Zhang_Zhi
(Hacker B7 E2pqi5)
1
【 TiDB 使用环境】生产环境,3tidb,3pd,8tikv
【 TiDB 版本】v4.0.11
【复现路径】故障时无特殊操作
【遇到的问题:问题现象及影响】
读写超时,响应慢
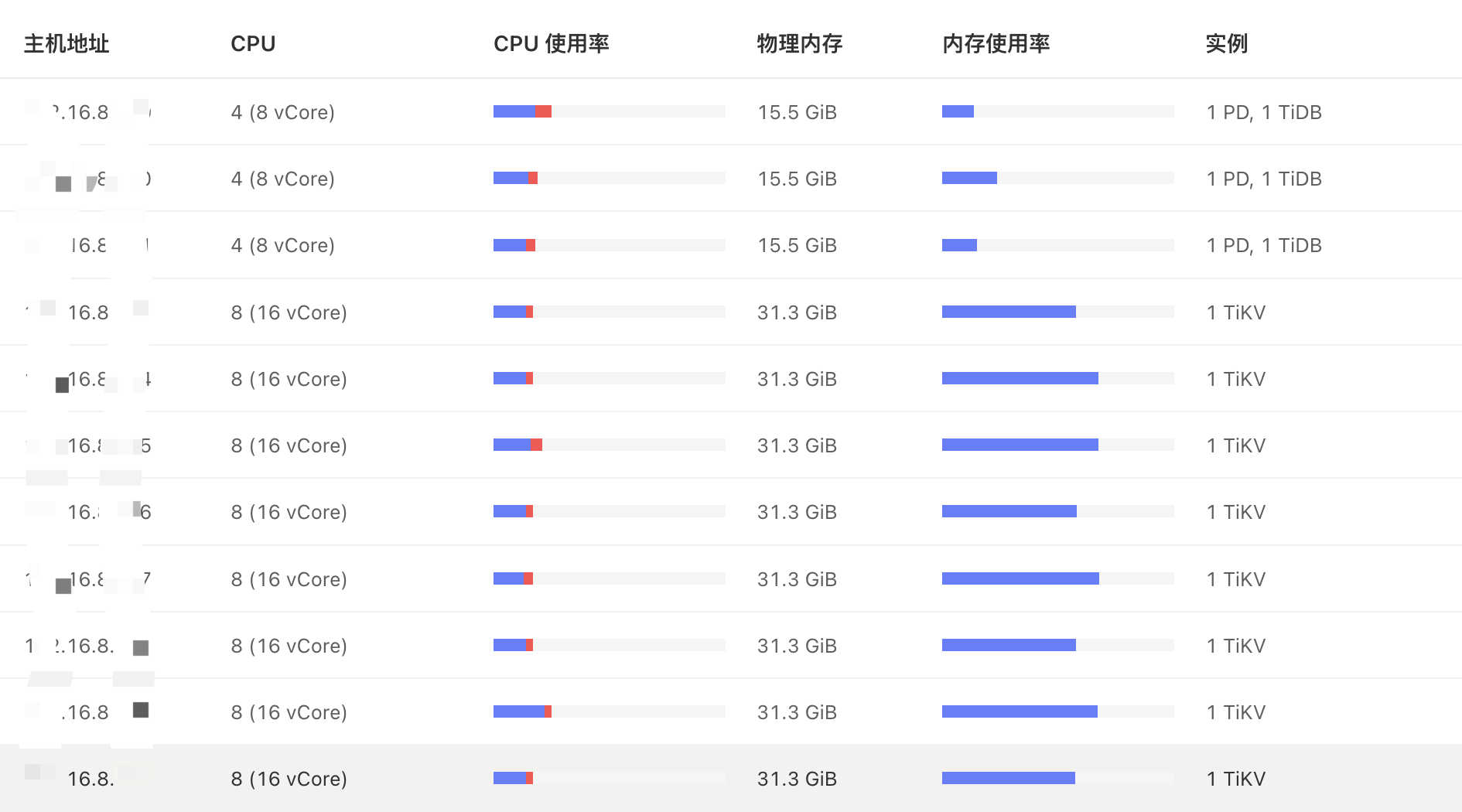
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
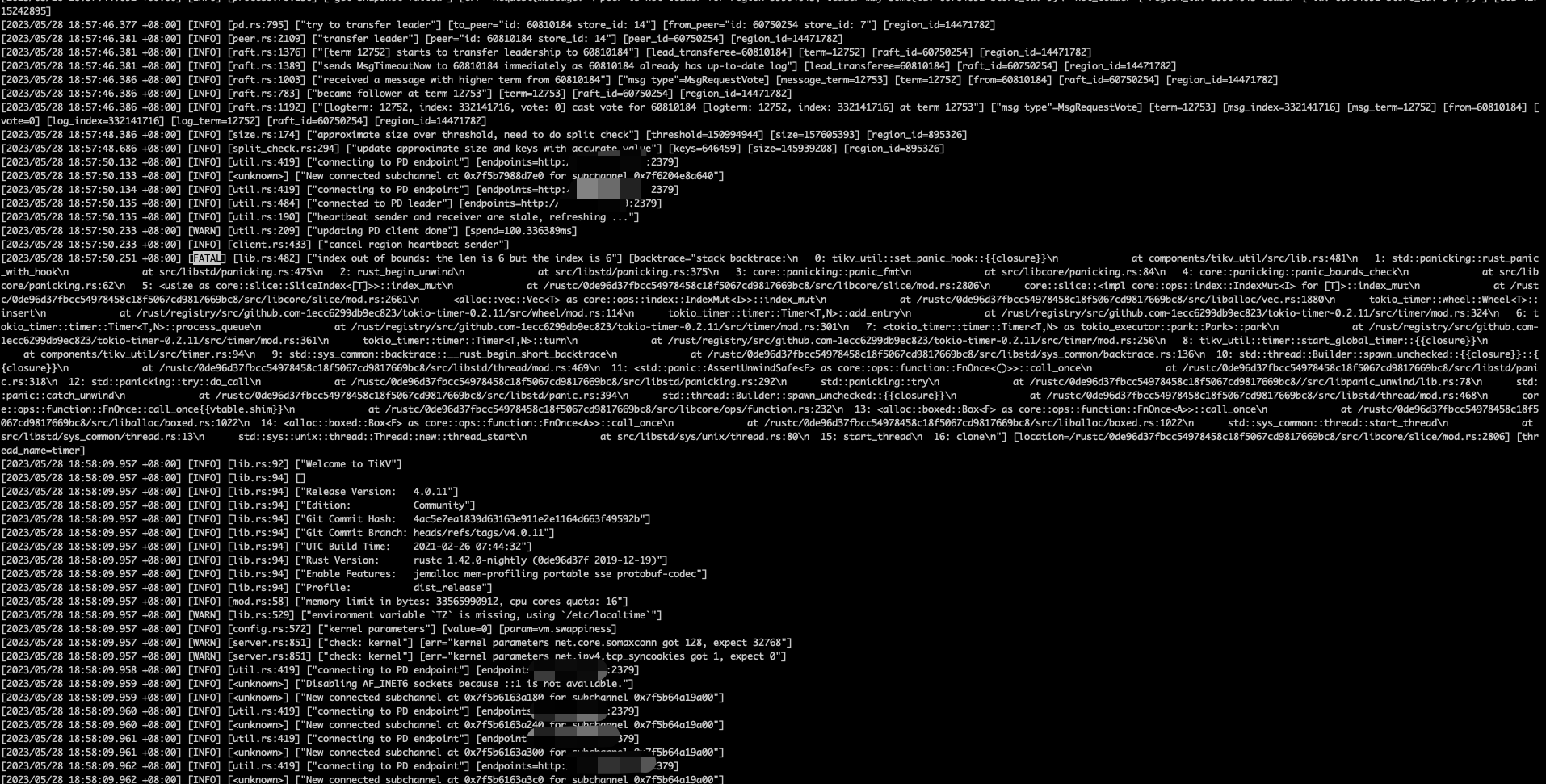
第一台tikv发生FATAL报错的日志截图
8个tikv,共有4台出现这个FATAL报错。
出现报错的时间节点分别为
[2023/05/28 18:57:50.251 +08:00]
[2023/05/28 18:57:51.442 +08:00]
[2023/05/28 18:59:46.938 +08:00]
[2023/05/28 19:00:38.893 +08:00]
Zhang_Zhi
(Hacker B7 E2pqi5)
5
页面打开404
你说的是这个吗?
但这个是4.0.11版本的 Release Notes,我当前版本就是4.0.11
这里的 index 是数组越界了,不是 索引问题;
至于你说的 tidb_rowid 的 那个错误,是 tidb 的问题,不是 tikv 的;所以这两个不是一个事情;
tidb 有好多 index out of range,所以这个问题基本随缘;如果经常碰到,可以考虑升级
Zhang_Zhi
(Hacker B7 E2pqi5)
8
目前也不知道这种数组越界在哪个版本修复了,升级到5.0的一个稳定版本?
h5n1
(H5n1)
9