【 TiDB 使用环境】生产环境
【 TiDB 版本】v6.1.1
【复现路径】无
【遇到的问题:问题现象及影响】
[1] Firing
Labels
alertname = cdc_processor_checkpoint_tso_no_change_for_1m
一会Resolved 一会又Firing了,一直在不断报警,几分钟一次
【资源配置】
【附件:截图/日志/监控】
查看 ticdc 的 lag监控,Changefeed checkpoint lag 和Changefeed resolved ts lag 断断续续时间挺长
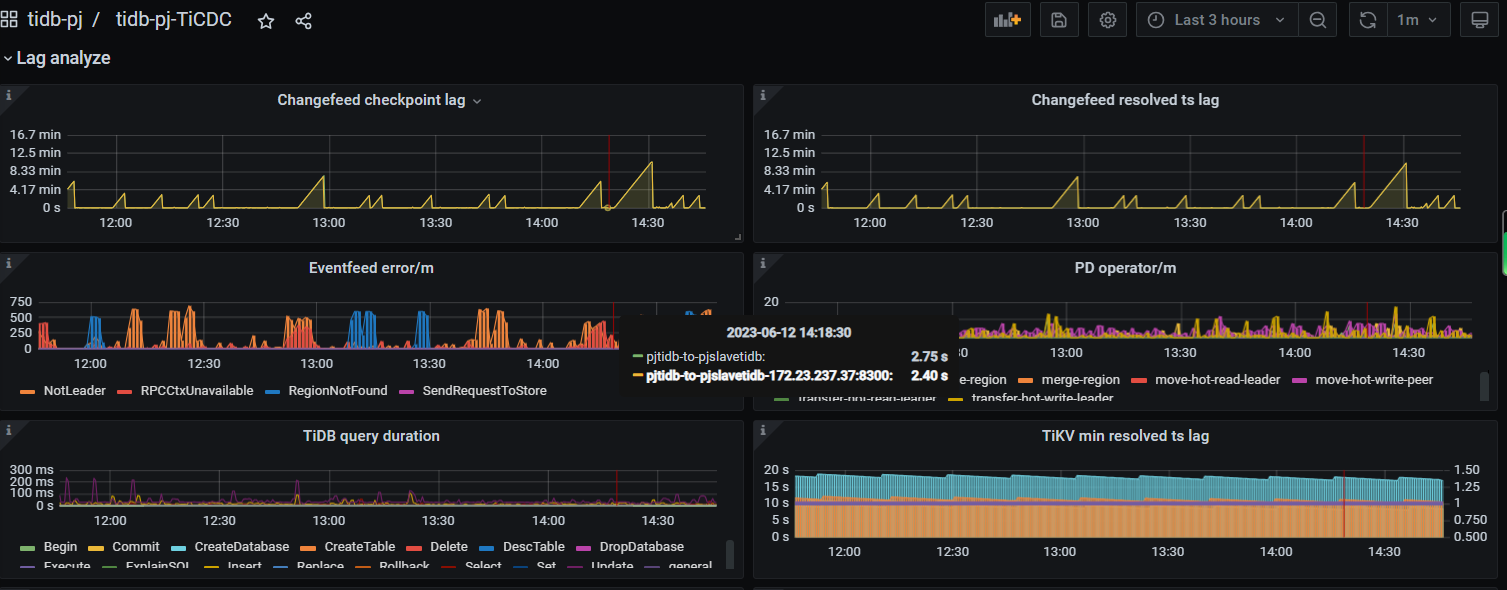
根据您的描述,这个问题可能是由于 TiCDC 的 checkpoint TSO 未发生变化导致的。TiCDC 会定期记录 checkpoint TSO,用于恢复同步任务。如果 checkpoint TSO 未发生变化,可能会导致同步任务无法正常进行。
解决这个问题的方法是,检查 TiCDC 的同步任务是否正常,以及 TiCDC 的监控指标是否正常。您可以按照以下步骤进行操作:
-
检查 TiCDC 的同步任务是否正常。您可以使用 TiCDC 的命令行工具 tiup ctl 或者 PD 的监控面板查看 TiCDC 的同步任务状态。如果同步任务状态正常,可以排除同步任务异常导致的问题。
-
检查 TiCDC 的监控指标是否正常。您可以使用 TiCDC 的监控面板或者 Grafana 监控 TiCDC 的监控指标,例如 checkpoint TSO、resolved TS 等指标,查看是否存在异常波动或者持续不变的情况。
-
如果 TiCDC 的监控指标存在异常,可以尝试重启 TiCDC 节点,或者使用 TiCDC 的动态调整参数功能,逐步调整参数,观察监控指标是否恢复正常。
-
如果 TiCDC 的监控指标正常,但是仍然存在报警,可以尝试调整报警规则,例如调整报警阈值、调整报警时间间隔等,以减少误报。
需要注意的是,TiCDC 的同步任务比较复杂,需要根据具体情况进行分析和解决,建议您在解决问题之前备份好数据,以免数据丢失。同时,建议您在部署 TiCDC 时,根据实际业务情况和硬件配置,合理设置 TiCDC 的参数,以避免同步任务异常或者监控指标异常等问题。
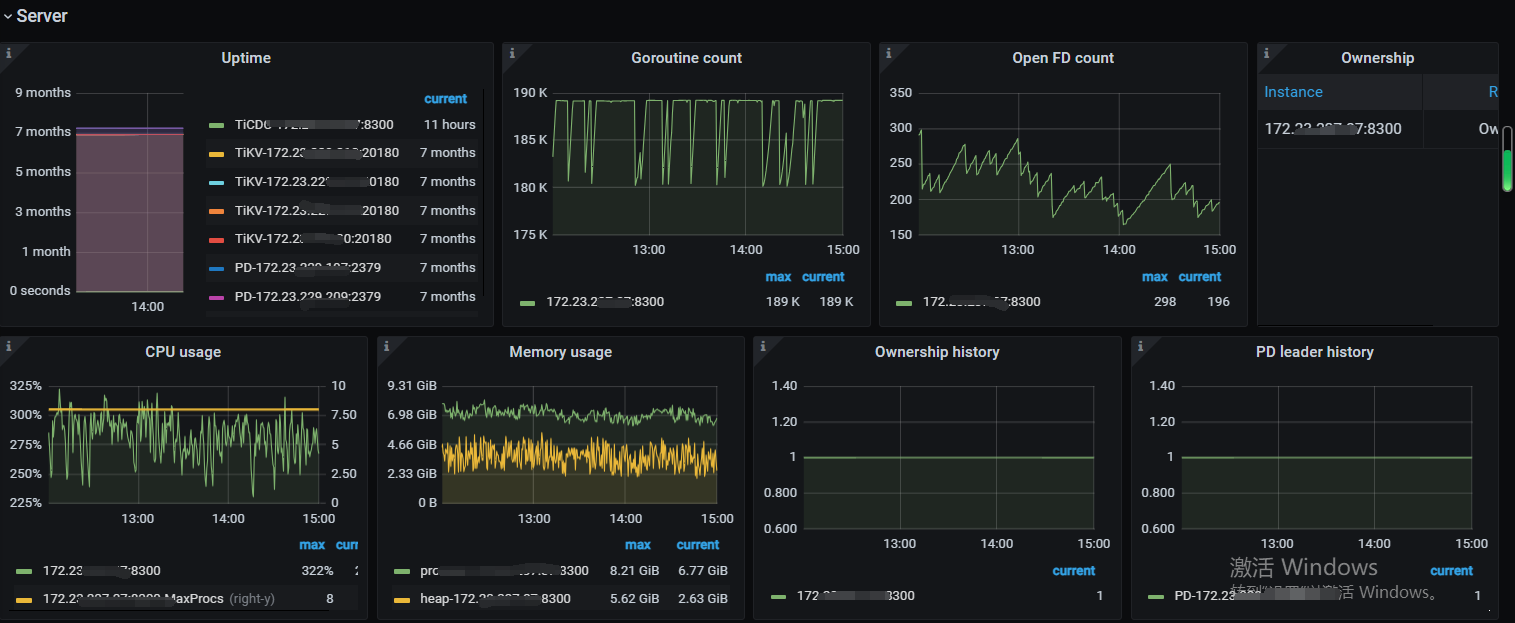
我看我的cdc机器负载不高,cpu,内存没到一半,
请把 dataflow 那个监控项对应时间段的监控也贴一下,即含有 puller ,sorter, sink output events /s 的指标。
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。