tug_twf
(Hacker Fqg5 Vi Rn)
1
【 TiDB 使用环境】生产环境
【 TiDB 版本】6.1.6
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
tidb 经常查询抖动,抖动时一般伴随下面这种情况
看一下其中一个比较慢的时间点 指向的是一个tikv,从这个tikv日志来看 ,raft相关同步卡顿导致慢了
raft相关延迟确实比较高
然后调整过 raftstore.store-io-pool-size 相关参数 并没有效果
观察到两个奇怪现象
1.tikv的black cache hit很低,跟其他集群表现不一样,如下图
2.raft cpu持续抖动,sql出现抖动和这个cpu抖动时间相对比较吻合 10分钟抖动一次
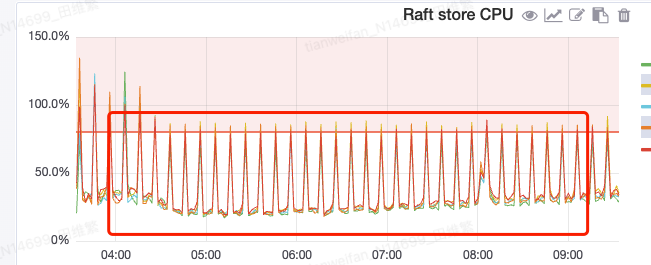
关于10分钟有波动这个,尝试停止了raft和rocksdb的10分钟一次的统计信息,还有其他的参数都没有效果
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
Anna
(Ti D Ber Yz R Jp Sz D)
2
我的第一反应是,你说的IO是不是满了。看看磁盘读写
1 个赞
Anna
(Ti D Ber Yz R Jp Sz D)
3
优化因调度功能不完善或者 I/O 限流不完善引起的性能抖动问题
TiDB 调度过程中会占用 I/O、Network、CPU、Memory 等资源,若不对调度的任务进行控制,QPS 和延时会因为资源被抢占而出现性能抖动问题。通过以下几项的优化,长期测试 72 小时,衡量 Sysbench TPS 抖动标准差的值从 11.09% 降低到 3.36%。
- 减少节点的容量总是在水位线附近波动引起的调度及 PD 的
store-limit 配置项设置过大引起的调度,引入一套新的调度算分公式并通过 region-score-formula-version = v2 配置项启用新的调度算分公式 #3269
- 通过修改
enable-cross-table-merge = true 开启跨 Region 合并功能,减少空 Region 的数量 #3129
- TiKV 后台压缩数据会占用大量 I/O 资源,系统通过自动调整压缩的速度来平衡后台任务与前端的数据读写对 I/O 资源的争抢,通过
rate-limiter-auto-tuned 配置项开启此功能后,延迟抖动比未开启此功能时的抖动大幅减少 #18011
- TiKV 在进行垃圾数据回收和数据压缩时,分区会占用 CPU、I/O 资源,系统执行这两个任务过程中存在数据重叠。GC Compaction Filter 特性将这两个任务合二为一在同一个任务中完成,减 I/O 的占用。此特性为实验性特性,通过
gc.enable-compaction-filter = true 开启 #18009
- TiFlash 压缩或者整理数据会占用大量 I/O 资源,系统通过限制压缩或整理数据占用的 I/O 量缓解资源争抢。此特性为实验性特性,通过
bg_task_io_rate_limit 配置项开启限制压缩或整理数据 I/O 资源。
Anna
(Ti D Ber Yz R Jp Sz D)
4
优化因调度功能不完善引起的性能抖动问题
#18005
TiDB 调度过程中会占用 I/O、网络、CPU、内存等资源,若不对调度的任务进行控制,QPS 和延时会因为资源被抢占而出现性能抖动问题。
通过以下几项的优化,测试 8 小时,TPC-C 测试中 tpm-C 抖动标准差的值小于等于 2%。
引入新的调度算分公式,减少不必要的调度,减少因调度引起的性能抖动问题
当节点的总容量总是在系统设置的水位线附近波动或者 store-limit 配置项设置过大时,为满足容量负载的设计,系统会频繁地将 Region 调度到其他节点,甚至还会调度到原来的节点,调度过程中会占用 I/O、网络、CPU、内存等资源,引起性能抖动问题,但这类调度其实意义不大。
为缓解此问题,PD 引入了一套新的调度算分公式并默认开启,可通过 region-score-formula-version = v1 配置项切换回之前的调度算分公式。
默认开启跨表合并 Region 功能
用户文档
在 5.0 之前,TiDB 默认关闭跨表合并 Region 的功能。从 5.0 起,TiDB 默认开启跨表合并 Region 功能,减少空 Region 的数量,降低系统的网络、内存、CPU 的开销。你可以通过修改 schedule.enable-cross-table-merge 配置项关闭此功能。
默认开启自动调整 Compaction 压缩的速度,平衡后台任务与前端的数据读写对 I/O 资源的争抢
用户文档
在 5.0 之前,为了平衡后台任务与前端的数据读写对 I/O 资源的争抢,自动调整 Compaction 的速度这个功能默认是关闭的;从 5.0 起,TiDB 默认开启此功能并优化调整算法,开启之后延迟抖动比未开启此功能时的抖动大幅减少。
你可以通过修改 rate-limiter-auto-tuned 配置项关闭此功能。
默认开启 GC in Compaction filter 功能,减少 GC 对 CPU、I/O 资源的占用
用户文档,#18009
TiDB 在进行垃圾回收和数据 Compaction 时,分区会占用 CPU、I/O 资源,系统执行这两个任务过程中存在数据重叠。
GC Compaction Filter 特性将这两个任务合并在同一个任务中完成,减少对 CPU、I/O 资源的占用。系统默认开启此功能,你可以通过设置 gc.enable-compaction-filter = false 关闭此功能。
TiFlash 限制压缩或整理数据占用 I/O 资源(实验特性)
该特性能缓解后台任务与前端的数据读写对 I/O 资源的争抢。
系统默认关闭该特性,你可以通过 bg_task_io_rate_limit 配置项开启限制压缩或整理数据 I/O 资源。
增强检查调度约束的性能,提升大集群中修复不健康 Region 的性能
tug_twf
(Hacker Fqg5 Vi Rn)
5
吞吐量很小,就dm做数据同步几个表,然后简单查询,偶尔会卡顿,使用率也很低,怀疑还是跟raft这里cpu抖动影响
有猫万事足
8
有规律的10分钟跳一次的话,我会重点怀疑gc引起的。
你可以查看一下和gc 的运行时间是否能对的上。
如果确认是gc造成的这个tikv的写入慢,还是重点怀疑是不是磁盘有什么问题会比较合理。
因为,其他tikv也会在同一时间有gc但不会像这个tikv一样出问题罢了。
对比这个tikv和其他tikv的ops和写入字节量,如果这些都无明显差异,可能更像是单纯就是这个磁盘慢了。
tug_twf
(Hacker Fqg5 Vi Rn)
9
嗯嗯 开始怀疑过磁盘,但是其他tikv也有 只是当时是这个tikv 其他时间段是其他tikv ,所以不应该是磁盘有问题
gc时间之前也怀疑过,但是没有进行调整,
h5n1
(H5n1)
11
CPU是什么类型的,有没有关闭节能模式? 看看网络监控 可以从black exporter、nodeexporter里看
zhanggame1
(Ti D Ber G I13ecx U)
13
tikv_gc_run_interval
tikv_gc_life_time
两个都改了吗,和第一个关系大
有猫万事足
14




