【 TiDB 使用环境】生产环境 /测试/ Poc 生产
【 TiDB 版本】v4.0.13
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
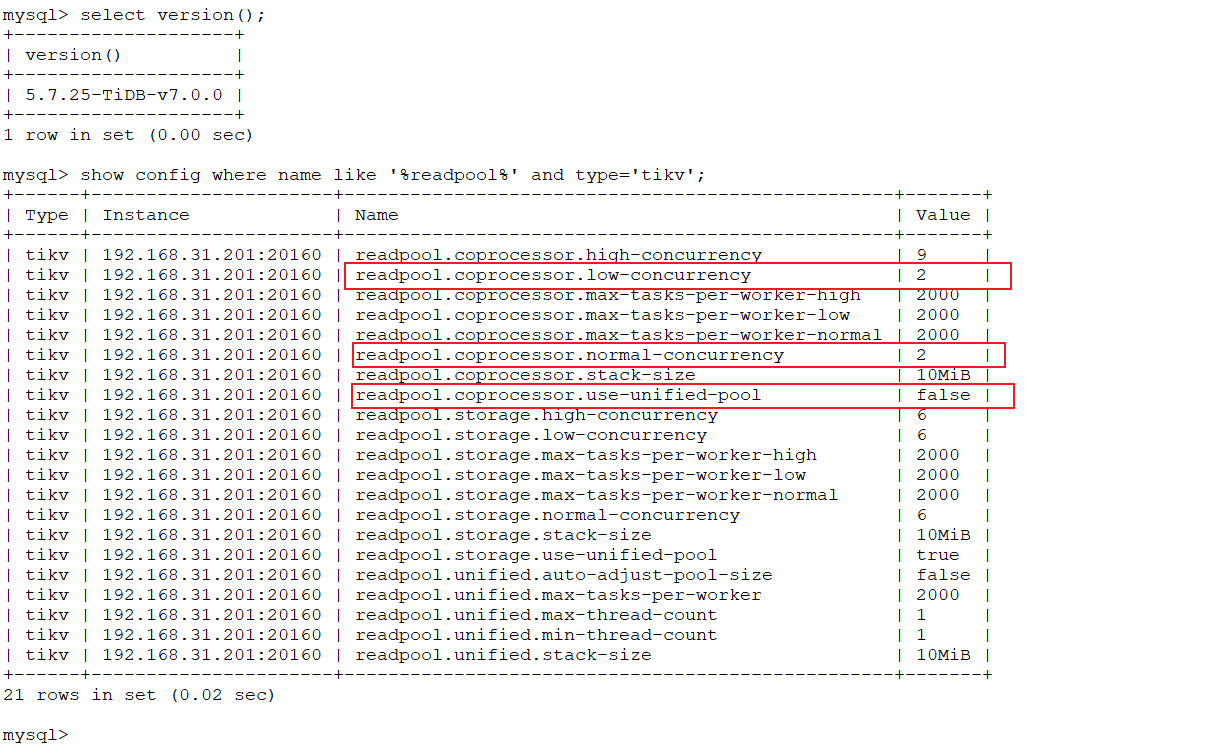
±-----±-------------------±-------------------------------------------------±------+
| tikv | readpool.coprocessor.high-concurrency | 25 |
| tikv | readpool.coprocessor.low-concurrency | 25 |
| tikv | readpool.coprocessor.max-tasks-per-worker-high | 2000 |
| tikv | readpool.coprocessor.max-tasks-per-worker-low | 2000 |
| tikv | readpool.coprocessor.max-tasks-per-worker-normal | 2000 |
| tikv| readpool.coprocessor.normal-concurrency | 25 |
| tikv | readpool.coprocessor.stack-size | 10MiB |
| tikv | readpool.coprocessor.use-unified-pool | true |
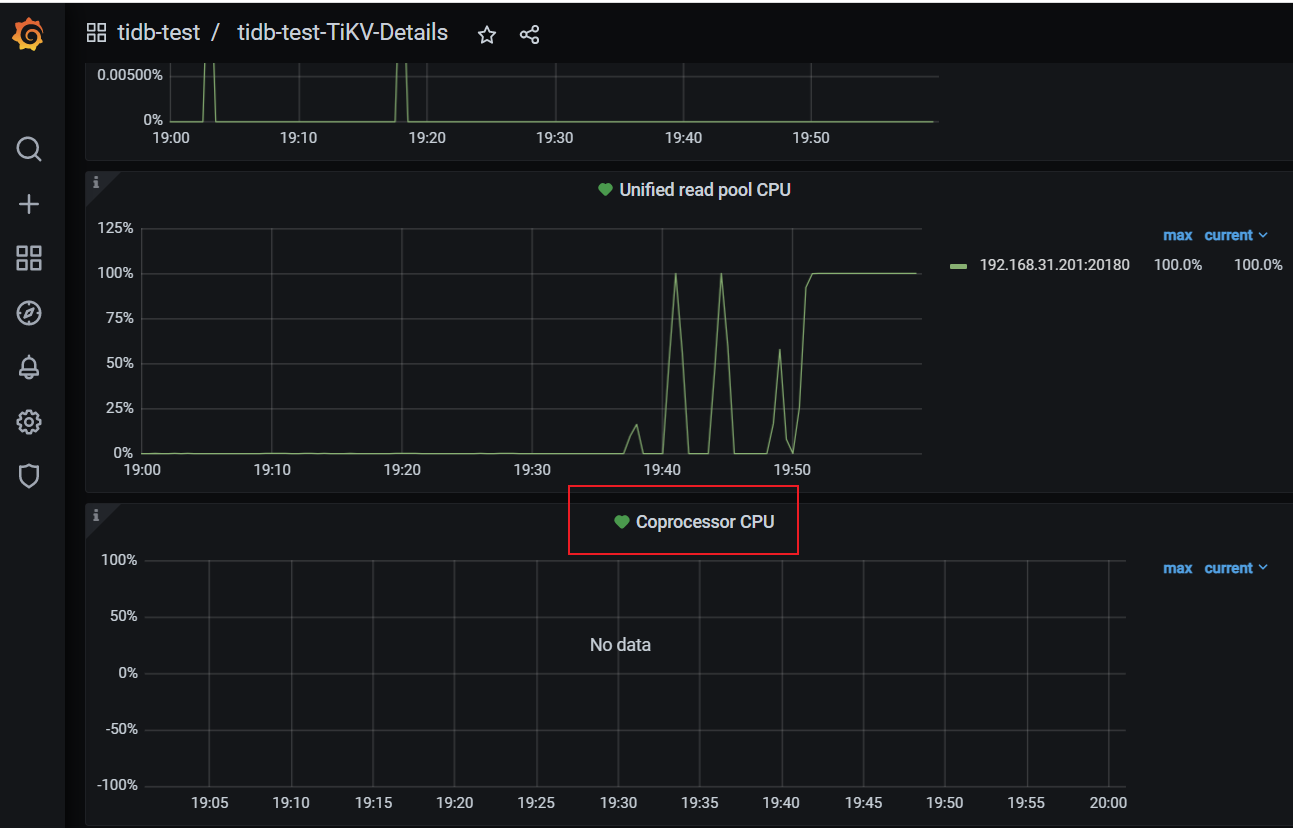
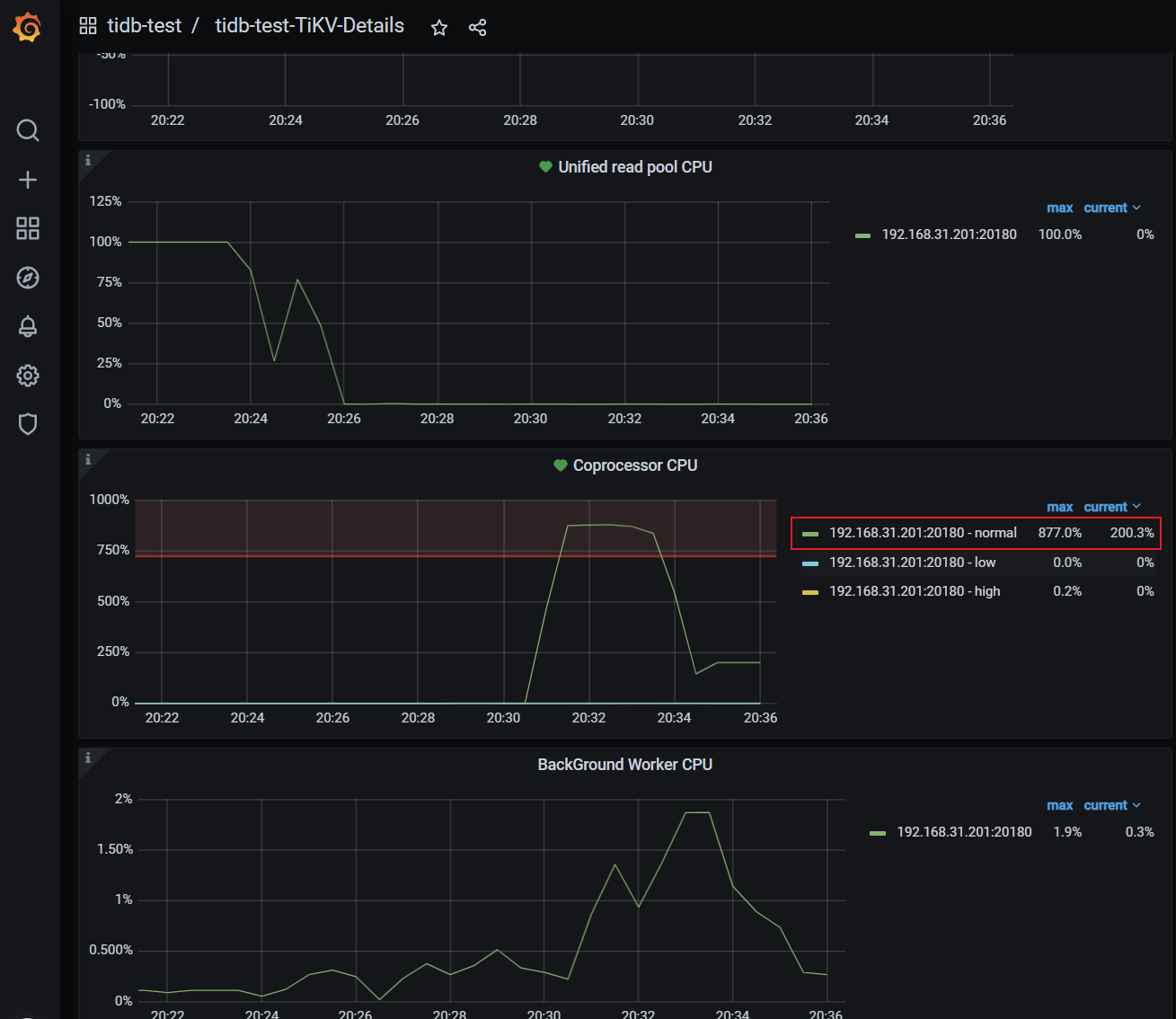
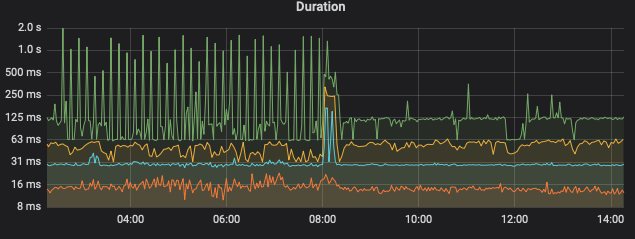
目前情况是一个定时任务会扫描索引30万个key,并发几十个,会造成另一个查询的rpc时间变长
想问下
1.readpool.coprocessor.low-concurrency的意义是否代表是对于非点查的情况只能同时有25个cop
2.如何查看当前非点查的cop线程数量情况
3.遇到cop速度慢的时候是调优readpool.coprocessor.low-concurrency更有用些还是调优tidb_index_lookup_concurrency
tidb_index_lookup_join_concurrency
tidb_index_lookup_size
tidb_index_serial_scan_concurrency
等参数更有用些
期待大佬们解答