【 TiDB 使用环境】生产环境
【 TiDB 版本】6.1.1
【复现路径】
【遇到的问题:问题现象及影响】
上流tidb 对很多表做了update 操作,后cdc占cpu 内存网络飙升,延迟也很大,看日志有如下报错
error="[CDC:ErrEventFeedEventError]eventfeed returns event error: not_leader:<region_id:844026 leader:<id:5329197 store_id:17561 > > "] [sri={}]
后把cdc停了
【资源配置】
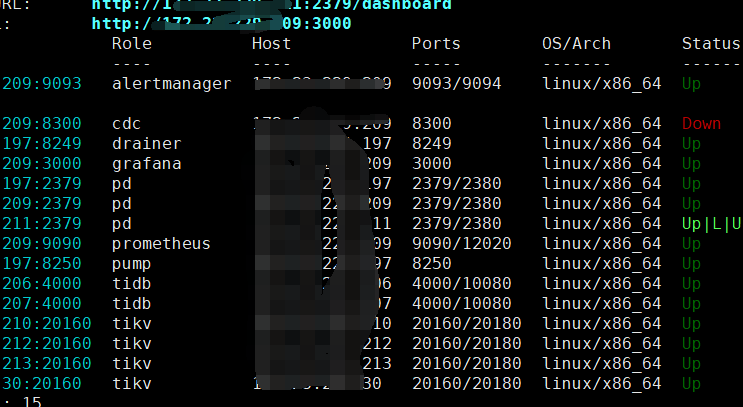
【附件:截图/日志/监控】
xfworld
(魔幻之翼)
2
not_leader:<region_id:844026 leader:<id:5329197 store_id:17561 > >
tidb 的环境是正常的么?通过 grafana 看下 region 的情况…
tidb 是正常的, 执行update操作后,region 增加了很多,
xfworld
(魔幻之翼)
4
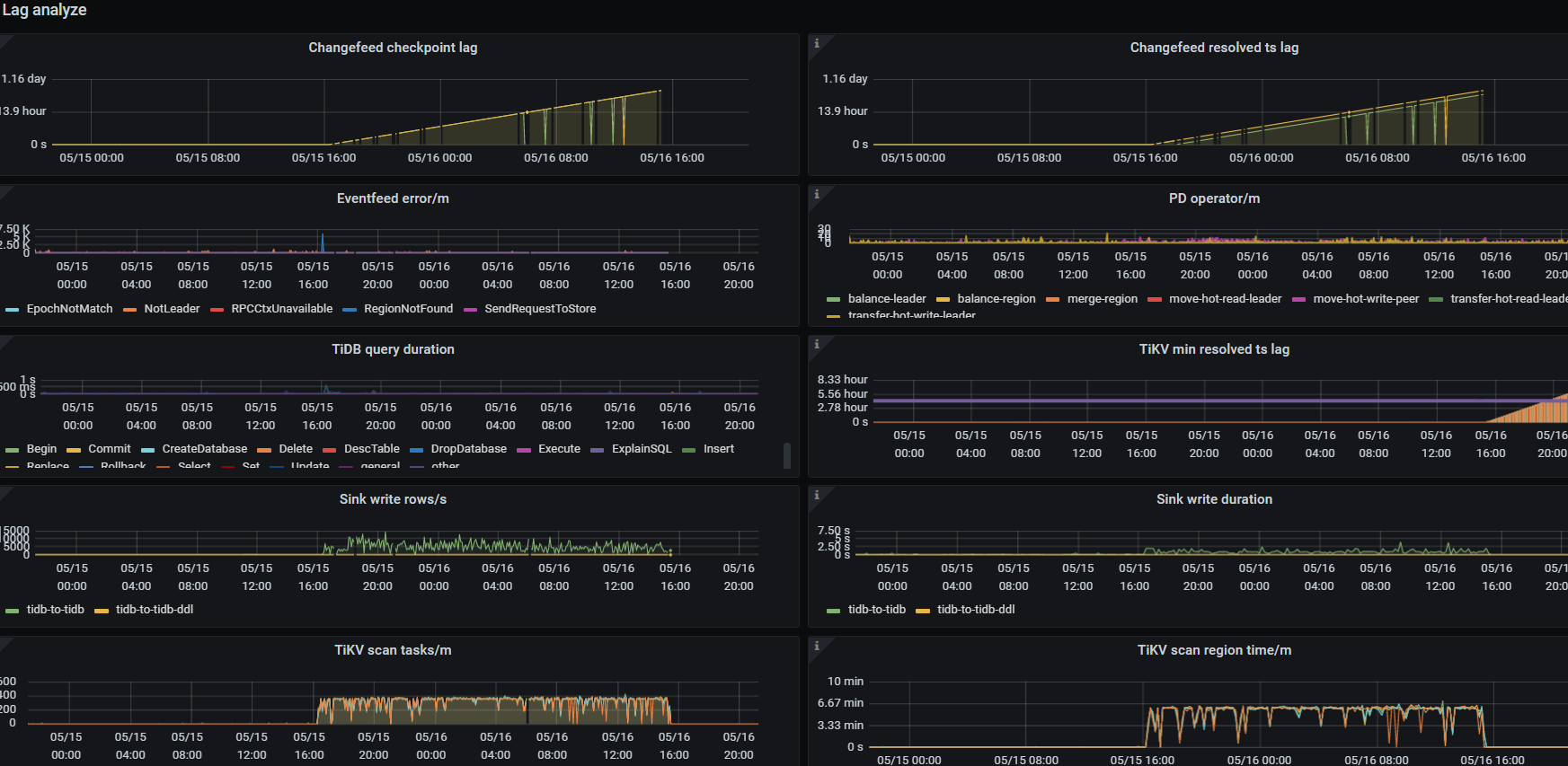
上游tidb 5月15号16点左右update 操作后 ,leader 和region 都增加了很多,
xfworld
(魔幻之翼)
10
你要选下时间,因为CDC 停了,你要选到出毛病之前的那段时间会比较好
xfworld
(魔幻之翼)
11
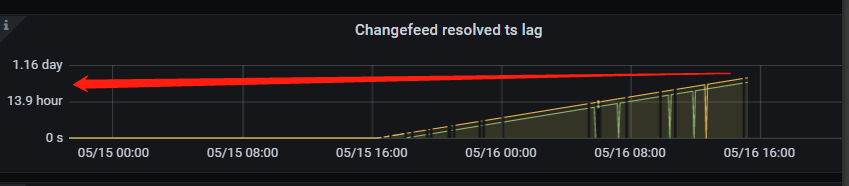
超过 14 小时了,明显下游有问题啊,接不住啊…
从这个时间轴上很容易观测出问题了,5月15日 16:00 干了什么坏事了?
打这个时间之后,就开始后延了… 
就是5月15日 16:00 update 了很多表,然后qps上升很多,cdc就开始占cpu,内存,网络飙升。下游看状态正常,
xfworld
(魔幻之翼)
13
那多半是大事务吧?
cdc 对于大事务的处理,是有拆分标识的,不过 6.2.x 才支持
从 v6.2 版本起,你可以通过配置 sink uri 参数 transaction-atomicity 来控制 TiCDC 是否拆分单表事务。拆分事务可以大幅降低 MySQL sink 同步大事务的延时和内存消耗。
刚查了下,6.1.1 也支持这个特性
update 了很多表,而且都是where id = 111 ,类似这种的算是大事务吗?
xfworld
(魔幻之翼)
16
大部分都是已知,已修复的bug了,有条件的话,可以考虑升级小版本
5.15 16:00 上游有大量的 region leader 迁移,会导致 ticdc 和 上游 tikv 出现的链接要重新建立连接,做增量扫,导致延迟增加。不过建议先升级cdc 到 6.1.6 ,再看是否还出现该问题。
你好,麻烦问下,我现在集群v6.1.1的,可扩容一个6.1.6的ticdc吗?
system
(system)
关闭
19
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。