【 TiDB 使用环境】模拟单节点TiKV在特殊情况下的灾难恢复情况
【 TiDB 版本】TiKV v6.1.0
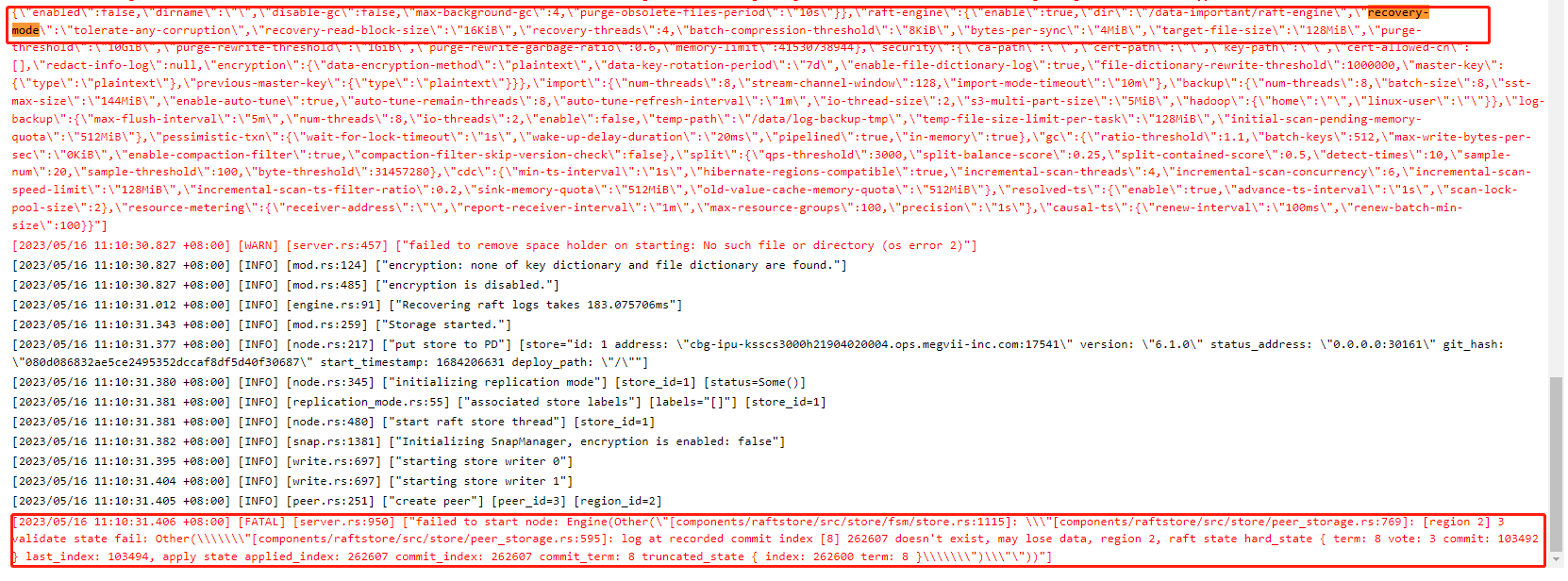
【复现路径】修改TiKV 配置recovery-mode为“tolerate-any-corruption”,重启TiKV,往TiKV中入一些数据后,停止入数据,truncate raftlog,重启tikv,tikv启动失败
【遇到的问题:问题现象及影响】TiKV重启失败,报错 “[FATAL] [server.rs:950] [“failed to start node: Engine(Other(“[components/raftstore/src/store/fsm/store.rs:1115]: "[components/raftstore/src/store/peer_storage.rs:769]: [region 2] 3 validate state fail: Other(\"[components/raftstore/src/store/peer_storage.rs:595]: log at recorded commit index [8] 262607 doesn’t exist, may lose data, region 2, raft state hard_state { term: 8 vote: 3 commit: 103492 } last_index: 103494, apply state applied_index: 262607 commit_index: 262607 commit_term: 8 truncated_state { index: 262600 term: 8 }\")"”))”]”
【附件:截图/日志/监控】
这么玩,会把自己玩死。
我认为这是常见的灾难恢复场景,你不会没遇到过断电文件损坏的情况吧
这种的话,我认为只能拿备份文件去恢复了。直接启动肯定报错。
贴主怎么解决的?分享一下
本来以为TiKV的配置项 recovery-mode 设为 “tolerate-any-corruption”就是处理这种情况的,实验了几次都是失败,还不知道咋搞呢
1 个赞
同问:默认是 tolerate-tail-corruption 这个有问题吗、
## Determines how to deal with file corruption during recovery.
##
## Candidates:
## absolute-consistency
## tolerate-tail-corruption
## tolerate-any-corruption
# recovery-mode = "tolerate-tail-corruption"
可以自测一下,我的结果是不行
好的。业务人员 研究一下 日志恢复过程
后面自测发现,默认配置 tolerate-tail-corruption 是允许最新raftlog丢失 512k的数据。tolerate-any-corryption 容忍丢失1.5M的数据
如果可以接受部分数据丢失的话,可以考虑用 unsafe recovery
因为在异常情况下,可能会导致 region 的 raft 状态不一致,通过 unsafe recovery 可以修复数据、恢复正常;但是,可能会导致部分数据丢失
参考这里: https://docs.pingcap.com/zh/tidb/v7.0/online-unsafe-recovery#online-unsafe-recovery-使用文档
单节点,还丢了raftlog,这不相当于把wal日志删一些吗。丢数据是必然的。如果想有损恢复,看看楼上的unsafe recovery是不是好使吧。
这是手工修复 和redis命令一样。。另外提供修复文件系统来恢复raftlog也可以
这个unsafe recover实际上是删除了不可用的节点,让剩余的节点重新分配region并提供服务。在单机的情况下并不适用。
很是极限啊