【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】6.5.3 能否降级,太多问题了。
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
【资源配置】
【附件:截图/日志/监控】
回退是有风险的,最好备份数据,然后新建集群在导入数据就可以了
如果是测试环境,可以手动回退试试,但是成功机率不会太高…
生产环境, 有点蛋疼了.这个 6.5.3 问题很大条.现在真个要死了
要不升级到7.1试试
具体什么问题?不能只说一句话啊,如果是性能问题,就把最典型的一条语句拿出来看慢在哪里。
相当于重新安装前一版 TiDB,并且还原数据
6.5.3 有什么问题吗?详细说说呢
6.5.3 修复了很多bug,什么场景导致的问题呢?
集群升级成功后, 两个节点一直 掉leader,导致集群一直不稳定,qps下降只有原来的 1/5不到
大量执行语句超时,根本不是一个语句的问题
然后一开始tiflash直接就报错无法使用,经过坛友支持,重装了tiflash节点,恢复正常tiflash访问
现在是集群极不稳定,任何一个sql都可能卡住
生产啊.以为 6.5.3已经是修复版本,结果升级后问题非常严重,人都要快被搞崩溃了
肯定不是某个个sql问题啊, 我这个集群本来qps是 一万左右
现在 ,2000都顶不住了.
有两种方向:
- 找个新环境(用旧的集群版本),把数据弄回去,切换一下就行了
- 整理目前的问题,重点看看那些是致命的问题,在传递上来,让大家一起帮你看
- leader 没了? 是指的什么?
- tiflash 在 6.X 之后的版本,比5.X 的稳定很多,
- CDC 也是一样,甚至重构了… 比之前要稳定…
如果你期望能更快的解决,还是要好好整理下,背景和问题点(虽然你很着急,但是磨刀不误砍柴工,挤牙膏的方式无疑会增加时间成本了)
1.我集群比较大,短时间内没法弄, 总共大概 20T,6KV 2TiFlash
2.
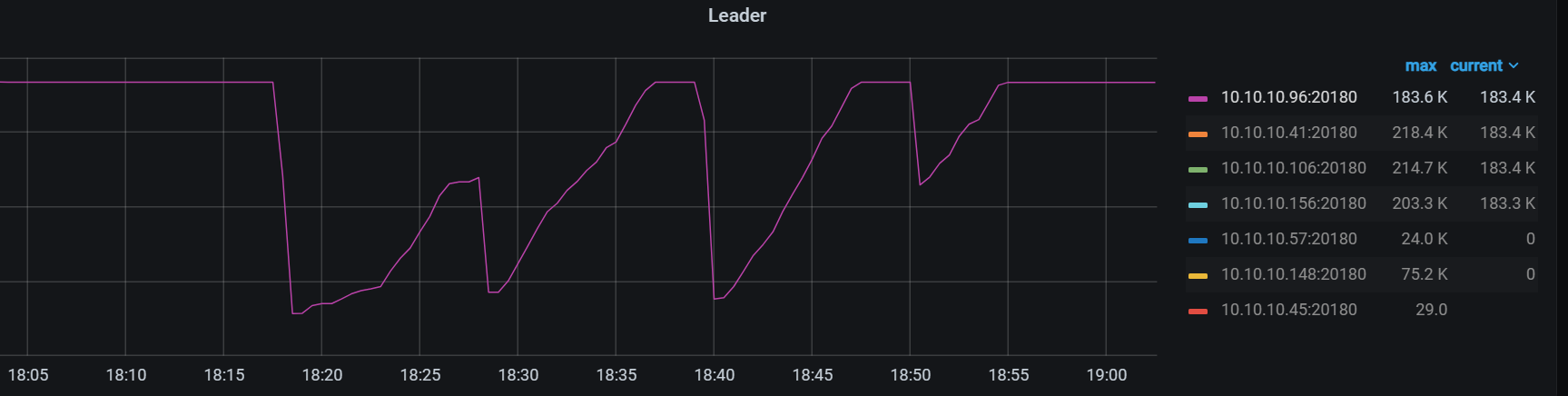
1). 就是某个kv节点leader数会突然从 120K跳到0 ,然后再慢慢恢复到平衡,但是稳定不到五分钟又全部掉,一直循环这个过程
2).我是从6.1.5升级到6.5.3,为了解决一些6.1的问题(具体来说就是cdc性能低下的毛病,看到6.5从4000/s提升到35000/s才下定决心升级的)
3).CDC实际上基本是没法用的,跟论坛其他朋友碰到问题一样,请看别人反馈:
TICDC 向一表一TOPIC分发数据,经常莫名卡死,不再有新的数据写入 - ![]() 建议反馈 / 产品缺陷 - TiDB 的问答社区 (asktug.com) 也没有什么人能给一个明确说法
建议反馈 / 产品缺陷 - TiDB 的问答社区 (asktug.com) 也没有什么人能给一个明确说法
CDC 的这里有个已知的问题,是 CDC 启动或者定时会去收集 kafka 的一些状态和数据信息,用于获取CDC 的性能统计和处理统计等等
但是这个问题没说什么时候修复…
有跳过的办法,需要自己修改源码然后打包 patcher 一下就可以跳过了…
这个问题不确定,是不是你遇到的哪种…

https://github.com/pingcap/tiflow/issues/8959
https://github.com/pingcap/tiflow/issues/8957
region leader 不够均衡的话,可以参考排查总纲对着一点点的看

基本上就是超时了,导致 follower 认为 原来的leader 死掉了,会发起选举,重新选新的leader
https://docs.pingcap.com/zh/tidb/stable/pd-scheduling-best-practices#leaderregion-分布不均衡
具体的操作可以参考下面的:
1 个赞
有没有热点问题?这样也会导致出现一些异常的情况…
建议先关闭 CDC 和 tiflash,保证 tikv,tidb 和 PD 的稳定之后,在逐个开启…
我现在是 6个节点四个稳定, 2个会大量掉.
我就把它设置不启用Leader,这样勉强能跑,
CDC和TiFlash都不能关闭,尤其是TiFlash,业务查询使用tiflash来加速,如果关掉tiflash导致大量大查询落到tikv上,duration都是 5min以上
热点问题. 应该没有明显
有没有什么日志可调查的?
比如我看到有些类似这样的:
023-06-23 19:04:30 (UTC+08:00)
TiKV 10.10.10.156:20160
[cleanup_sst.rs:119] [“get region failed”] [err=“failed to load full sst meta from disk for [242, 148, 145, 51, 128, 141, 72, 6, 165, 188, 254, 164, 106, 120, 179, 243] and there isn’t extra information provided: Engine Engine(Status { code: IoError, sub_code: None, sev: NoError, state: "Corruption: file is too short (0 bytes) to be an sstable: /data/tidb-data/tikv-20160/import/f2949133-808d-4806-a5bc-fea46a78b3f3_4080615702_42367_145285_write.sst" })”]
日志提示这个 /data/tidb-data/tikv-20160/import/f2949133-808d-4806-a5bc-fea46a78b3f3_4080615702_42367_145285_write.sst文件大小是0你检查是不是,感觉这个tikv存储的数据丢了一些