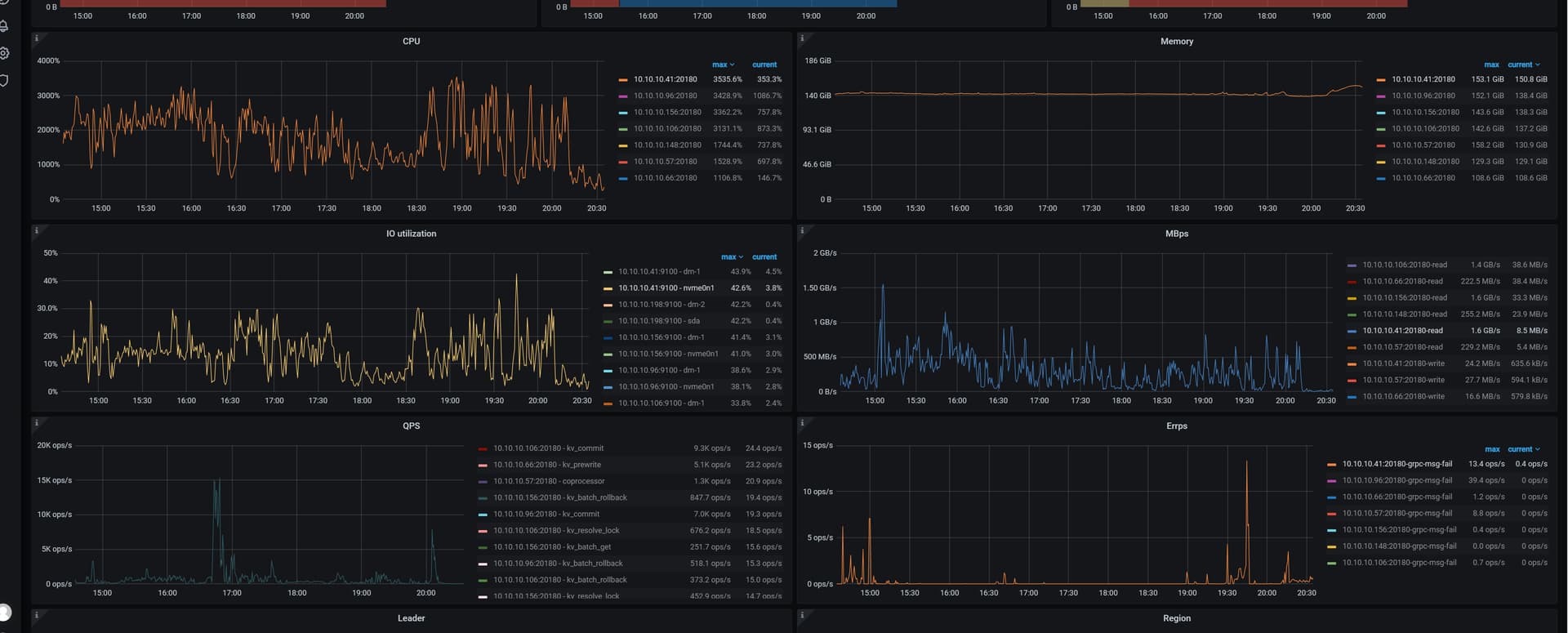
我都是NVME,磁盘性能从面板看是没问题的,也看了机器上的IO,确实都远远没达到上限
如果确定是固定两台机器时被认定为slow store才导致的Leader被驱逐,其实就是超过inspect-interval的检测时间了,可以按照下面步骤排查一下。

如果看监控,发现CPU和IO都没问题,只能是从网络层考虑了。。。
PS: 从6.1跨版本升级到6.5之后,就别考虑降级到6.1了,风险更大。如果是6.5.3降低6.5.1,大概率问题还在。
老师, 现在我的表象是这样了
[2023/06/24 16:29:46.040 +08:00] [Error] [peer.rs:5243] [“failed to send extra message”] [err_code=KV:Raftstore:Transport] [err=Transport(Full)] [target=“id: 8903050960 store_id: 4009574399”] [peer_id=8903050959] [region_id=8903050958] [type=MsgHibernateResponse]
[2023/06/24 16:29:46.040 +08:00] [Error] [peer.rs:5243] [“failed to send extra message”] [err_code=KV:Raftstore:Transport] [err=Transport(Full)] [target=“id: 8902003642 store_id: 4009574399”] [peer_id=8902003641] [region_id=8902003640] [type=MsgHibernateResponse]
[2023/06/24 16:29:46.040 +08:00] [Error] [peer.rs:5243] [“failed to send extra message”] [err_code=KV:Raftstore:Transport] [err=Transport(Full)] [target=“id: 8891371182 store_id: 4009574399”] [peer_id=8891371181] [region_id=8891371180] [type=MsgHibernateResponse]
[2023/06/24 16:29:46.040 +08:00] [Error] [peer.rs:5243] [“failed to send extra message”] [err_code=KV:Raftstore:Transport] [err=Transport(Full)] [target=“id: 4098697666 store_id: 4009574399”] [peer_id=4098698273] [region_id=4098697663] [type=MsgHibernateResponse]
[2023/06/24 16:29:46.040 +08:00] [Error] [peer.rs:5243] [“failed to send extra message”] [err_code=KV:Raftstore:Transport] [err=Transport(Full)] [target=“id: 8892136943 store_id: 4009574399”] [peer_id=8892136567] [region_id=8892136565] [type=MsgHibernateResponse]
[2023/06/24 16:29:46.040 +08:00] [Error] [peer.rs:5243] [“failed to send extra message”] [err_code=KV:Raftstore:Transport] [err=Transport(Full)] [target=“id: 8901888827 store_id: 4009574399”] [peer_id=8901888828] [region_id=8901888825] [type=MsgHibernateResponse]
[2023/06/24 16:29:46.040 +08:00] [Error] [peer.rs:5243] [“failed to send extra message”] [err_code=KV:Raftstore:Transport] [err=Transport(Full)] [target=“id: 4110149072 store_id: 4009574399”] [peer_id=4110149070] [region_id=4110149069] [type=MsgHibernateResponse]
[2023/06/24 16:29:46.040 +08:00] [Error] [peer.rs:5243] [“failed to send extra message”] [err_code=KV:Raftstore:Transport] [err=Transport(Full)] [target=“id: 6572647863 store_id: 4009574399”] [peer_id=4103365212] [region_id=4103365210] [type=MsgHibernateResponse]
[2023/06/24 16:29:46.040 +08:00] [Error] [peer.rs:5243] [“failed to send extra message”] [err_code=KV:Raftstore:Transport] [err=Transport(Full)] [target=“id: 4109929651 store_id: 4009574399”] [peer_id=4109929649] [region_id=4109929648] [type=MsgHibernateResponse]
[2023/06/24 16:29:46.040 +08:00] [Error] [peer.rs:5243] [“failed to send extra message”] [err_code=KV:Raftstore:Transport] [err=Transport(Full)] [target=“id: 6276480606 store_id: 4009574399”] [peer_id=4103355003] [region_id=4103355001] [type=MsgHibernateResponse]
[2023/06/24 16:29:46.040 +08:00] [Error] [peer.rs:5243] [“failed to send extra message”] [err_code=KV:Raftstore:Transport] [err=Transport(Full)] [target=“id: 4055643538 store_id: 4009574399”] [peer_id=4055643537] [region_id=4055643535] [type=MsgHibernateResponse]
大量这个错误,然后过一会就开始驱逐leader了
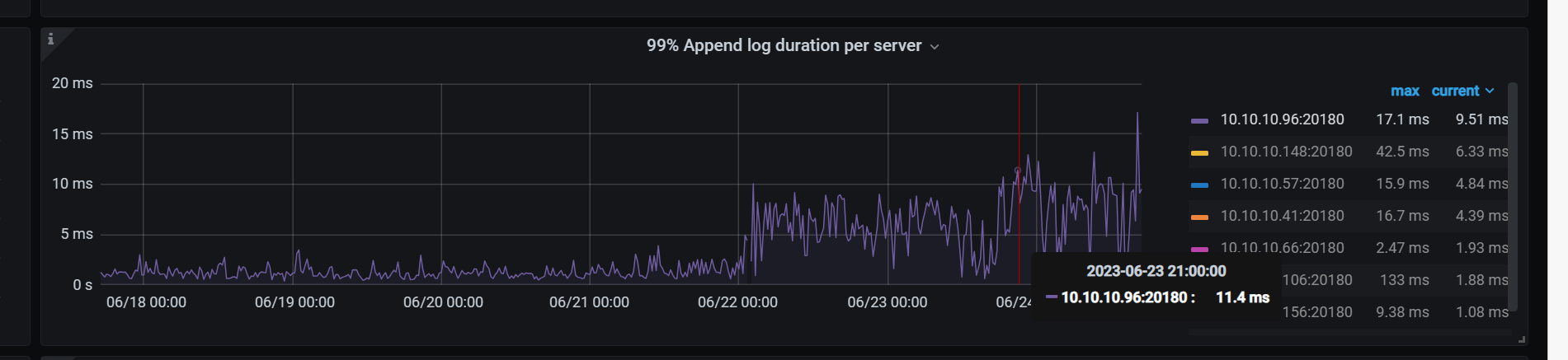

其他4个节点的Raft IO延时增加了么?

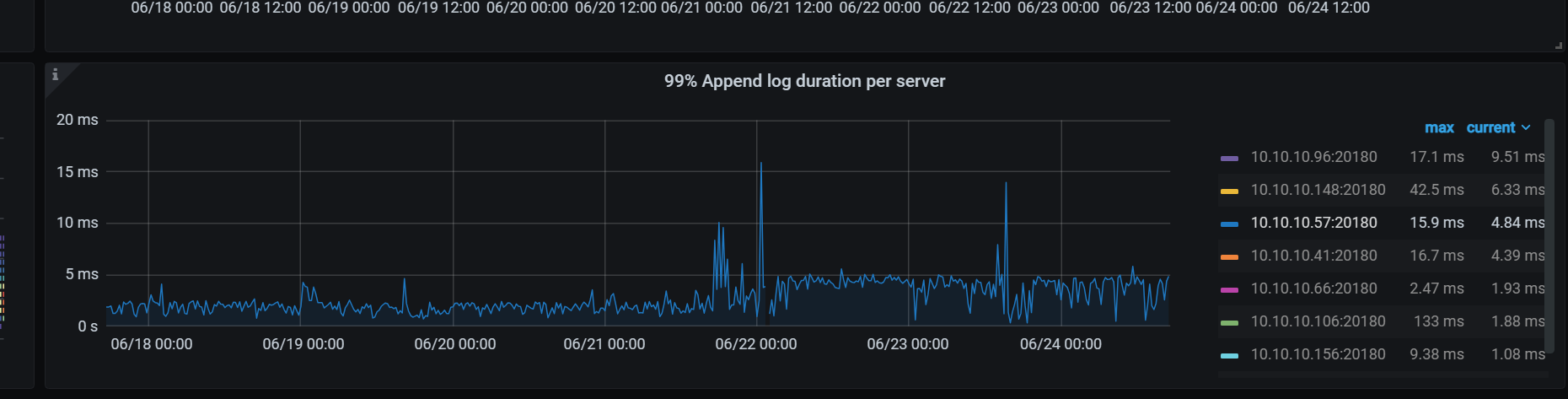
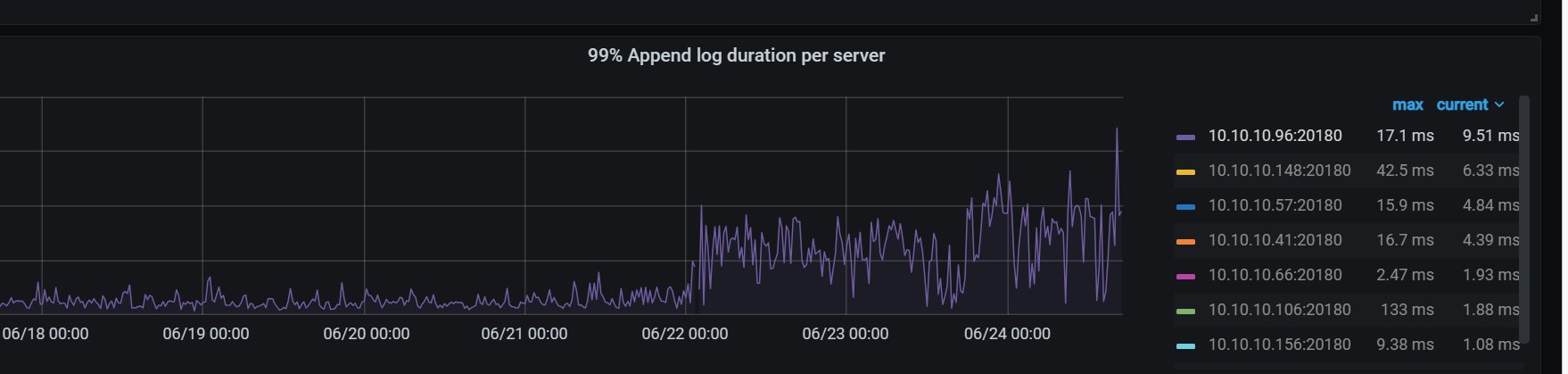

老师, * 调大 TiKV raftstore.inspect-interval 参数,提高延迟检测的超时上限。
这个值建议可以设置多少,我给他设置了 3000 ,是否可以适当在加大?
老师,这高延迟很高感觉也是相对的,我看这个都没超过10ms
我看官方给的例子截图,也比我这个高很多了
具体来说,多少算作是 高延迟了呢? 我看这个我的数据虽然高了.但是依然在 20ms以下

你好,请问现在 cdc 能够恢复同步了吗?
- 能否在卡住的时候用以下脚本抓一下 cdc 的 goroutine 信息?
#!/bin/bash
# 使用该脚本之前,你需要修改这个列表中的地址为你要下载的 cdc profile 的地址
HOSTLIST=("127.0.0.1:8300") # 定义要连接的服务器的列表
for host in "${HOSTLIST[@]}"
do
h=${host%%:*}
p=${host#*:}
echo $h $p
# 根据 host 和端口下载三个文件
curl -X GET http://${h}:${p}/debug/pprof/profile?second=120s > cdc.profile
curl -X GET http://${h}:${p}/debug/pprof/goroutine?debug=2 > cdc.goroutine
curl -X GET http://${h}:${p}/debug/pprof/heap > cdc.heap
dir=$h.$p
# 将下载的文件打包成文件夹,并将文件夹压缩成 $dir.tar.gz 文件
mkdir $dir
mv cdc.profile cdc.goroutine cdc.heap $dir
tar -czvf $dir.tar.gz $dir
rm -r $dir
done
- 能否提供经过脱敏之后的 cdc 日志?只需要提供 processor.go, changefeed.go, ddl_puller.go 打出来的所有日志和其他文件打出来的所有 ERROR 级别的日志就足够了。
没有恢复正常,断断续续,勉强能用
老问题, 节点始终会有的slow store score 100 ,然后发生leader 迁移 …集群立马不稳定
问题都出现这么长时间了 有没有尝试扩容几个节点吧有问题的节点缩掉
当然扩了 …扩了 2个节点, 没效果
可以查看下监控项: TiKV Auto GC SafePoint
把有问题的缩了没
有i问题的,已经驱逐了leader,下节点因为需要几天,也在执行中,
但是把leader去掉.他就不会调用.就不会产生slow store score = 100的情况了
1 个赞
你是遇到了什么问题吗?
进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
能看下你的配置吗?
- 如果需求是 回退集群版本,其实有 2 种方法:
a. 备份数据,重新导入
b. 大体上只回退 对应的几个主要组件 binary, 按理说 小版本回退应该还好,但是官方并未提供这种方案的 SOP, 但私下测试是可行的(很早期 v4 的时候,测过). 这种办法回退后,还涉及到改 tiup meta,等步骤.
随着 tidb 功能越来越入复杂, 非常可能直接回退 binary 引发新的未知问题, 非要回退的话,还是 备份重新导吧.
-
其实当前集群的问题没太看明白,针对看到的几点说一下吧
a. 针对这种错误, Transport(Full) 说明信息通道中缓存的数据满了,活着的 TiKV 发送不了消息给挂掉的 TiKV 或者因为网络问题,消息会存在 buffer 里,默认大小是 raft_client_queue_size=8192,超过了就报这个错误. 就是说,这个日志只能证明 4009574399 已经出问题了
[2023/06/24 16:29:46.040 +08:00] [Error] [peer.rs:5243] [“failed to send extra message”] [err_code=KV:Raftstore:Transport] [err=Transport(Full)] [target=“id: 8903050960 store_id: 4009574399”] [peer_id=8903050959] [region_id=8903050958] [type=MsgHibernateResponse] [2023/06/24 16:29:46.040 +08:00] [Error] [peer.rs:5243] [“failed to send extra message”] [err_code=KV:Raftstore:Transport] [err=Transport(Full)] [target=“id: 8902003642 store_id: 4009574399”]b. 貌似好像没查明您所遇到问题原因
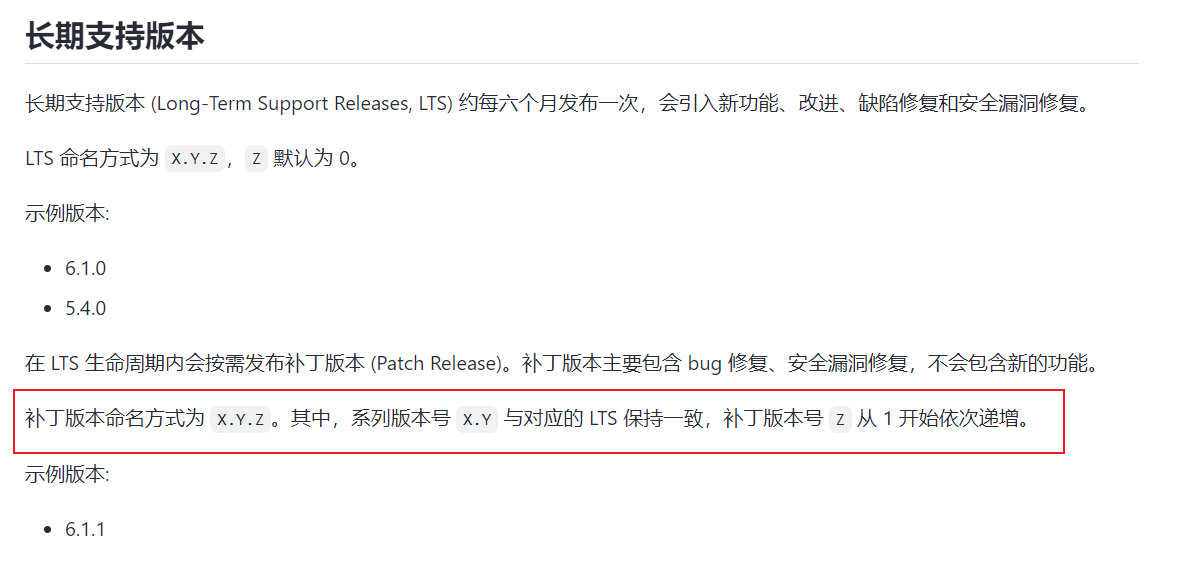
6.5.3直接换6.5.1的二进制不行吗?小版本升级也不会改数据格式,也不会改功能。只是修bug而已。直接换二进制有什么不行吗?
X.Y.Z 其中Y会引入功能变化,Z只是修复的bug。我认为Z以内的版本应该是可以随便换的吧。
https://docs.pingcap.com/zh/tidb/stable/versioning