部署情况如下:
共6台服务器
3台服务器部署tidb、pd,各3个实例
3台服务器部署tikv(每台服务器3个实例)、tiflash(每台服务器1个实例),共9个tikv、3个tiflash
服务器配置:Hygon G5 7285(2.0GHz/ 32核 /64MB/190W)×2 + 512G内存
使用
dmesg -T | grep tidb-server或dmesg -T | grep oom
查看kv服务器可以看到每天每隔1到3小时就会出现kv服务oom后重启的现象。
tikv_stderr.log 日志为空
已经按512G内存/4的一半来配置全局 storage.block-cache.capacity: 62GB
全局配置如下:
tikv:
readpool.storage.use-unified-pool: false
readpool.coprocessor.use-unified-pool: true
storage.block-cache.capacity: 62GB
raftstore.apply-pool-size: 3
raftstore.store-pool-size: 3
server.grpc-concurrency: 8
单台tikv配置如下:
tikv_servers:
- host: 192.168.1.64
ssh_port: 22
port: 20160
status_port: 20180
deploy_dir: "/data/1/tidb-deploy/tikv-20160"
data_dir: "/data/1/tidb-data/tikv-20160"
log_dir: "/data/1/tidb-deploy/tikv-20160/log"
numa_node: "0"
config:
server.labels:
host: tikv64
- host: 192.168.1.64
ssh_port: 22
port: 20161
status_port: 20181
deploy_dir: "/data/2/tidb-deploy/tikv-20161"
data_dir: "/data/2/tidb-data/tikv-20161"
log_dir: "/data/2/tidb-deploy/tikv-20161/log"
numa_node: "1"
config:
server.labels:
host: tikv64
- host: 192.168.1.64
ssh_port: 22
port: 20162
status_port: 20182
deploy_dir: "/data/3/tidb-deploy/tikv-20162"
data_dir: "/data/3/tidb-data/tikv-20162"
log_dir: "/data/3/tidb-deploy/tikv-20162/log"
numa_node: "2"
config:
server.labels:
host: tikv64
Grafana->TiKV-Detail->RocksDB-KV->Block Cache Size 面板如下:
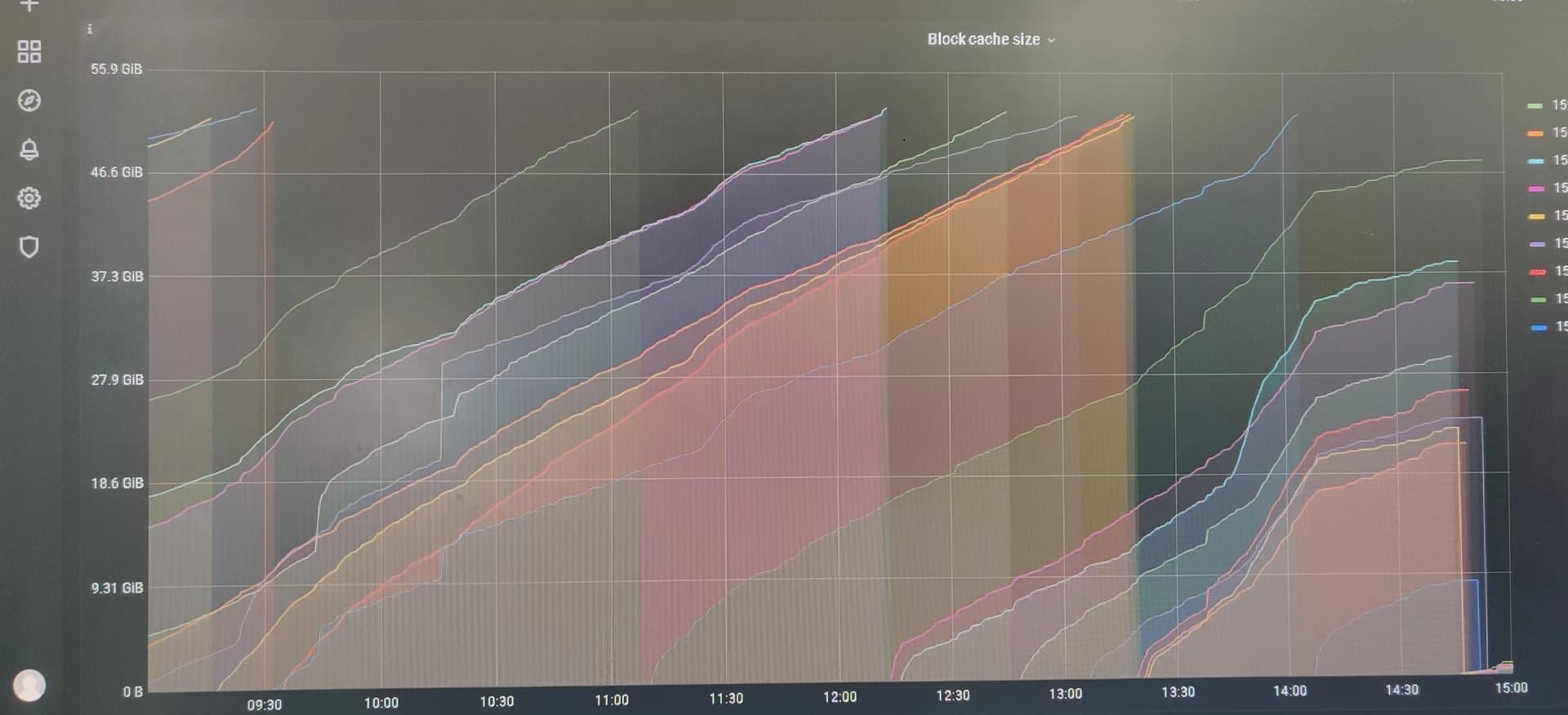
各tikv实例的max都没有达到设定的62GB