【 TiDB 使用环境】生产环境
【 TiDB 版本】v5.4.0
【复现路径】几次在9点左右的时候出现延迟高的问题,导致业务卡顿
【遇到的问题:问题现象及影响】
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】

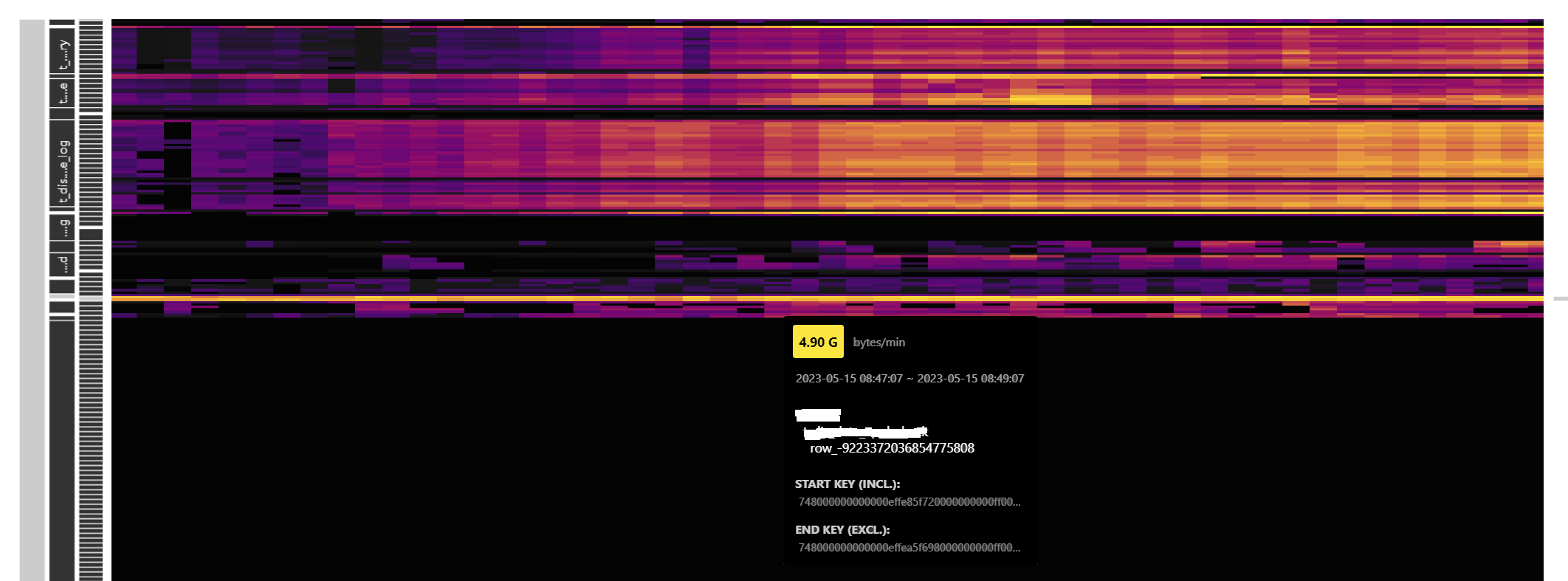
看看这几个点的慢查询以及资源消耗
能复现的问题,可以先抓下show processlist, 多数能发现问题
看起来有不少的全表扫导致热点。可以尝试优化慢sql,建立索引来解决
我看是tikv的io延迟导致sql查询慢的,当时好像都是在一个tikv上面执行,能否有办法执行的时候能分开到三个节点执行?
从你的热力图可以看到,存在热点,你要想办法把查询的表热点打散
下载一个diag ,tiup install diag,然后收集下文件时间段前后的信息上传clinic server. https://docs.pingcap.com/zh/tidb/stable/quick-start-with-clinic
找找对应时间的慢 SQL 具体慢在哪里
把热点打散有什么方法吗?
热点排查:
如何确认是热点问题
热点问题产生原因
热点问题解决
1.形成热点的原因原理
-
写:存储数据组织是按照key有序排列,而同一个表的数据的key前缀是相同的,导致在相同tikv实例上连续写入
-
读:高频访问的小表、大量扫描数据、对具有顺序增长的索引扫描
2.如何定位热点问题
-
通过Dashboard的流量可视化热力图确认时间和库表的region,然后在慢查询SQL和SQL语句分析页面确认可能的SQL
-
通过grafana 的TiKV trouble shooting页面、tikv-Details的hot write/read、PD监控确认
3.热点问题解决
1)业务未上线在建表时提前打散热点:
-
建表时非聚簇索引表或是聚簇索引表且非int主键,可以使用shard_row_id_bits和pre_split_regions提前分配好region避免热点
-
建表时如果是聚簇索引表且有自增int主键列,使用auto_random修饰主键列指定随机生成tidb_rowid打散热点,而不用auto_increment。Tidb中的唯一键自增主键只有唯一且非空特性,不能保证递增特性。
-
如果是在批量建表后会批量插入数据,打开tidb_scatter_region开关,系统会自动在建表后打散region
2)业务运行过程中发现热点:
-
通过dashboard确认如果是索引热点,则手动切分region并交给系统打散:split table {table_name} index {idx_name} between {from} and {to} regions {n} ,如果还有热点则需要手动打散热点,操作步骤请看下文。
-
如果写入的表有int自增长主键,则可以设置auto_random(alter table {table} modify a bigint auto_random(5))
-
引起热点的SQL如果是insert操作,表如果没有主键则可以设置shard_row_id_bits打散内部分配的tidb_rowid
-
引起热点的SQL如果是update/delete操作,要手动打散region。手动打散region的操作:
-
通过dashboard确认start_key,再找出region id和store id:pd-ctl region key {start_key}
-
分裂region:pd-ctl operator add split-region {region_id} --policy=aproximate
-
手动打散:
-
查找pd.log找出split后的新的region id,然后根据此新region id手动transfer到空闲的节点上,要先去看看哪个store比较空闲并找到其store id
-
operator add add-peer {new-region-id} {target-store-id}
-
operator add transfer-leader {new-region-id} {target-store-id}
-
operator add remove-peer {new-region-id} {origin-store-id}
-
如果是读热点,小表频繁访问引起的热点
-
如果小于64MB且更新不频繁,则设置为缓存表,直接缓存到tidb-server的内存
-
通过set config tikv split.qps-threadshold=3000超过3k的QPS,或set config tikv split.byte-threshold=30超过30MB的访问流量,触发系统的自动打散功能,使之均衡
-
如果是读热点,也不是小表,则可能是执行计划问题,确认是否缺失索引、是否优化器选择索引错误来处理
今天下午把sql都优化了一下,到了晚上发现在业务量低的时候,tikv的io还是保持在30%的,是不是tikv服务器的io需要提高啊。
谢谢。
分析一下这段时间的慢sql