末0_0想
2023 年5 月 18 日 02:17
1
【 TiDB 使用环境】 测试
[2023/05/18 10:13:35.310 +08:00] [WARN] [errors.rs:155] ["backup stream meet error"] [verbose_err="Etcd(GRpcStatus(Status { code: Unknown, message: \"Service was not ready: buffered service failed: load balancer discovery error: transport error: transport error\", source: None }))"] [err="Etcd meet error grpc request error: status: Unknown, message: \"Service was not ready: buffered service failed: load balancer discovery error: transport error: transport error\", details: [], metadata: MetadataMap { headers: {} }"] [context="failed to get backup stream task"]
db_user
2023 年5 月 18 日 02:32
2
你这pd挂了一个,先把pd都起来,然后再起tidb,如果还没成功把启动时间的日志报错发下
末0_0想
2023 年5 月 18 日 02:39
3
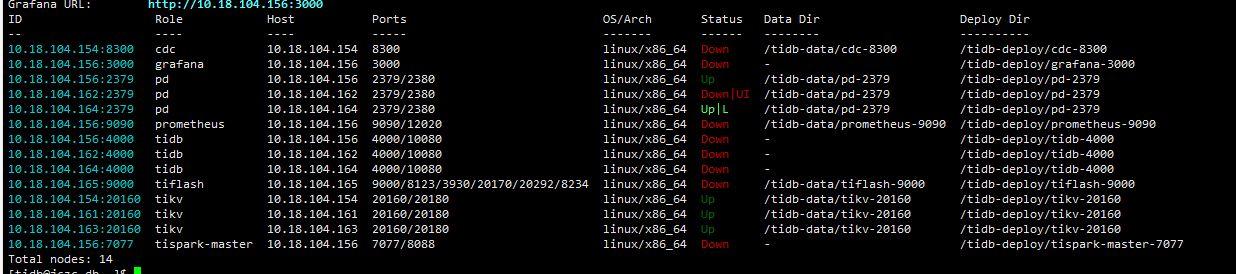
我按照您的方法吧集群全部停了,然后使用 tiup cluster start zdww-tidb -R pd 启动了pd,但是如下图之启动了2各节点。
还有一个162的节点日志上报
"] [request-path=/0/members/465979c2bcb316b9/attributes] [publish-timeout=11s] [error="etcdserver: request timed out"]
[2023/05/18 10:28:38.053 +08:00] [WARN] [server.go:2098] ["failed to publish local member to cluster through raft"] [local-member-id=465979c2bcb316b9] [local-member-attributes="{Name:pd-10.18.104.162-2379 ClientURLs:[http://10.18.104.162:2379]}"] [request-path=/0/members/465979c2bcb316b9/attributes] [publish-timeout=11s] [error="etcdserver: request timed out"]
[2023/05/18 10:28:49.054 +08:00] [WARN] [server.go:2098] ["failed to publish local member to cluster through raft"] [local-member-id=465979c2bcb316b9] [local-member-attributes="{Name:pd-10.18.104.162-2379 ClientURLs:[http://10.18.104.162:2379]}"] [request-path=/0/members/465979c2bcb316b9/attributes] [publish-timeout=11s] [error="etcdserver: request timed out"]
我接下载该怎么处理?
db_user
2023 年5 月 18 日 02:49
4
额,为什么要把集群都停了,你直接启动down的那个pd节点就行啊,现在是pd没起来,看下pd的日志有什么报错导致那两个节点没起来,看看网络是否正常,能不能通,启动是先启动pd,你的pd状态不正常,其他的组建都没办法正常启动
末0_0想
2023 年5 月 18 日 03:06
5
pd 我启动起来了 ,因为机器重启防火墙起来了。
我是用tiup cluster start zdww-tidb -R tidb 启动tidb的时候报了以下错误
Error: failed to start tidb: failed to start: 10.18.104.164 tidb-4000.service, please check the instance's log(/tidb-deploy/tidb-4000/log) for more detail.: timed out waiting for port 4000 to be started after 2m0s
我又看了下 164的日志 发下以下错误,但是我看了防火墙是关闭的。是要先启动tikv吗?
[2023/05/18 10:56:24.527 +08:00] [INFO] [region_cache.go:2539] ["[health check] check health error"] [store=10.18.104.163:20160] [error="rpc error: code = Unavailable desc = connection error: desc = \"transport: Error while dialing dial tcp 10.18.104.163:20160: connect: connection refused\""]
[2023/05/18 10:56:25.271 +08:00] [INFO] [region_cache.go:2539] ["[health check] check health error"] [store=10.18.104.161:20160] [error="rpc error: code = Unavailable desc = connection error: desc = \"transport: Error while dialing dial tcp 10.18.104.161:20160: connect: connection refused\""]
[2023/05/18 10:56:25.338 +08:00] [INFO] [region_cache.go:2539] ["[health check] check health error"] [store=10.18.104.154:20160] [error="rpc error: code = Unavailable desc = connection error: desc = \"transport: Error while dialing dial tcp 10.18.104.154:20160: connect: connection refused\""]
[2023/05/18 10:56:25.527 +08:00] [INFO] [region_cache.go:2539] ["[health check] check health error"] [store=10.18.104.163:20160] [error="rpc error: code = Unavailable desc = connection error: desc = \"transport: Error while dialing dial tcp 10.18.104.163:20160: connect: connection refused\""]
[2023/05/18 10:56:26.271 +08:00] [INFO] [region_cache.go:2539] ["[health check] check health error"] [store=10.18.104.161:20160] [error="rpc error: code = Unavailable desc = connection error: desc = \"transport: Error while dialing dial tcp 10.18.104.161:20160: connect: connection refused\""]
[2023/05/18 10:56:26.339 +08:00] [INFO] [region_cache.go:2539] ["[health check] check health error"] [store=10.18.104.154:20160] [error="rpc error: code = Unavailable desc = connection error: desc = \"transport: Error while dialing dial tcp 10.18.104.154:20160: connect: connection refused\""]
[2023/05/18 10:56:26.528 +08:00] [INFO] [region_cache.go:2539] ["[health check] check health error"] [store=10.18.104.163:20160] [error="rpc error: code = Unavailable desc = connection error: desc = \"transport: Error while dialing dial tcp 10.18.104.163:20160: connect: connection refused\""]
db_user
2023 年5 月 18 日 03:10
6
你这直接重启整个集群就行了,4000端口也先看下是不是防火墙的问题,启动顺序是先pd,再kv,再PD,启动之前先检查一下防火墙和网络情况,反正集群此时已经不能对外服务了,直接重启集群就行了
末0_0想
2023 年5 月 18 日 03:16
7
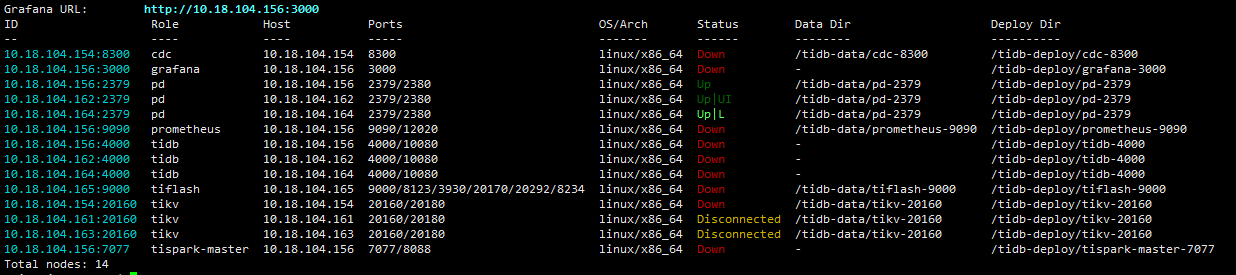
我单独使用
后面我使用tiup cluster restart zdww-tidb直接全部重启了下
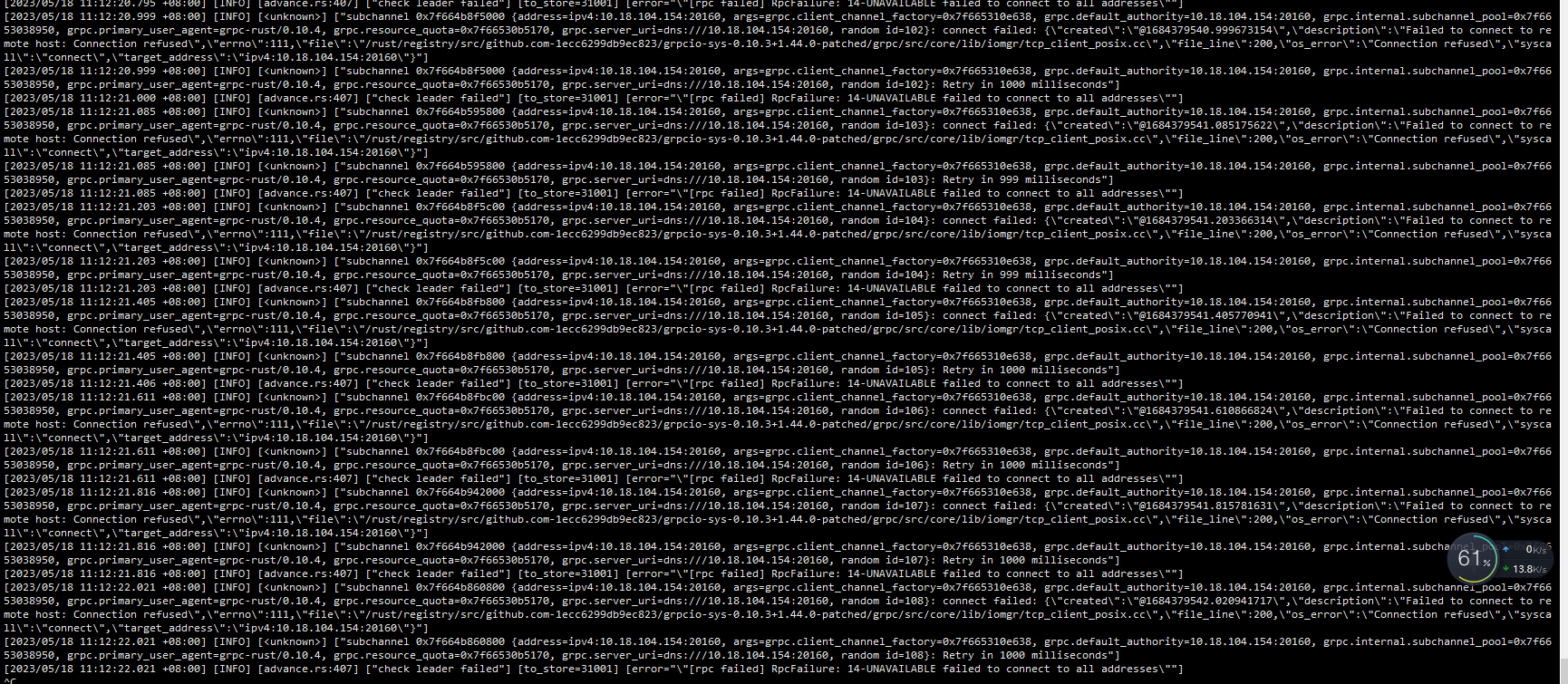
161的日志中报错,能帮忙看看吗。
db_user
2023 年5 月 18 日 03:22
8
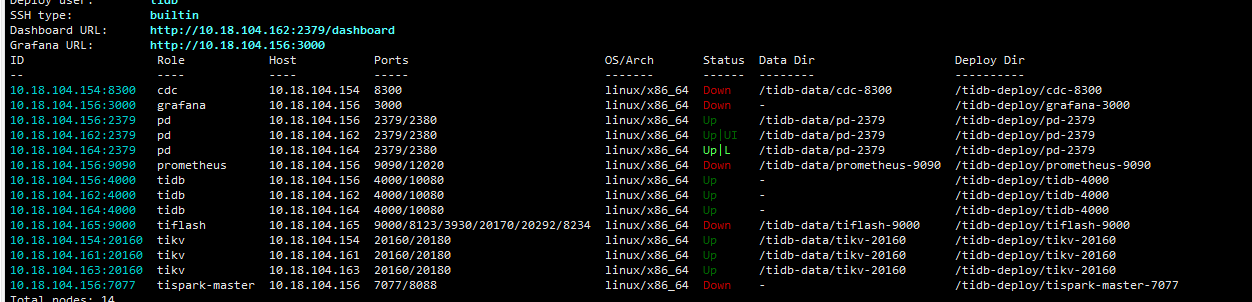
你第一张图kv和pd不都正常起来了么,直接用-N单独起节点就行了,下面的日志报错访问不到154的20160端口,你看下是不是防火墙又起来了,还是什么情况,先保证防火墙关闭,网络都通才行
末0_0想
2023 年5 月 18 日 03:32
9
我发现我是用 tiup cluster start zdww-tidb -R tikv 是能拉起tikv的
但是使用 tiup cluster restart zdww-tidb 就会在161节点报以下错误。说是文件损坏,导致tikv 节点无法拉起来。
The last log file is corrupted but ignored: Append:58, Corruption: Log item offset is smaller than log batch header length
之前我是用过 dumpling 进行备份但是把服务器拉宕机了。
db_user
2023 年5 月 18 日 03:44
10
这个不是主要影响,你看下资源,都启动的时候可能资源不足了
末0_0想
2023 年5 月 18 日 04:12
11
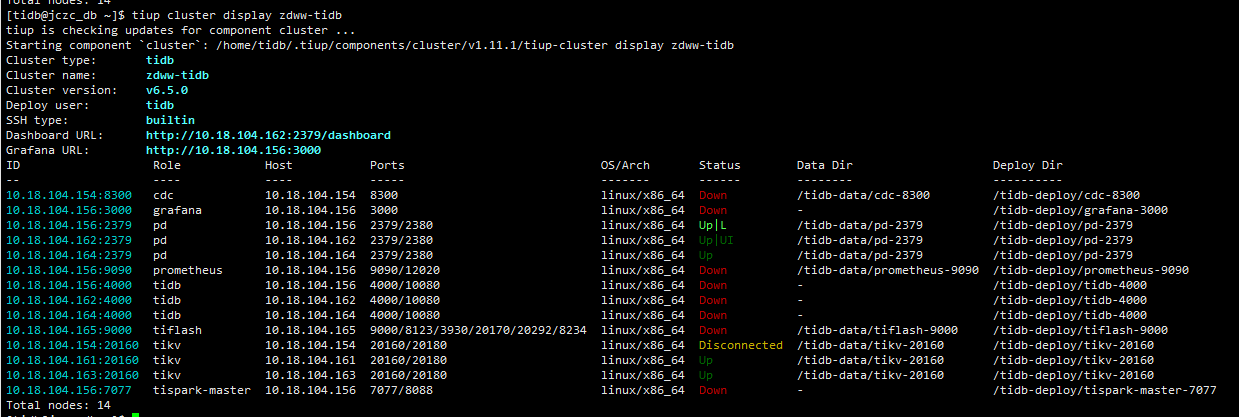
能在辛苦看一下吗 使用 tiup cluster restart zdww-tidb 启动就是卡在tivk启动这里 总是显示超时。资源我也看了没有太高的。防火墙 什么的也都是关了的
154
154.txt (247.7 KB)
161
ttt (3).txt (611.8 KB)
进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
末0_0想
2023 年5 月 18 日 06:51
13
还有我想问下 我在查询大数据量表的时候经常报 “> Lost connection to MySQL server during query”查询下来发现IO太高造成tidb 重启了,这种情况怎么处理。
日志中还有如下报错
有没有办法限制查询时io 或进程数量 从而保证服务是正常的。查询可以慢的至少不会断掉服务。
Min_Chen
2023 年5 月 24 日 02:14
14
您好
看起来您的服务器硬件不是很大,CPU 内存。在使用时,可以降低工具的并发度,应用方面来降低并发度和单个 SQL 所需资源,不然会经常跑挂集群的。可以考虑扩容硬件了。
1 个赞
system
2023 年7 月 23 日 02:15
15
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。