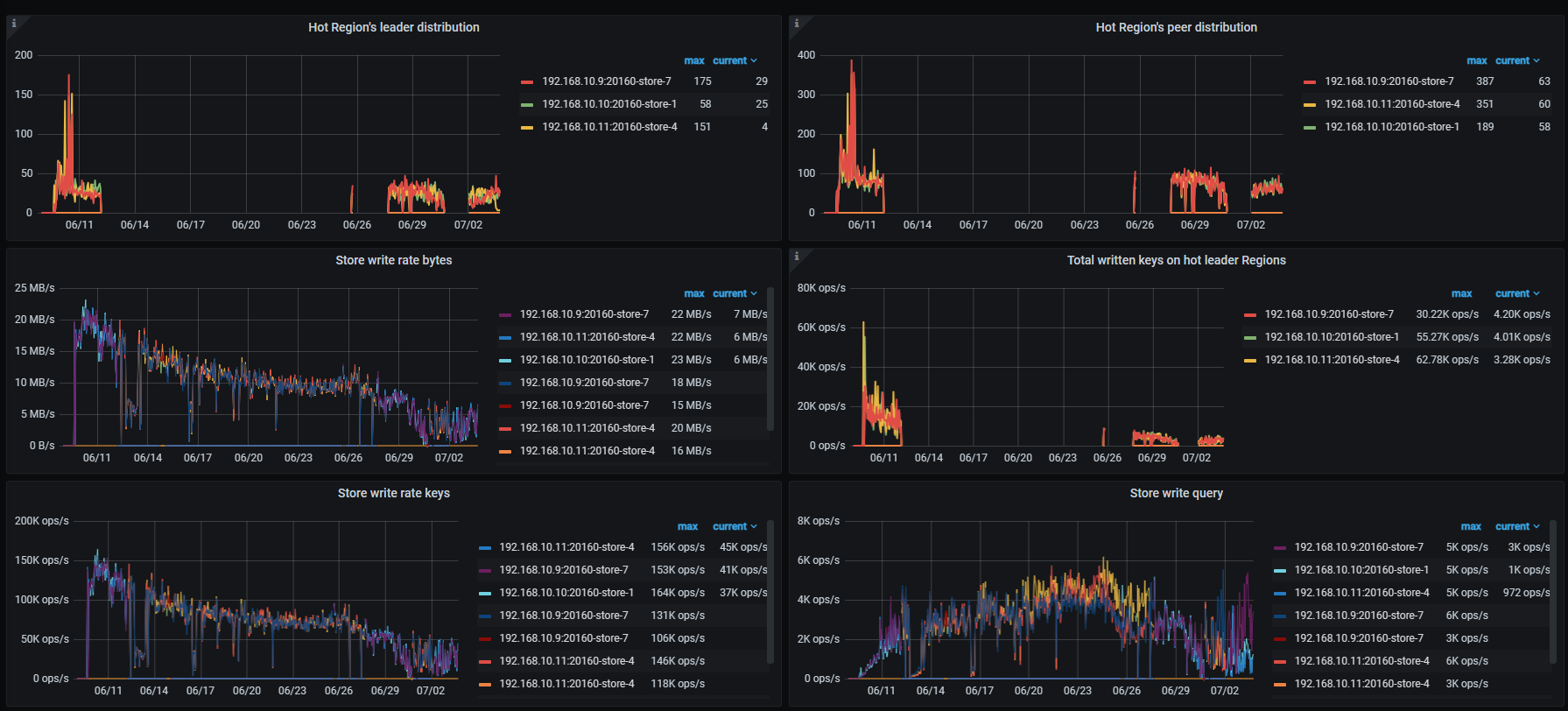
b.项目正执行大规模的数据写入,目前三张表数据分别为22亿/10亿/7亿,打散优化已执行,但是仍然有出现写热点,写入速度忽快忽慢
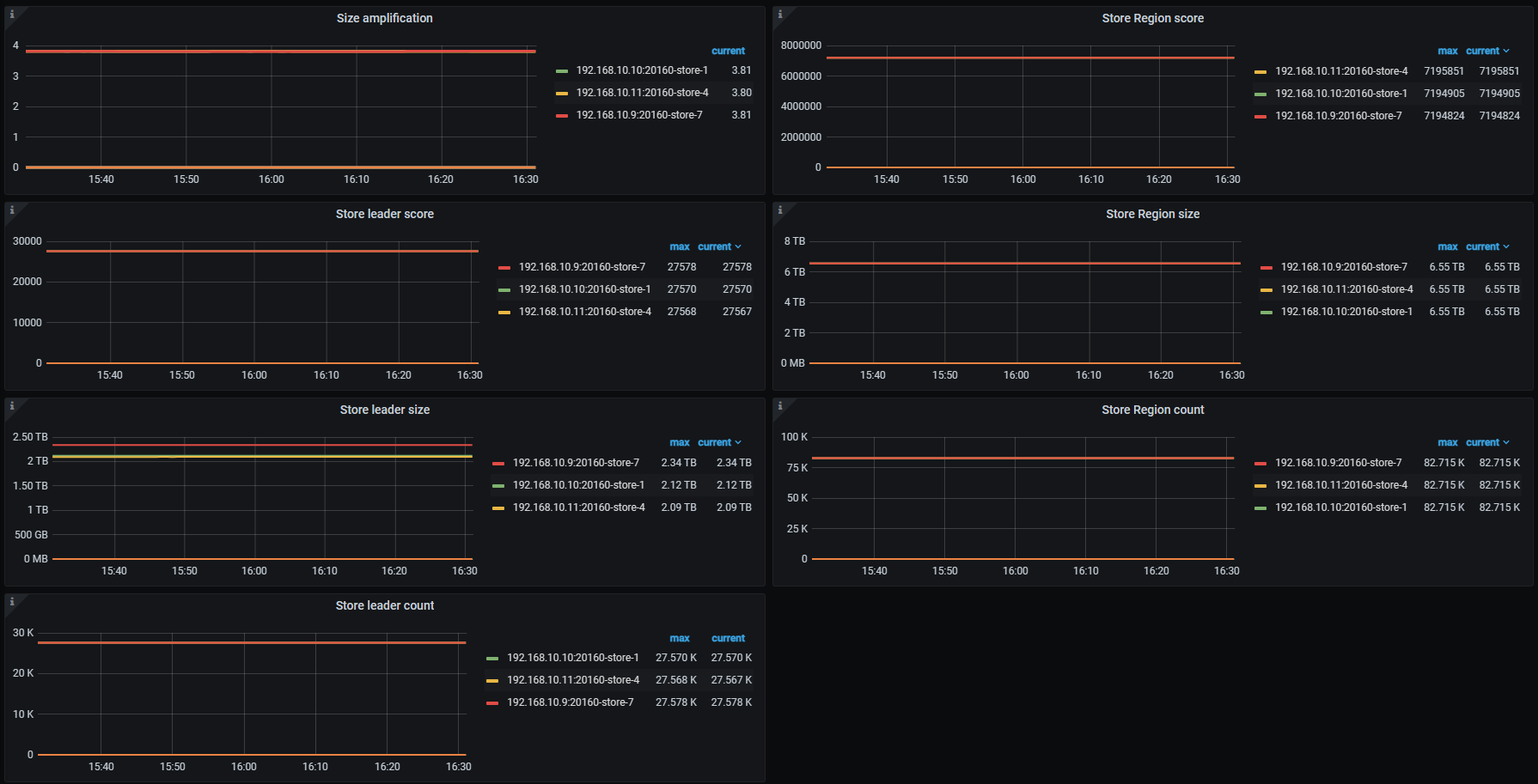
c.三个TiKV结点region和leader很均匀
d. 三个PD结点未做负载均衡,曾尝试负载均衡,结果造成写入速度进一步下降
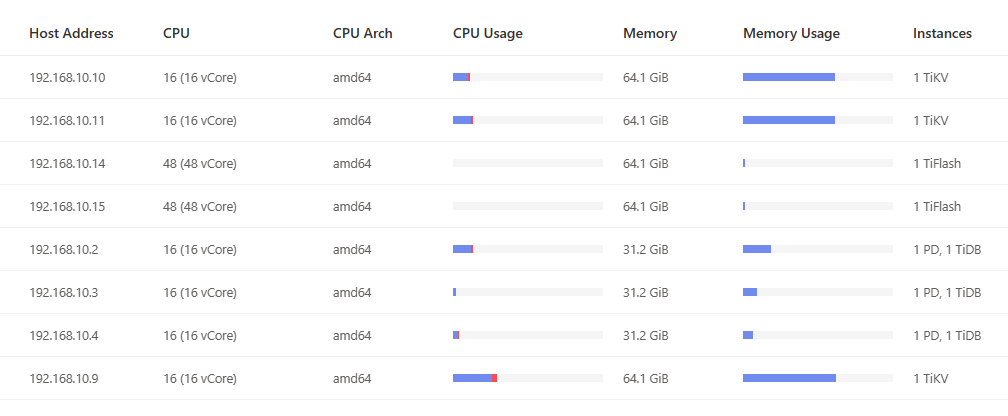
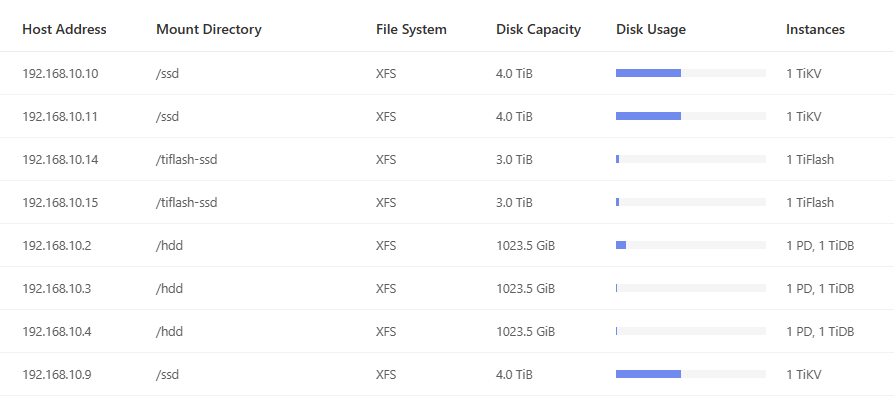
e.所有结点均在同一台物理机上
】
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
有猫万事足
2
怀疑是写入热点。
直接进tidb dashboard,选流量可视化。看看对应时间段的写入字节量图,是什么样的。
leader和region在3个tikv上的数量是均衡的,不代表单表的region和leader在3个tikv上是均衡的。所以你这些图仍然难以排除是写入热点。
打散优化是怎么执行的,也可以说一下。
看下grafana上 Statistics - hot write这个监控的情况
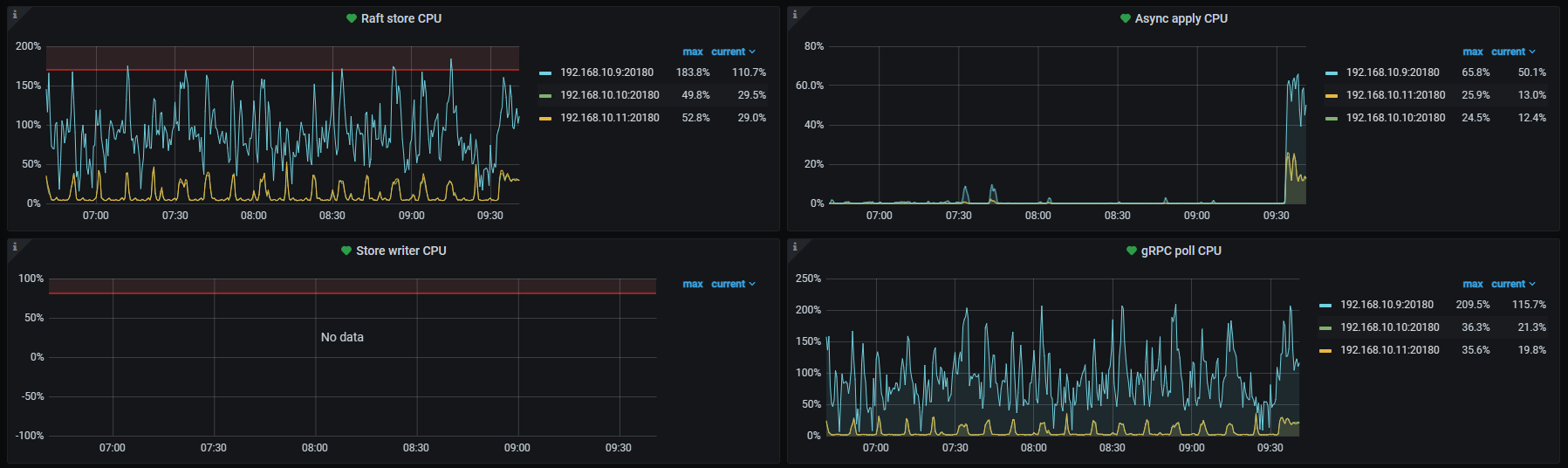
写热点应该一直都在,但是从6月26日下午4点左右开始192.168.10.9这台的CPU负载,从比其他两个结点高10~20%提高到了50~100%
写入热点是从项目启动时就一直存在,但是在启动后的两周内,现在CPU负载最高的这个结点只是比其他两个结点略高10~20%的程度,6月26日后变成现在这样能高出100%。
表ID使用了uuid生成
表中存在timestamp和int类型索引
建表语句中增加了SHARD_ROW_ID_BITS=4 PRE_SPLIT_REGIONS=4
建表后执行了 ALTER TABLE {sheet} ATTRIBUTES ‘merge_option=deny’
在今年4月份的时候,曾经进行了一次无优化的执行,写入数据量与现在相当,写入效率只有现在的一半不到。
你把Statistics - balance时间拉长一点,看下6月27号左右开始,10.9的均衡是不是有问题
zhanggame1
(Ti D Ber G I13ecx U)
10
三个tikv 3个副本写入性能消耗应该差不多吧,我觉得可能有读热点,开没开follower read,没开可以试试
有猫万事足
11
SHARD_ROW_ID_BITS=4 PRE_SPLIT_REGIONS=4
你这个预分裂的个数对应你的导入的数据量可能还有点保守。
我单表2亿多数据,分到
SHARD_ROW_ID_BITS=5 PRE_SPLIT_REGIONS=5
dm导入这个表的时候,4个tikv是均衡的。cpu基本可以做到一起打满。
SHARD_ROW_ID_BITS=4 PRE_SPLIT_REGIONS=4
我这个组合我没实验过。
不过我可以肯定原来设置为
SHARD_ROW_ID_BITS=3 PRE_SPLIT_REGIONS=2
的时候4个tikv里面有一台tikv的cpu只有10-20,完全是在围观其他3个tikv。
你的单表数据量比我大很多,性能也比我的好,我觉得可以继续调大预分裂的个数。观察tikv cpu是否能一起打满。
h5n1
(H5n1)
13
pd-ctl store weight xxx xxx xx 把cpu高的tikv leader权重一点点调低些,再看看均衡情况
1 个赞
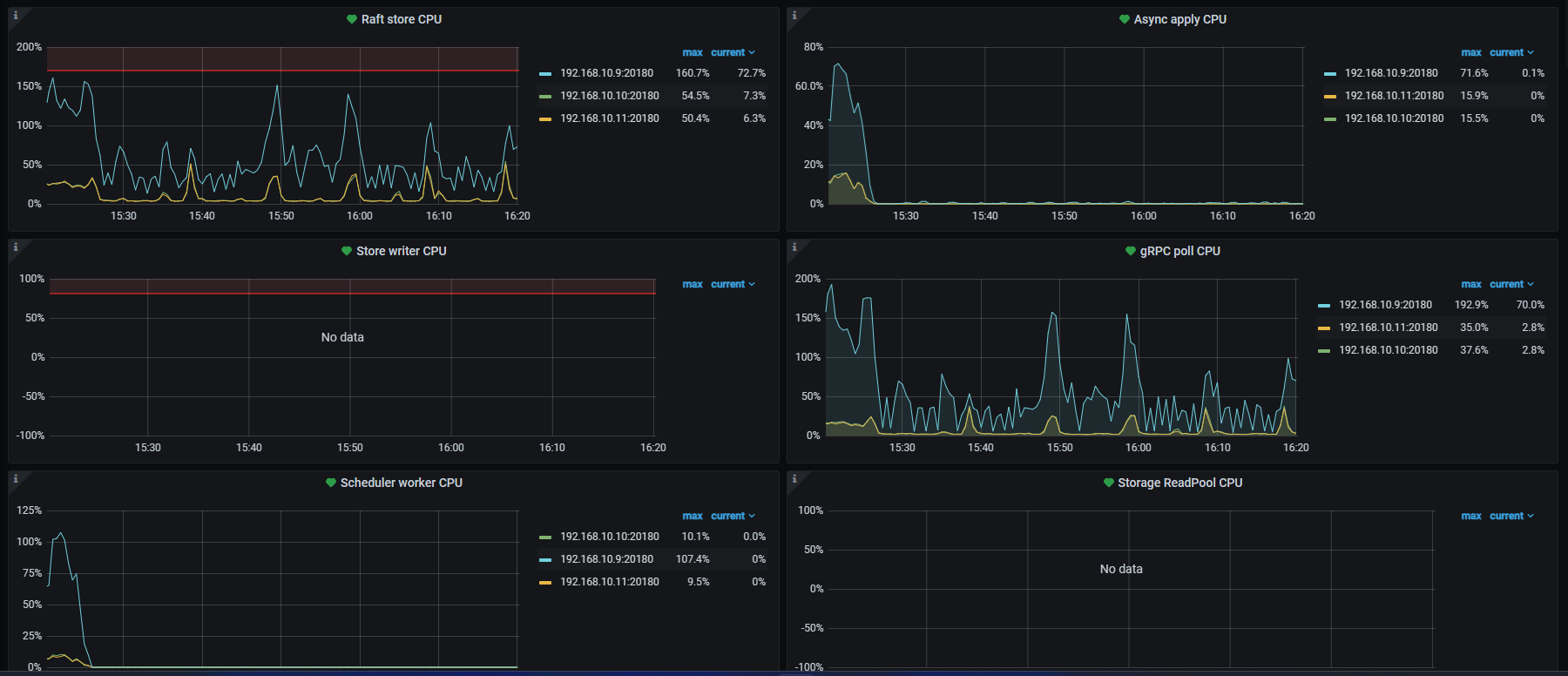
刚刚停止了所有外部数据库操作,但是这个结点依然运行在一个高负载的状态,慢查询语句中存在大量内部sql操作
1 个赞
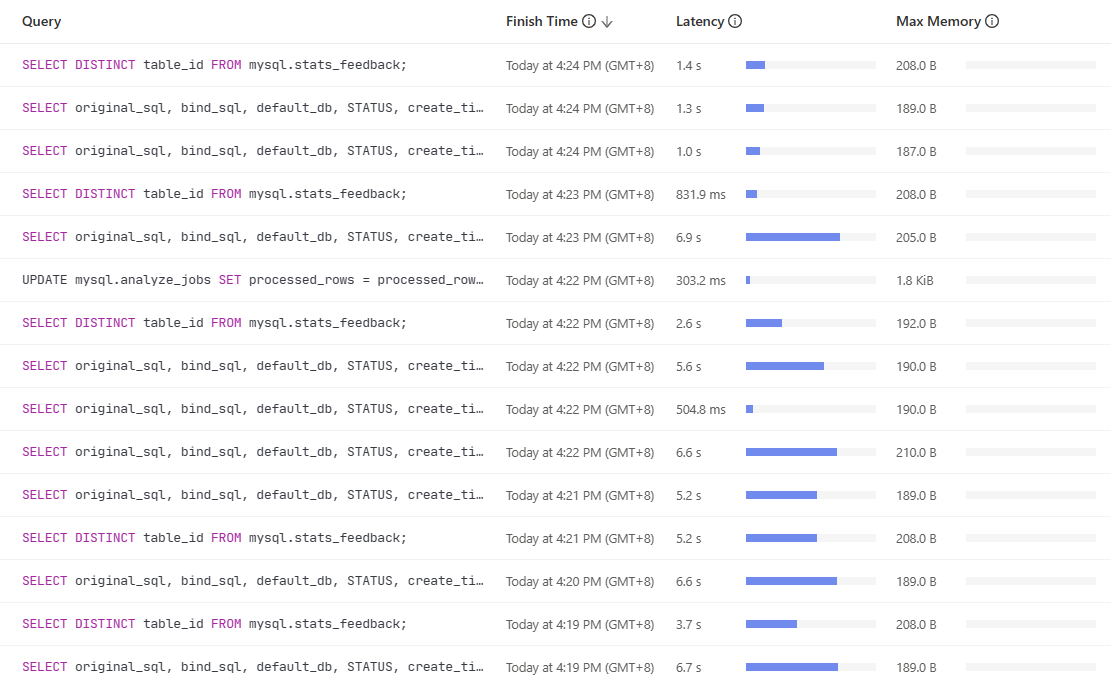
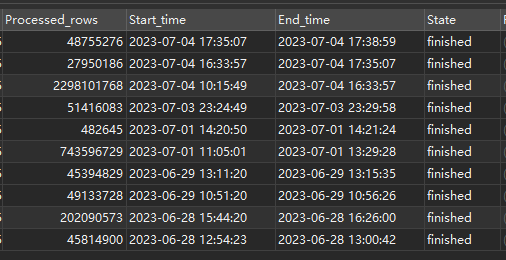
SHOW ANALYZE STATUS看下是不是在收集统计信息,可以把对应3个大表的自动收集统计信息任务暂停
尝试调高了SHARD_ROW_ID_BITS并放置了一晚上,通过show table {sheet} regions可以看到表的region在各节点的数量发生了变化,但问题依旧存在。
22亿数据的表regions变化情况:
192.168.10.9(高负载) 14681 → 11158
192.168.10.10 12100 → 13737
192.168.10.11 11976-> 13996
1 个赞
昨天下午4点,这个22亿的表不是正在执行自动收集统计信息吗?就是那个时候有很多内部的统计信息相关的sql吧,你说的22亿/10亿/7亿这三张大表,是这几天一下子入了很多数据吗?可以考虑先把这三个表的自动收集统计信息暂停,等数据入完统一收集。

h5n1
(H5n1)
23
试试pd-ctl store weight xxx xxx xx 把cpu高的tikv leader权重一点点调低些,再看看均衡情况