【 TiDB 使用环境】生产环境
【 TiDB 版本】6.1.1
【复现路径】做过哪些操作出现的问题
两台服务器 每台服务器3个tikv 节点,不定时写入数据库数据失败,提示(8027, ‘Information schema is out of date: schema failed to update in 1 lease, please make sure TiDB can connect to TiKV’),后来发现是有tikv节点重启了
【遇到的问题:问题现象及影响】
【资源配置】
【附件:截图/日志/监控】
日志只有重启的两个tikv.zip (4.9 MB)
TiDB Dashboard Diagnosis Report.html (883.0 KB)
kv节点有日志吗
你好已更新日志,我是入门都不算的哈,公司要去ioe化,搭建的tidb集群。这个集群原来是4台服务器(一台虚拟机+3台浪潮海光物理机),之前就是服务器老宕机,现象是大数据写入时granfa显示io一直100%,过一段时间就系统宕机。后来感觉是机器的机械盘5400转的性能不行,就增加了俩华为的服务器,把tikv都放在了俩华为服务器上,每个机器6个kv,也是机械盘不过是万转的比之前的的好些,但是最近也是出现kv重启。
机械盘不太行,分布式数据库io要求比普通数据库高多了,得上sss,最好是nvme的
有什么参数或者设置可以做吗,允许慢但是稳定别重启就行?
看下系统日志呢?是不是发生了oom导致了重启,或者是看下grafana 监控看下重启节点的内存使用情况
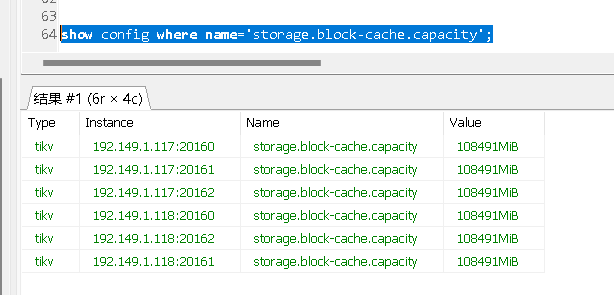
storage.block-cache.capacity看看tikv 的每个节点这个参数设置多少,另外看下3个tikv节点合用的主机的内存多少,做了numa资源隔离没有?
[root@tidb-118 ~]# free -h
\ total used free shared buff/cache available
Mem: 251G 247G 704M 327M 3.1G 2.7G
Swap: 0B 0B 0B
f[root@tidb-117 ~]# free -h
total used free shared buff/cache available
Mem: 251G 239G 859M 391M 10G 10G
Swap: 0B 0B 0B
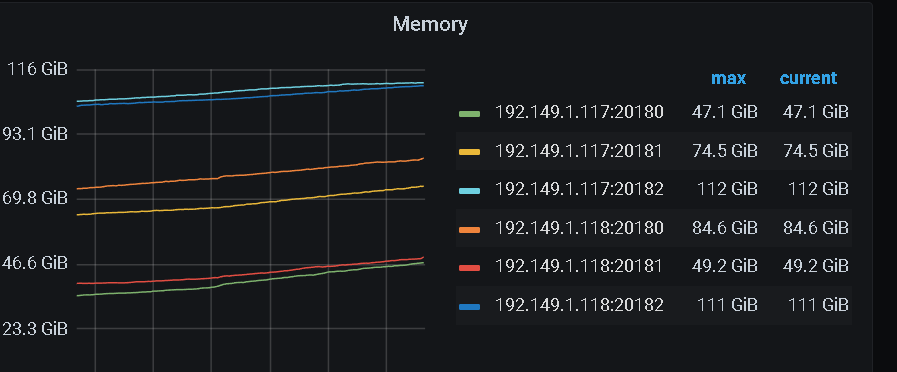
两台服务器内存几乎用满了
你这个肯定有问题,你一个机器才256G内存,一台机器上三个tikv节点,那每个tikv节点的storage.block-cache.capacity应该设置为256/3*0.45=38.4G,比较 合理,例外可以通过tiup cluster edit-config cluster_name 指定每个tikv绑定一个numa节点,这样可以防止3个节点产生资源争用
now.config (7.8 KB) 集群配置已上传[root@tidb-118 ~]# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 40
On-line CPU(s) list: 0-39
Thread(s) per core: 2
Core(s) per socket: 10
座: 2
NUMA 节点: 2
厂商 ID: GenuineIntel
CPU 系列: 6
型号: 85
型号名称: Intel(R) Xeon(R) Silver 4114 CPU @ 2.20GHz
步进: 4
CPU MHz: 2499.975
CPU max MHz: 3000.0000
CPU min MHz: 800.0000
BogoMIPS: 4400.00
虚拟化: VT-x
L1d 缓存: 32K
L1i 缓存: 32K
L2 缓存: 1024K
L3 缓存: 14080K
NUMA 节点0 CPU: 0-9,20-29
NUMA 节点1 CPU: 10-19,30-39 这俩物理机都只有2个numa节点,分给三个tikv是不是不行,再加一个服务器,每台两个tikv就可以了嘛?
对,一般不建议一台机器部署多台tikv,机器是在紧张的话,可以部署两个,然后numa一个绑0一个绑1,先隔离内存和cpu,然后最好两个tikv挂载在不同的磁盘上,隔离io,这样才能尽量不让两个tikv之间互相影响。
目前感觉是解决了,应该是storage.block-cache.capacity 设置100G oom了,改小了目前还没出现重启。
storage.block-cache.capacity
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。