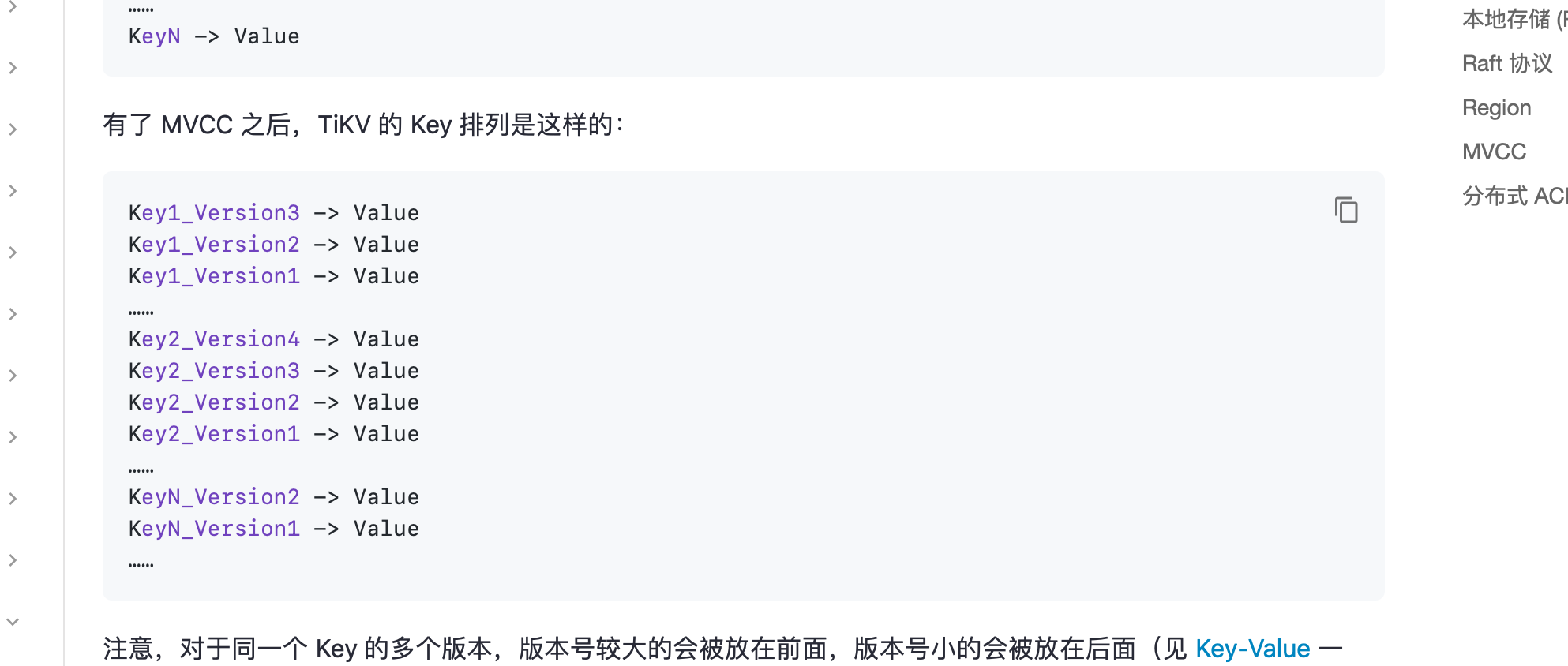
我们知道RocksDB 的mvcc 存储数据时,对于1个key,会保存多个不同版本的数据,那么如果遇到mvcc 版本数据特别多的情况下,会导致这种二级索引的范围查询性能下降,因为需要扫描很多过期的数据,对于这个问题的答案不知道是否是以下答案
1.对于二级索引范围查询,rocksdb需要用seek方法定位到第1个key,虽然可以版本号新的排在前面可以快速找到,但是接下来如果要扫描剩下的key,那就需要不停调用next方法先遍历这个key所有的历史版本才能到下一个key,这样就导致大量的过期版本数据扫描,之所以不继续调用seek方法去扫描下1个key,是因为seek的扫描成本过高,毕竟seek的查找顺序为内存memtable找,然后到磁盘的sst文件找,如果每1个key 都用seek 这种方法查找的话,性能极剧下降,相比之下调用next这种方法性能反而高点
xfworld
2023 年5 月 16 日 09:23
2
版本多了,要从版本中获取需要的数据,肯定只能seek了
这个和 RocksDB 的特性又有很大的关系,level 的层次会影响到数据获取的速度了
不建议存放太多的历史版本,建议及时的 发起 Compatcion ,对历史版本进行清理
人如其名
2023 年5 月 16 日 21:56
3
个人理解+猜测:要检索的数据是等值情况 ,且值为’20220517’,存在较多重复记录。在tikv检索时候只能通过prefix_seek(索引前缀_索引字段),定位到第一个位置,(虽然索引的key是索引前缀_索引字段_行ID,但是你无法拼出这个key,因为你并不知道行ID)然后将数据通过next返回给tikv进行mvcc判断,直到prefix_seek出来的结果不合法(isvalid=false)。假设你检索的数据是in(‘20220517’,‘20220518’)多个值的情况 ,那么当‘20220517’通过next迭代完毕后,尝试继续next操作(具体会窥探几次,需要测试看下,好像是10次)看是否可以遍历出’20220518’的key记录,如果可以说明这两个key的距离很近,避免了seek。假设你检索的数据是范围情况 ,等同于等值情况。
当通过二级索引得到行ID后是可以通过{行ID_version(tidb传过来的ts)}拼成Key_Version,然后可以直接通过 RocksDB 的 SeekPrefix(Key_Version) API,定位到第一个大于等于这个 Key_Version 的位置。
因此对于二级索引上存在多个历史版本的情况,属实很无奈,只能next把所有数据拿给tikv做判断,对于多个索引值情况,如果多个索引值的key距离比较远,还需要增加seek次数。
所以,有一个典型的场景:delete from t where index_date < ‘xx’ limit 10000;这种边产生历史版本,边检索二级索引的场景就比较容易放大这个问题。越到最后索引的历史版本就越多,每次都需要从符合条件的第一个索引key开始扫,然后next遍历完所有符合条件记录,导致越来越慢,CPU越用越多。优化之 :如果在刚开始删除数据之前就通过二级索引设置范围通过between and + limit来框定上下界进行批量删除,那么就可以缩小很多无效扫描,每次只在局部(between and之间)扫描一些过期数据,扫描量大大减少。。更优之 :如果在删除数据之前就把符合条件的记录的行ID都查出来,然后排序(排序的目的是让行ID更加的连续,利用next快速检索数据),对排序后的行ID,一批一批的关联需要删除表的记录行,不会扫描过期数据。产品之 :刚才这个思路如果删除数据量太多,那么就需要把行ID都存起来然后一批一批关联,存行ID、批次号等操作可能较为耗时,因此通过行ID+批次+where条件范围划分多个上下界,那么数据量就会对大大减少,可以放到内存中分批删除,目前官方提供的batch DML就是这种思路,如果后续实现并行能力,那么就更强了。
假如rocksdb能提供next_key(offset,limit)接口(指的是预先向rocksdb申请接下来从第offset次开始连续limit个key的返回),那么可能处理这种过期数据效率就会提升较大,比如next_key(5,1),next_key(10,1),next_key(max_offset=1024,1)等来尝试跳过部分过期数据,减少了rocksdb到tikv的数据传输,也可以一次性返回给tikv多个key,减少了交互次数。
同样幻想下对于全表扫描再提供个next(offset,limit)接口,也会有较好的效果
system
2023 年7 月 15 日 21:57
4
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。