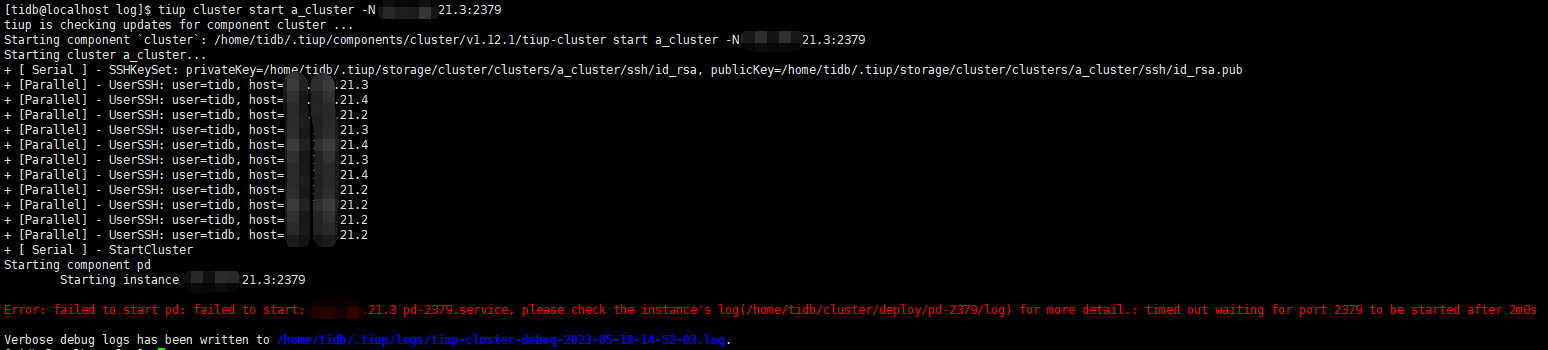
tpcc日志:
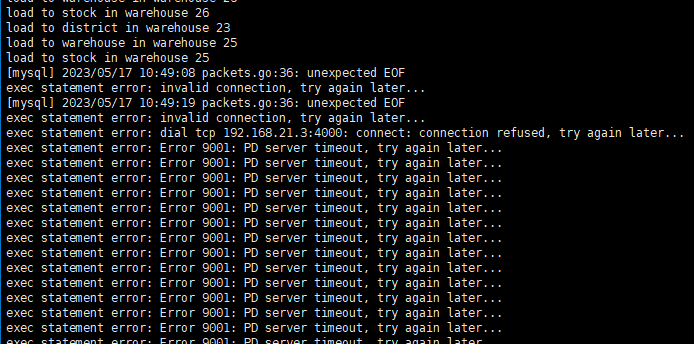
集群状态:

接着除了一个tidb在线,tikv节点状态全为N/A,其它节点全DOWN:

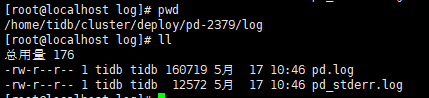
最先DOWN掉的pd节点日志:
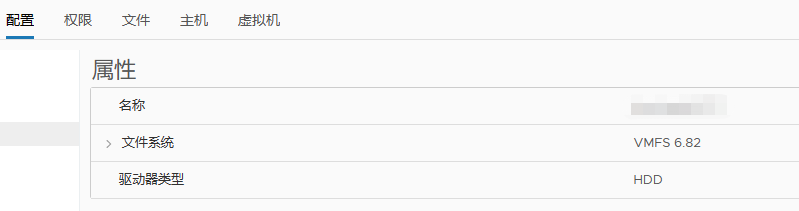
apply request took too long,硬盘是SSD的吗,看看监控资源使用情况怎么样
节点down掉后用tiup cluster start a_cluster -N启动指定节点就拉不起来了,对应的节点日志也没更新,监控也就看不了了。
这里还有几个问题——
1.日志里的apply request具体是在做什么呢?
2.如果时间过久会导致pd下线的话,这个时间有一个临界点吗?
3.一个pd down掉以后是会导致其它节点都异常么?
4.为什么节点down掉以后就没办法再拉起来了呢?
以下是相应的截图——
18号拉起指定节点
您好
tidb 集群需要固态硬盘作为数据读写磁盘。高压的读写对于 HDD 会造成集群崩溃。