tidb 5.0.3
执行命令:
tiup cluster scale-in tidb-fin-app --node xxx.xxx.xxx.xxx:20160
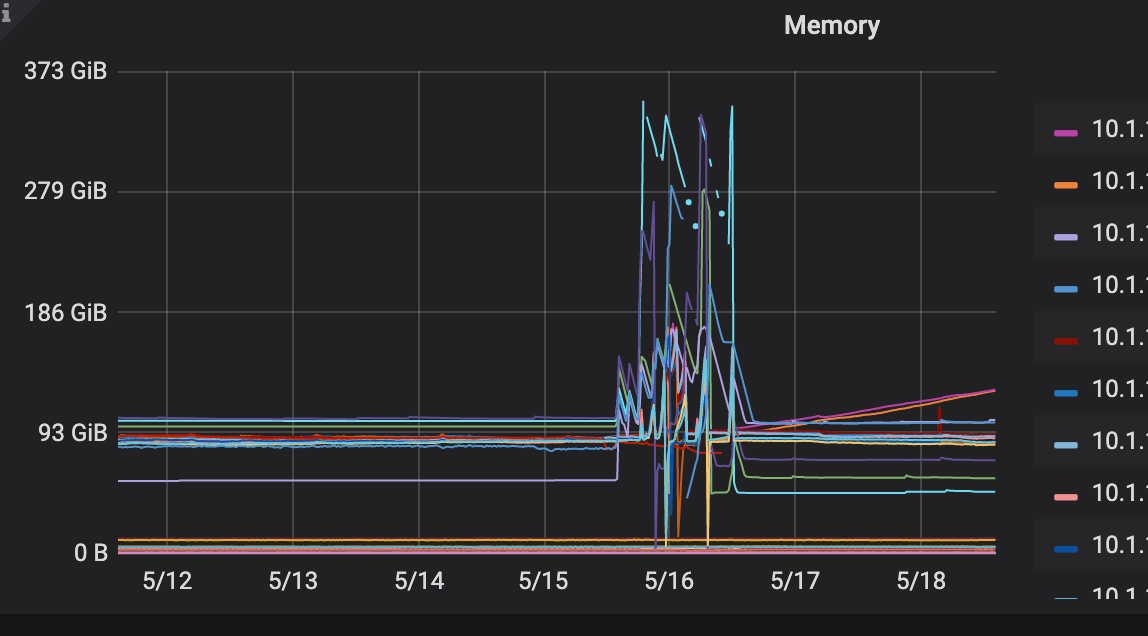
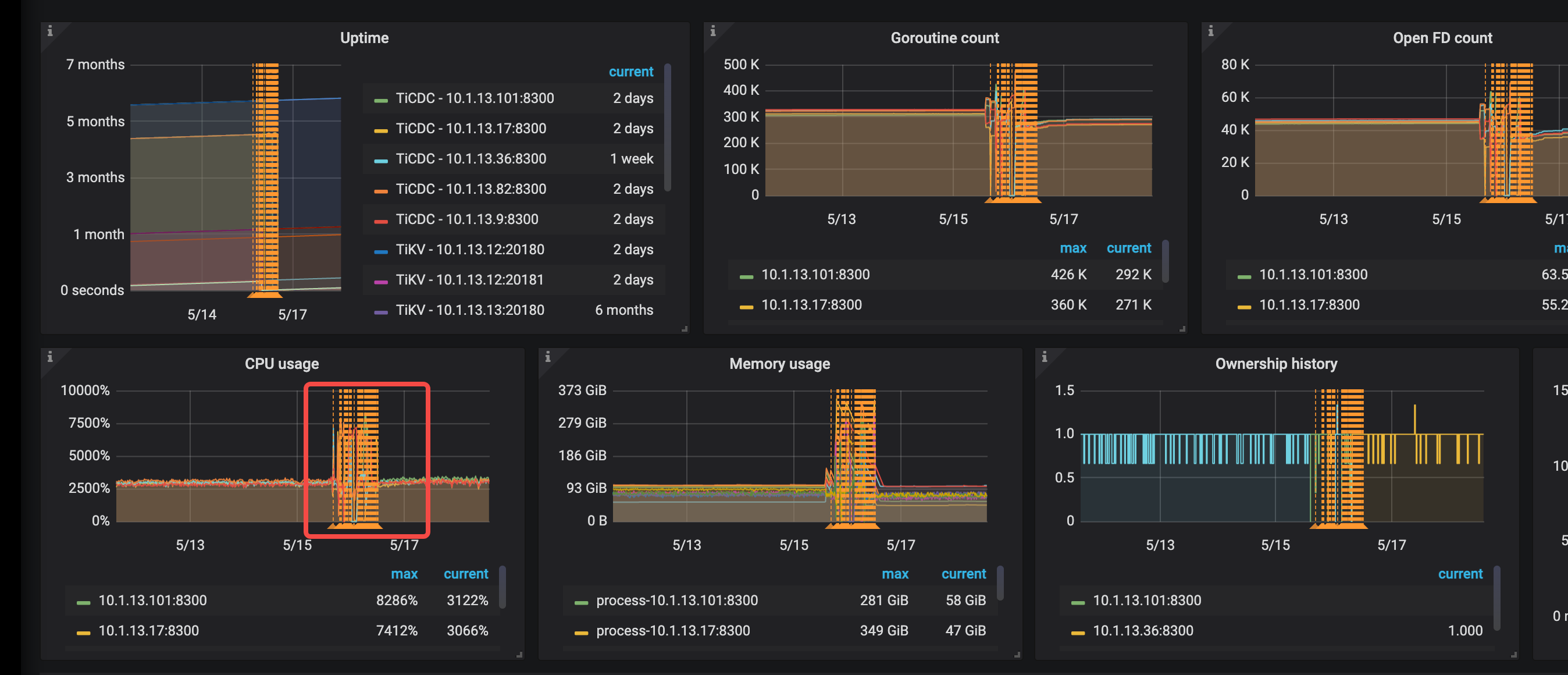
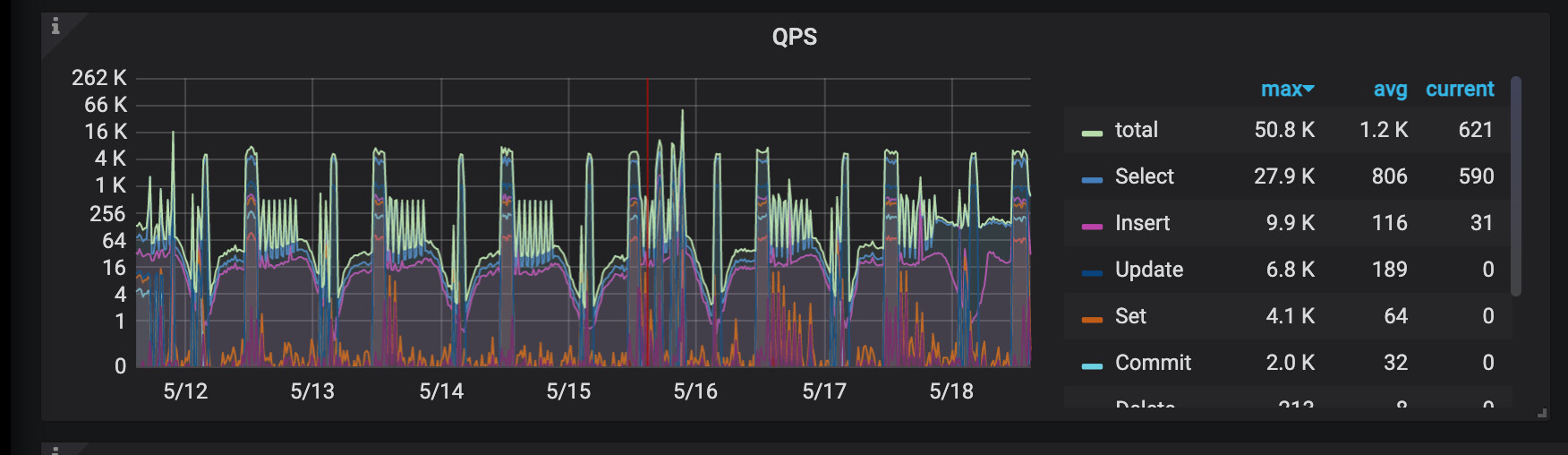
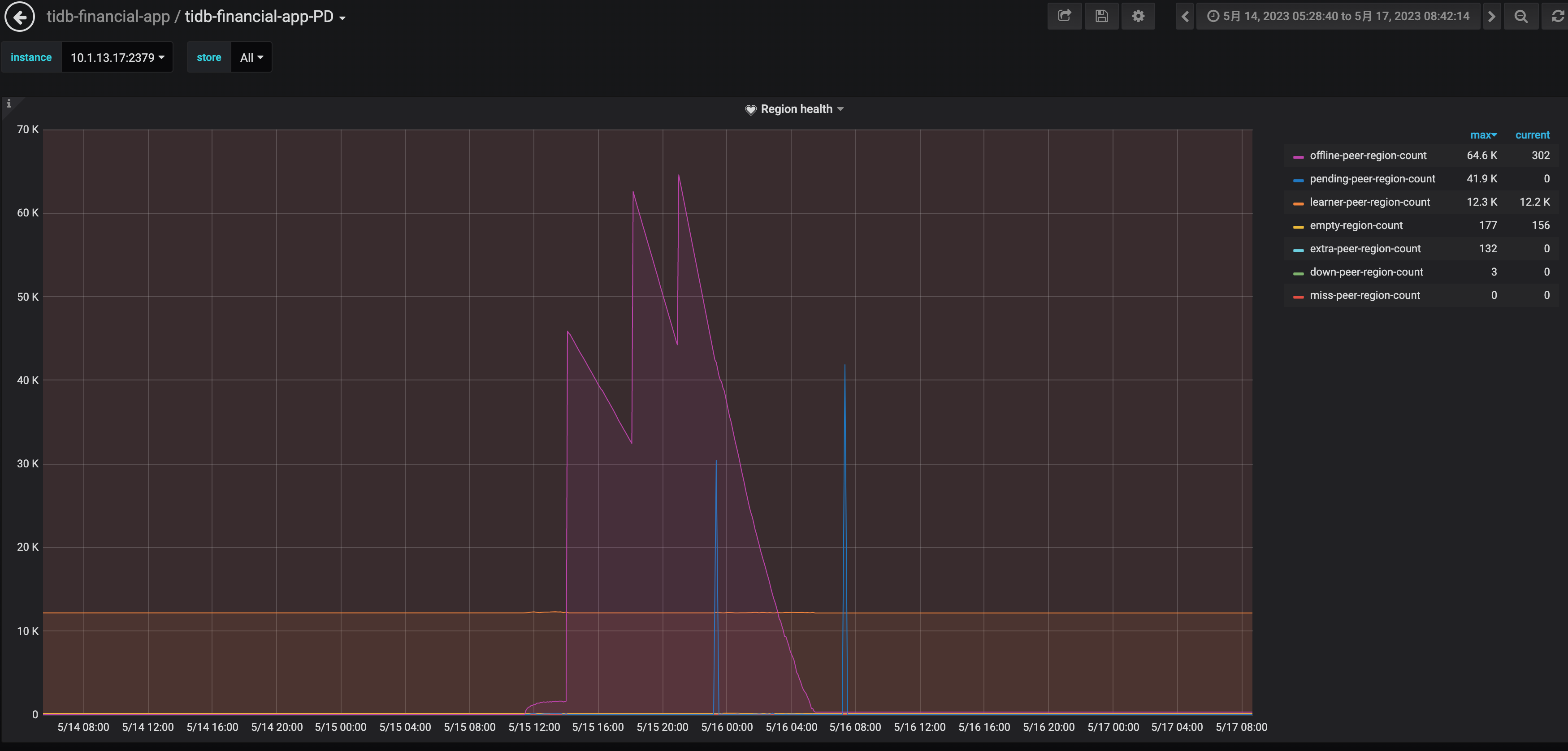
先扩了两个tikv节点(一台机器上混部2个tikv),扩完后, 准备然后下掉两个tikv节点(一台机器上混部2个tikv),下掉第一个的过程中,集群抖动厉害, 有4,5台tikv节点 发生OOM ,重启了。 还有这个集群有CDC 节点,同步到kafka的任务。 cdc cpu,mem压力很大。 tidb的QPS 高峰是 4k到 1.6w 左右
之前其他tidb集群做节点 下线,很平稳,没有感知,没见有啥抖动。 不知道为啥这次抖动这么严重。
这种情况可能是由于下线 TiKV 节点时,TiDB 集群的数据迁移和调度导致的。在下线 TiKV 节点时,TiDB 集群会自动将该节点上的数据迁移到其他节点上,这个过程可能会导致 TiDB 集群的负载增加,从而导致 TiDB 集群的抖动和 TiKV 节点的 OOM。
为了避免这种情况,建议在下线 TiKV 节点之前,先将该节点上的数据迁移到其他节点上,然后再下线该节点。可以使用 TiUP 工具来进行 TiKV 节点的下线和数据迁移操作,具体操作可以参考 TiUP 的文档。
此外,如果 TiDB 集群的 QPS 高峰达到 1.6w 左右,建议对 TiDB 集群进行水平扩展,增加 TiDB 节点的数量,以提高 TiDB 集群的性能和稳定性。同时,也可以考虑对 TiKV 节点进行水平扩展,增加 TiKV 节点的数量,以提高 TiKV 集群的性能和稳定性。
我是用正常的tiup 工具 缩容的
tiup cluster scale-in tidb-fin-app --node xxx.xxx.xxx.xxx:20160
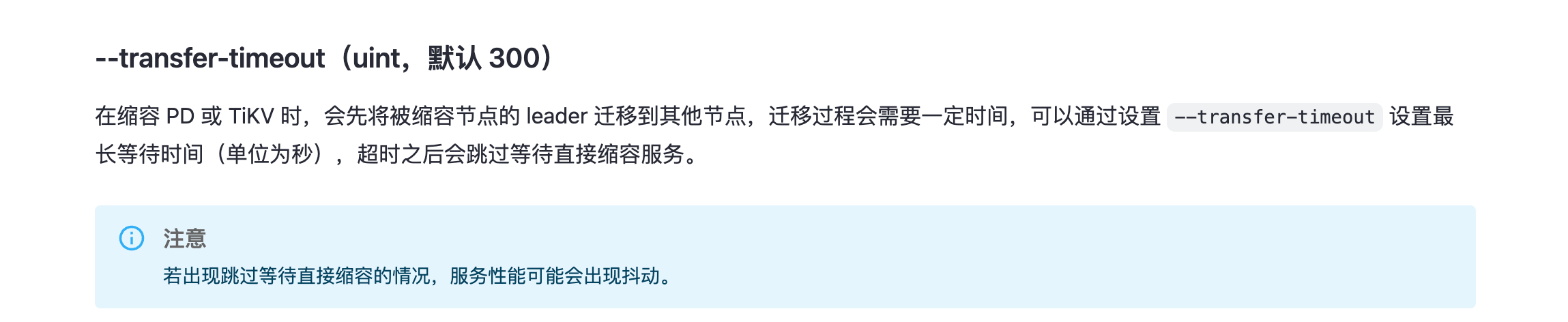
我知道问题出在哪儿了,没指定时间,默认5分钟后,强制下线了。
大佬,我还有一个问题,tiup 节点下线,超时300秒,就强制下线。 按理说 leader没迁完,剩余的部分在这个tikv上的 访问不了,应该会角色切换,把其他tikv上的 follower 提升为leader。 这个动作应该会很快。 感觉抖应该也是比较短暂的。 我这个集群抖了2天。 直到节点完全下线了。
那就是说两种情况导致的:
1) region的 leader 挂了, follower 切换成 leader 的动作。
2) region 副本缺失,在存活的tikv上 自动补齐副本。
xfworld
(魔幻之翼)
5
要下线的节点,优先进行 leader 驱逐操作,然后在下线…
>> scheduler add evict-leader-scheduler 1
// 把 store 1 上的所有 Region 的 leader 从 store 1 调度出去
参考这个命令
https://docs.pingcap.com/zh/tidb/stable/pd-control#scheduler-show--add--remove--pause--resume--config--describe
当 leader 被驱逐后,tikv 节点下线之后,副本会由其他的节点进行补全(前提是 tikv 节点仍然充足…)
1 个赞
system
(system)
关闭
6
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。