【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
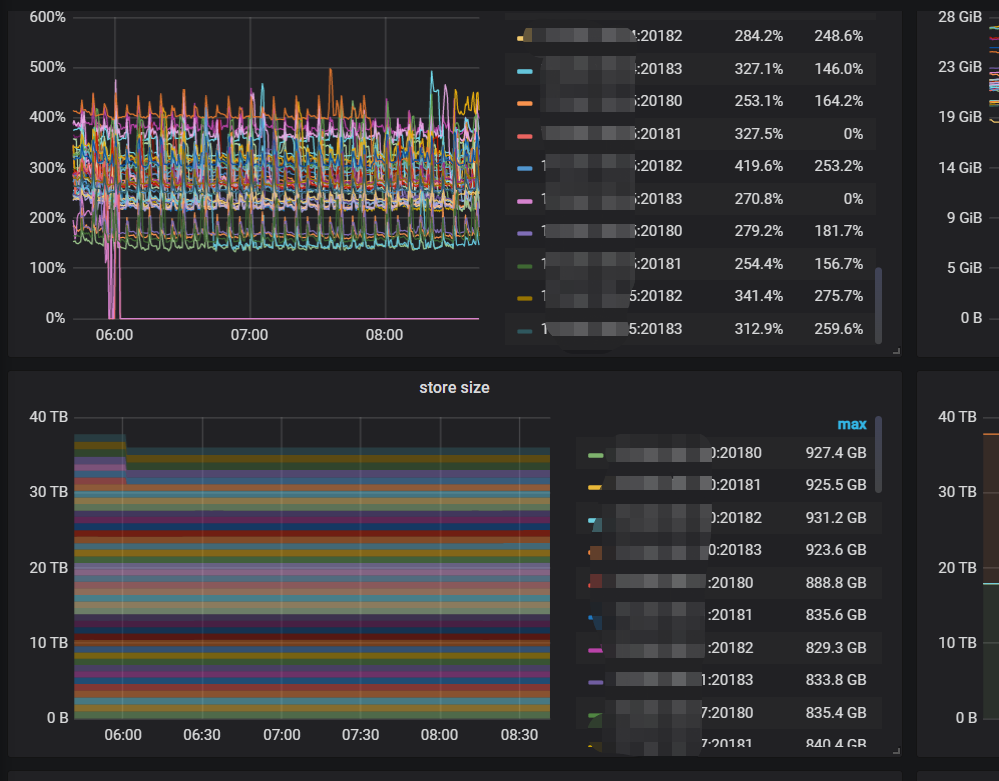
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
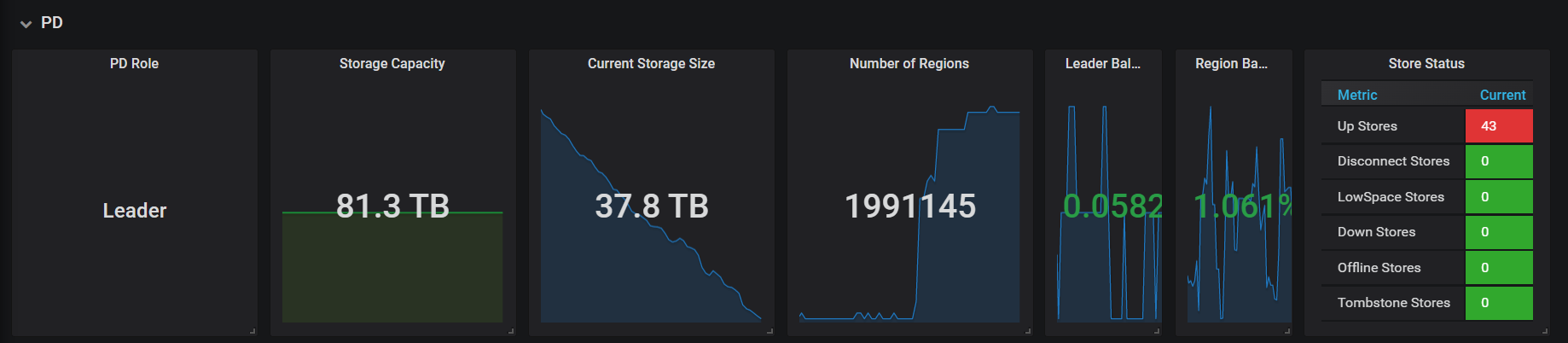
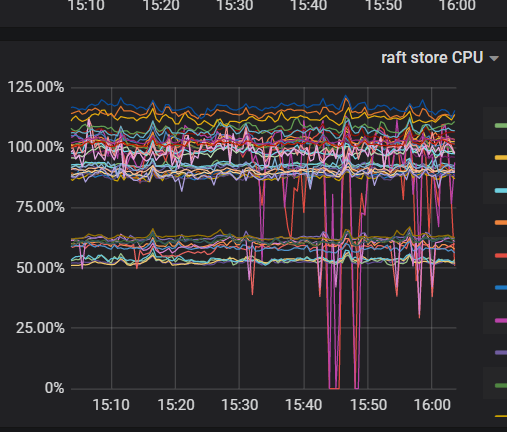
这是最近出现的情况
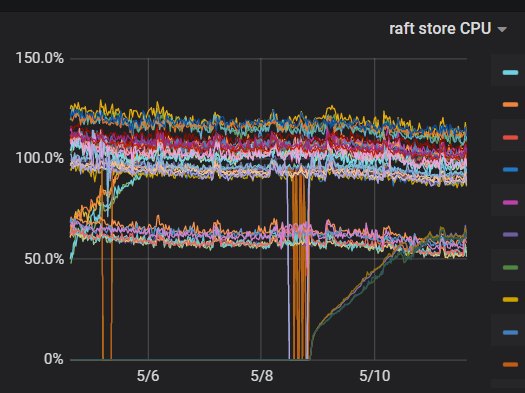
【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
这是最近出现的情况
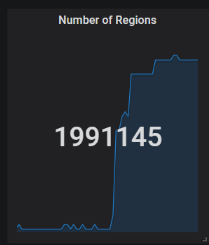
这是做了什么操作了?
没做任何操作啊,只是在频繁出现这个问题以后加入一台服务器,目前看已经完成数据平衡了
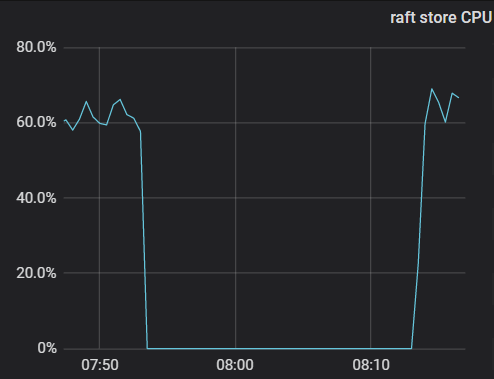
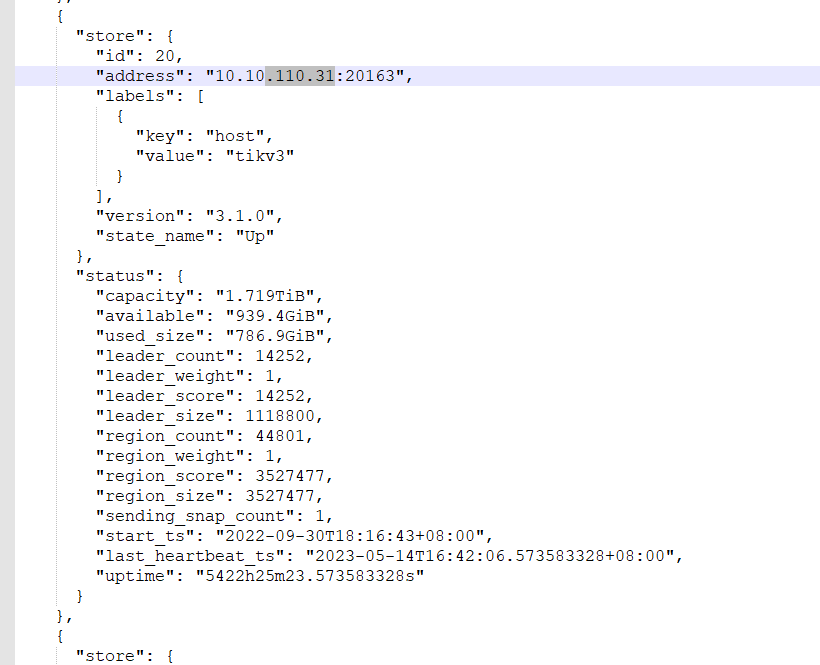
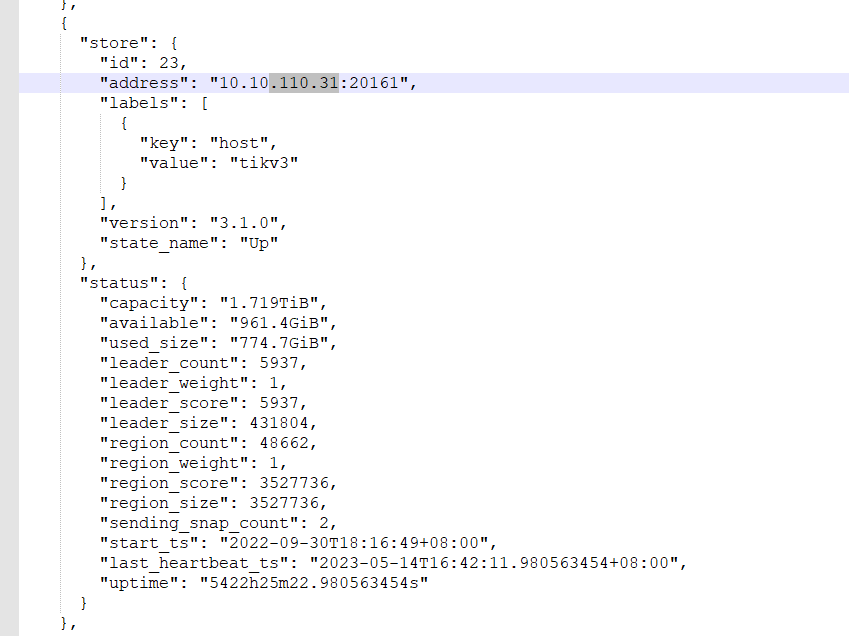
总共多少store,up store那显示红色
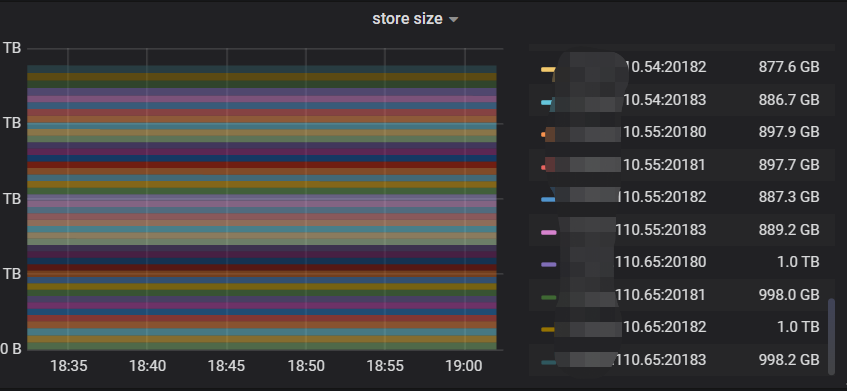
看一下kv的存储呢,有没有kv的磁盘使用达到70%或以上的
最高63%
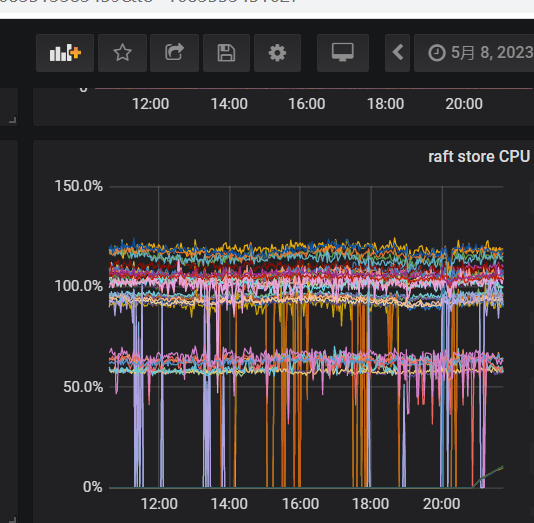
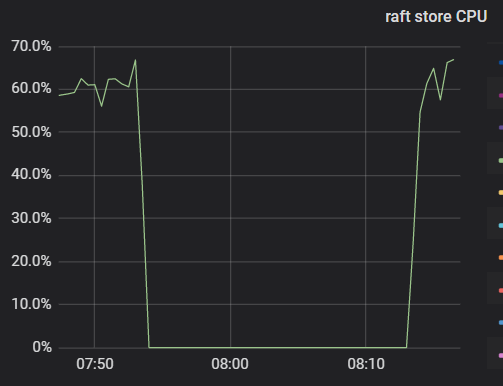
今天又出现了
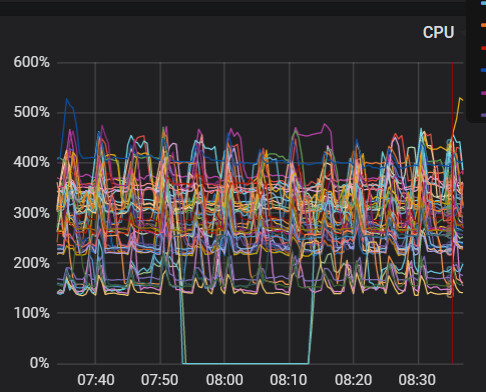
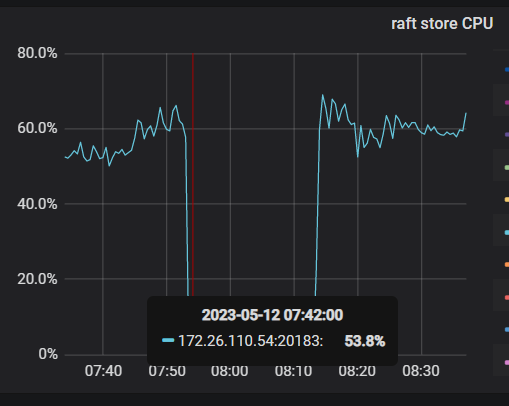
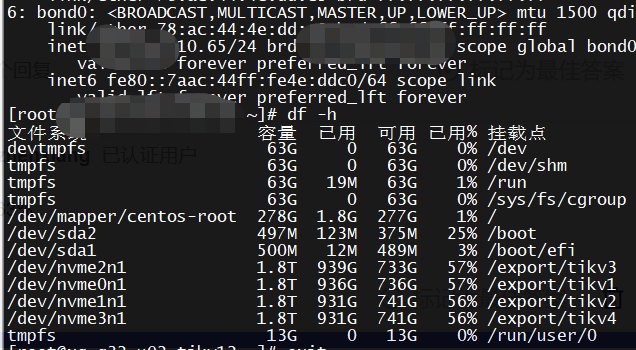
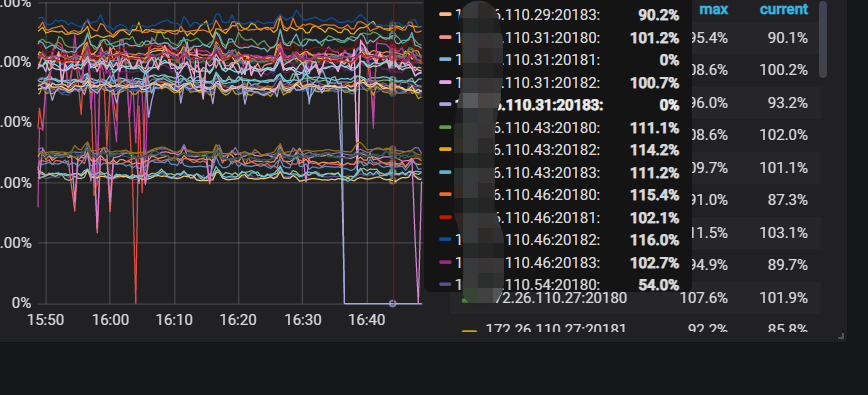
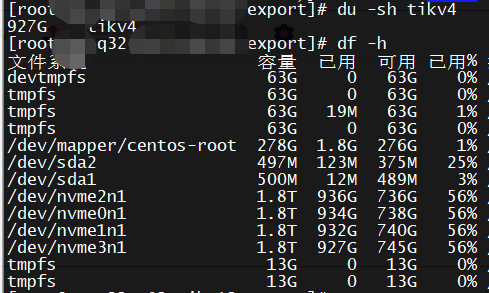
你看下df和du的结果一样么,按理说磁盘监控应该是一样的啊
df和du 的结果是一样的
看看对应tikv在对应时间上的tikv.log里面有没有什么警告,错误什么的。也许能提供一些精确的信息。
这是另外一个节点的日志,同一个机器,同一个node的
tikv1.log (232.2 KB)
https://docs.pingcap.com/zh/tidb/v4.0/troubleshoot-lock-conflicts
会不会是乐观事务导致的读写冲突?
其中一台出现问题时间段附近是
[2023/05/12 07:56:41.859 +08:00] [WARN] [endpoint.rs:454] [error-response] [err=“locked primary_lock: 7480000000000007575F698000000000000001013336333333333965FF3063653134303634FF3961623338343161FF6336653433663135FF0000000000000000F7 lock_version: 441411017584410636 key: 7480000000000007575F698000000000000003013161633733336630FF6464306134643534FF6234373162383235FF6237333033396266FF0000000000000000F70380000000C400C53B lock_ttl: 3005 txn_size: 1”]
[2023/05/12 07:58:33.637 +08:00] [INFO] [gc_worker.rs:902] [“gc_worker: start auto gc”] [safe_point=441410059277697024]
[2023/05/12 07:58:43.482 +08:00] [INFO] [gc_worker.rs:942] [“gc_worker: finished auto gc”] [processed_regions=15436]
[2023/05/12 08:01:12.898 +08:00] [INFO] [peer.rs:176] [“replicate peer”] [peer_id=360797704] [region_id=259575968]
[2023/05/12 08:01:12.901 +08:00] [INFO] [raft.rs:763] [“[region 259575968] 360797704 became follower at term 0”]
出现locked 以后就有较长一段时间日志什么也没输出,另一台倒是没有类似的情况,但日志中类似的locked报错也不少见。
locked primary_lock:
这个错误影响CPU吗?我看连接里面只有观察,没有处理方式啊
观察 KV Errors 下 Lock Resolve OPS 面板中的 not_expired/resolve 监控项以及 KV Backoff OPS 面板中的 txnLockFast 监控项,如果有较为明显的上升趋势,那么可能是当前的环境中出现了大量的读写冲突。
文档中提到这个监控项,我觉的可以先看看这些对应的指标是否有异常,至少日志里面其他报错更看不出有啥问题。
对应处理方式也确实写的不太明确。
在 v3.0.8 之前,TiDB 默认使用的乐观事务模式会导致事务提交时因为冲突而失败。为了保证事务的成功率,需要修改应用程序,加上重试的逻辑。悲观事务模式可以避免这个问题,应用程序无需添加重试逻辑,就可以正常执行。
感觉更像是鼓励你在可能的情况下直接使用悲观事务模式。 ![]()