【 TiDB 使用环境】生产环境
【 TiDB 版本】5.2.4
【复现路径】
昨晚园区断电了,断电前停掉了tidb 集群服务,今早开机后tikv 的两个固态硬盘系统报错无法识别,更换卡槽,硬盘卡系统还是识别不到这两块盘,集群拉不起来,Tikv 容量是12t,用了5t,怎么能跳过这两块盘启动tikv ,这种情况应该怎么处理呢。
集群拉不起来,错误信息是什么?
生产还是测试环境,tikv既然是多副本,更改新机器,配置文件重启集群服务


副本数如果够,可以配置下线处理的
直接下线就行 如果不能下线会有提示
tiup cluster scale-in test-cluster --node 192.168.80.202:20160
tiup cluster scale-in test-cluster --node 192.168.80.202:20161
1 个赞

对的。直接下线就行
好的 那我就操作了

专栏 - TiKV缩容下线异常处理的三板斧 | TiDB 社区 看看这个专栏文章
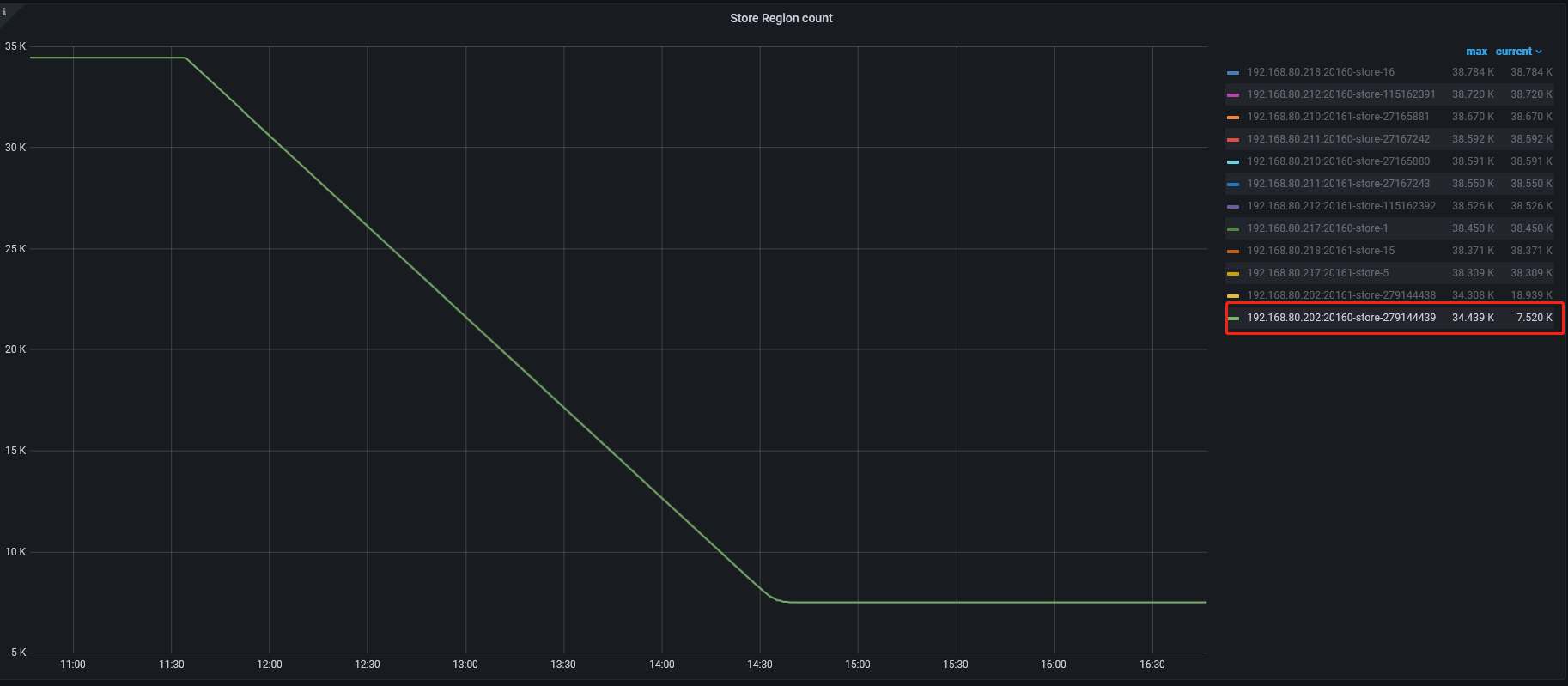
三板斧这篇专栏我看过了 ,我想问下2副本丢失 unsafe-recover remove-fail-stores - --all-regions强制恢复数据会丢吗,会在剩余的1个peer上补全其余副本吗


好的 我问下下线的两个tikv节点,因为磁盘故障了,需要在故障的两个tikv节点上执行unsafe-recover remove-fail-stores命令吗。
还是只在健康的store上执行,故障的tikv节点就正常下线了
是为了处理故障节点的
如果副本数足够,还剩一个副本在其他的 tikv 节点上,会按照均衡的原则进行调度恢复的
目前的情况下,如果两个节点故障,副本数肯定不足, region 会自动平衡恢复的,
我建议你先检查副本数量是否和故障前一致…
确定对数据无影响的情况下,可以在执行 unsafe-recover
理解下您的意思 现在我梳理下没下线的region,如果都处于两个peer在故障的store上,1个peer在正常的store上,我就开始执行unsafe-recover命令。
这个命令在所有正常store上执行,移除依赖的故障peer,移除完成后,下线的两个store就正常转入墓碑模式了。
对,可以按照这篇文档参考执行:
1 个赞
副本数如果够,可以配置下线处理
集群是三副本吗?为什么两个tikv会在一台机器上