【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】6.5
【遇到的问题:问题现象及影响】
公司计划将mysql迁移至TiDB,目前正在研究阶段,部署的方式是参考的官方文档,配置如下
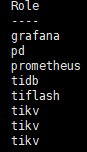
虚拟机硬件配置均为2cpu,16G内存,500G硬盘
目前已经通过DM将数据库(大小25G)迁移至TiDB
但仅在执行简单select查询方面,性能均比mysql慢
就没有发现一个比MYSQL快的
烦请指教,谢谢!
【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】6.5
【遇到的问题:问题现象及影响】
公司计划将mysql迁移至TiDB,目前正在研究阶段,部署的方式是参考的官方文档,配置如下
目前已经通过DM将数据库(大小25G)迁移至TiDB
但仅在执行简单select查询方面,性能均比mysql慢
就没有发现一个比MYSQL快的
烦请指教,谢谢!
sql 还有执行计划贴出来
SELECT
ddi.id
FROM
dw_declare_info ddi
WHERE
ddi.del_flag = ‘0’
AND NOW() < ddi.end_time
AND ddi.audit_status != 0
AND ddi.audit_status != 3
AND ddi.audit_time BETWEEN ‘2023-05-02 00:00:00.0’
AND ‘2023-05-03 00:00:00.0’
AND ddi.identity NOT IN (
SELECT
black_value
FROM
black_info_new
WHERE
exist_or_not = 0
)
ORDER BY
ddi.update_time DESC
LIMIT
0, 10;
| id | task | estRows | operator info | actRows | execution info | memory | disk | |
|---|---|---|---|---|---|---|---|---|
| Projection_12 | root | 10 | shihua_center.dw_declare_info.id | 10 | time:1.73s, loops:2, Concurrency:OFF | 760 Bytes | N/A | |
| └─TopN_15 | root | 10 | shihua_center.dw_declare_info.update_time:desc, offset:0, count:10 | 10 | time:1.73s, loops:2 | 15.4 KB | N/A | |
| └─HashJoin_20 | root | 53.38 | CARTESIAN anti semi join, other cond:eq(shihua_center.dw_declare_info.identity, shihua_center.black_info_new.black_value) | 561 | time:1.73s, loops:2, build_hash_table:{total:70.3ms, fetch:69.4ms, build:875µs}, probe:{concurrency:5, total:4.68s, max:1.73s, probe:996.4ms, fetch:3.68s} | 505.7 KB | 0 Bytes | |
| ├─TableReader_30(Build) | root | 8332 | data:Selection_29 | 8332 | time:69.5ms, loops:10, cop_task: {num: 6, max: 18ms, min: 1.81ms, avg: 11.6ms, p95: 18ms, max_proc_keys: 480, p95_proc_keys: 480, rpc_num: 6, rpc_time: 69.7ms, copr_cache_hit_ratio: 0.83, distsql_concurrency: 15} | 120.8 KB | N/A | |
| │ └─Selection_29 | cop[tikv] | 8332 | eq(shihua_center.black_info_new.exist_or_not, 0) | 8332 | tikv_task:{proc max:84ms, min:0s, avg: 26.2ms, p80:38ms, p95:84ms, iters:34, tasks:6}, scan_detail: {total_process_keys: 480, total_process_keys_size: 84068, total_keys: 481, get_snapshot_time: 78.7µs, rocksdb: {key_skipped_count: 480, block: {cache_hit_count: 11}}} | N/A | N/A | |
| └─TableReader_23(Probe) | root | 66.72 | data:Selection_22 | 561 | time:736.5ms, loops:2, cop_task: {num: 14, max: 735.8ms, min: 5.76ms, avg: 394.4ms, p95: 735.8ms, max_proc_keys: 303626, p95_proc_keys: 303626, tot_proc: 5.41s, tot_wait: 1ms, rpc_num: 14, rpc_time: 5.52s, copr_cache_hit_ratio: 0.00, distsql_concurrency: 15} | 39.1 KB | N/A | |
| └─Selection_22 | cop[tikv] | 66.72 | eq(shihua_center.dw_declare_info.del_flag, 0), ge(shihua_center.dw_declare_info.audit_time, 2023-05-02 00:00:00.000000), le(shihua_center.dw_declare_info.audit_time, 2023-05-03 00:00:00.000000), lt(2023-05-24 10:33:26, shihua_center.dw_declare_info.end_time), ne(shihua_center.dw_declare_info.audit_status, 0), ne(shihua_center.dw_declare_info.audit_status, 3) | 561 | tikv_task:{proc max:734ms, min:4ms, avg: 386.5ms, p80:657ms, p95:734ms, iters:2554, tasks:14}, scan_detail: {total_process_keys: 2552222, total_process_keys_size: 1017786960, total_keys: 2552236, get_snapshot_time: 251.5µs, rocksdb: {key_skipped_count: 4625694, block: {cache_hit_count: 17053}}} | N/A | N/A | |
| └─TableFullScan_21 | cop[tikv] | 2550943 | table:ddi, keep order:false | 2552222 | tikv_task:{proc max:661ms, min:4ms, avg: 340.4ms, p80:561ms, p95:661ms, iters:2554, tasks:14} | N/A | N/A |
ddi 都全部扫描了,加上时间字段索引。再说,你的配置也太低了吧,按照官网的配置拉部署吧
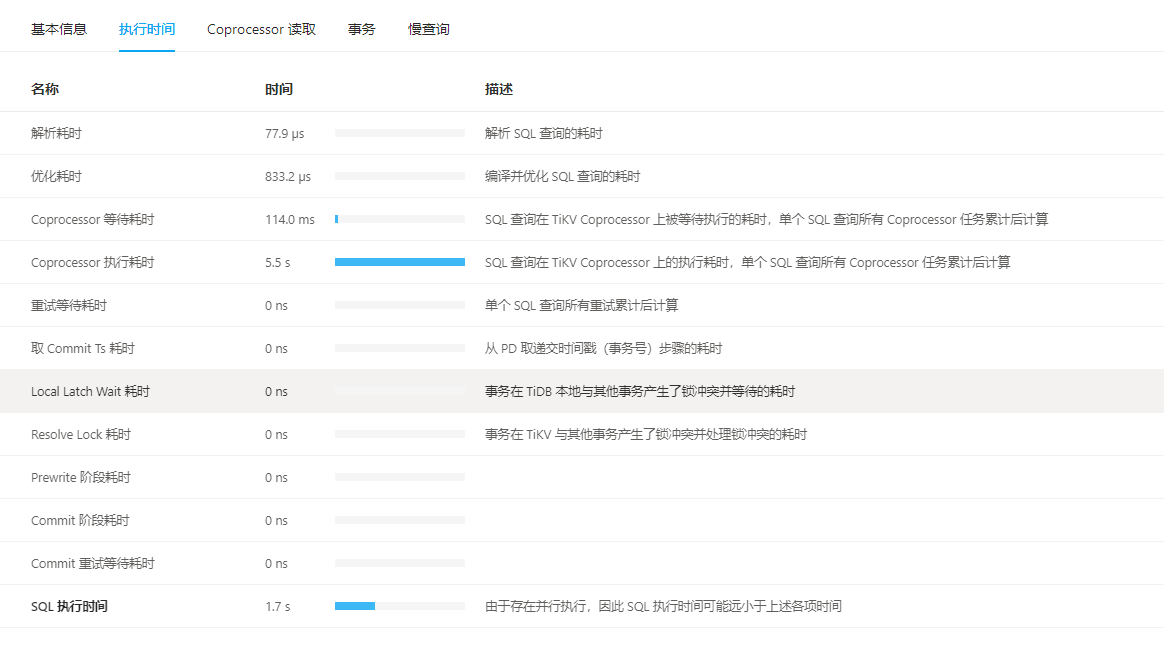
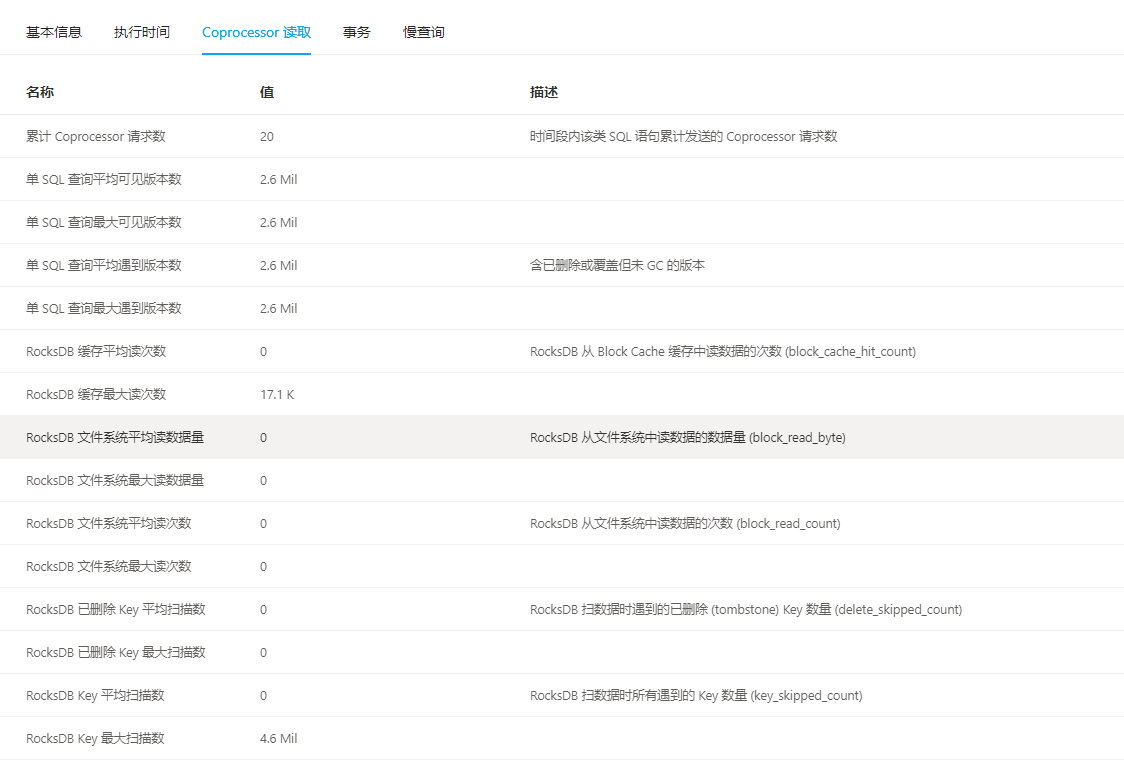
就是很奇怪查询效率比mysql低太多了 ,数据库是直接从mysql同步过来的,表设计索引都一样,但是这个在mysql执行最快只需要0. 1秒,TiDB却要1.7以上秒 ,跟服务器配置有关系吗,是一台服务器上分配出来的七台虚拟机部署的
TiDB 设计的目标就是针对 MySQL 单台容量限制而被迫做的分库分表的场景,或者需要强一致性和完整分布式事务的场景。它的优势是通过尽量下推到存储节点进行并行计算。对于小表(比如千万级以下),不适合 TiDB,因为数据量少,Region 有限,发挥不了并行的优势。其中最极端的例子就是计数器表,几行记录高频更新,这几行在 TiDB 里,会变成存储引擎上的几个 KV,然后只落在一个 Region 里,而这个 Region 只落在一个节点上。加上后台强一致性复制的开销,TiDB 引擎到 TiKV 引擎的开销,最后表现出来的就是没有单个 MySQL 好。
同时tidb如果混合部署的话,不做资源隔离,性能会更差劲,远不如在同一个物理机上部署一个单节点mysql效率高。。。
SELECT
ddi.id
FROM
dw_declare_info ddi
WHERE
ddi.del_flag = ‘0’
AND now() < ddi.end_time
AND ddi.audit_status != 0
AND ddi.audit_status != 3
AND ddi.audit_time BETWEEN ‘2023-05-02 00:00:00.0’
AND ‘2023-05-03 00:00:00.0’
AND ddi.identity NOT IN ( SELECT black_value FROM black_info_new WHERE exist_or_not = 0 )
ORDER BY
ddi.update_time DESC
LIMIT 0,10
有了新的发现:就这个语句如果不加最后一句 LIMIT 0,10,mysql和TIDB的查询时间都在1.7左右
如果加了LIMIT 0,10,MySQL就只需要0.1,TiDB还是1.7,头疼了不知道为啥 ![]() ,大佬救命!
,大佬救命!
mysql 是单机,取数据的话只需要在一台机器上取数据就可以了,tidb 是分布式的,每一台tikv节点都需要做一次取数,然后汇总到tidb-server 上,不知道我这样理解对不对,
但是每一台tikv节点都是并行的
但是这个差异也有点太大了,按理说数据量小的就算是通过TiDB也应该跟mysql差不了多少
LIMIT 0,10这种sql,对于mysql来说,只要简单的获取前10条数据即可,但是对于tidb来说,每个tikv节点的数据都是不可预测的,需要全量返回给tidb,在tidb层汇总数据对对应字段排序后,取出前10条才可以
加与不加TiDB的时间都是1.7s,反而是mysql不加也在1.7左右,加了就0.1了
对于TiDB来说,我查询表所有数据和只查询10条是一样的时间
慢是正常的,你配置内存太小了,tidb远比mysql吃内存,另外集群单个sql语句一般比单机数据库慢一些
没毛病啊,tidb处理这种排序LIMIT 0,10确实效率和不加区别不大,但是返回到你的客户端数据量级有差别,mysql直接在内存排序就优化过了,所以会快一点,但是如果表数量级上来了,例如是一个10亿级别的表,你用单mysql肯定不如tidb多节点。
反半连接情况下,如果关联字段定义可以允许null就会在内部按照笛卡尔积执行,效率较低。建议关联字段设置为not null再看看。