zhimadi
(Zhimadi)
1
【 TiDB 使用环境】生产环境
【 TiDB 版本】v5.4.2
【复现路径】执行缩容tikv节点
tiup cluster scale-in xxx-cluster
tiup cluster display xxx-cluster
tiup cluster prune xxx-cluster
【遇到的问题:问题现象及影响】
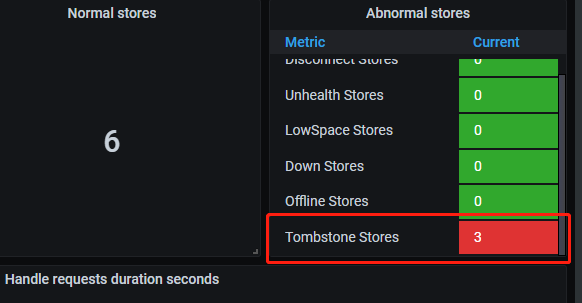
grafana面板还显示有Tombstone Stores 请问是什么原因?会不会有什么影响,要怎么处理掉?
具体路径是Overview->PD->Abnormal stores
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
xfworld
(魔幻之翼)
2
参考下 AI 的处理方式:
当 TiDB 集群缩容后,如果 prometheus 还有残留,可以通过以下步骤进行处理:
- 登录到 prometheus 所在的服务器,找到 prometheus 的数据目录,一般在
data 目录下。
- 找到缩容的 TiDB 实例对应的 prometheus 数据目录,一般以实例的 IP 和端口号命名,如
10.0.0.1-9090。
- 删除该目录下的数据文件,如
data/10.0.0.1-9090/chunks 目录下的所有文件。
- 重启 prometheus 服务,使其重新加载配置文件和数据。
如果 prometheus 仍然存在问题,可以尝试清空 prometheus 的数据目录并重新启动 prometheus 服务。如果问题仍然存在,可以考虑重新部署 prometheus 组件。
redgame
(Ti D Ber Pa Amoi Ul)
3
TiKV节点被标记为“tombstone”状态,则可能说明该节点已经成功缩容并标记为删除状态,但数据删除的过程尚未完成
DBRE
4
这个是历史上处于tomestone的数量,可以忽略
zhimadi
(Zhimadi)
7
所以是正常的数据显示?一直存在的且表示 历史的tomestone数量?
xfworld
(魔幻之翼)
8
DBRE
9
不科学呀?prometheus的数据来源是pd的api,缩容 prometheus再扩容prometheus,pd的数据就变了?
pd-ctl -u http://pd_ip:2379 store remove-tombstone 用这个清理下
DBRE
14
5.2.2 实测,缩容 prometheus再扩容prometheus,tomestone数量仍然维持不变。 
tidb-feng 提供的方式:pd-ctl -u http://pd_ip:2379 store remove-tombstone 可以将tomestone归0
普罗米修斯
16
tiup ctl:v5.4.2 pd -u http://pd:2379 -i
store remove-tombstone
移除
不用ctl 工具也能处理掉,没必要安装ctl工具
curl -X DELETE {pd_leader_ip}:2379/pd/api/v1/stores/remove-tombstone
tombstone 对于集群来说已经毫无意义,对应节点已经没有任何数据,也不能被复用,应该清除