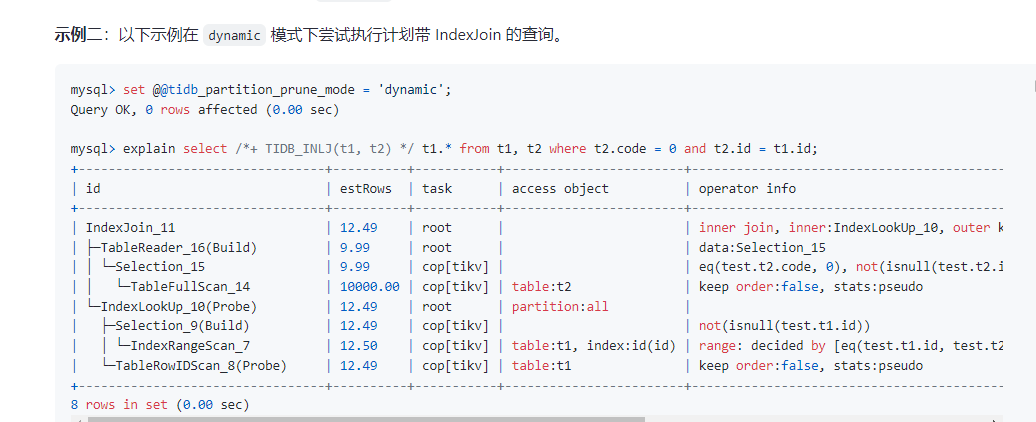
在开启分区表动态裁切的模式下,执行计划里面还是显示partition:all
复现步骤:
tidb版本:6.1.5
t1的表结构如下
CREATE TABLE t1 (
id int(11) DEFAULT NULL,
h_record int(11) DEFAULT NULL,
KEY id (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
PARTITION BY RANGE (id)
(PARTITION p0 VALUES LESS THAN (100),
PARTITION p1 VALUES LESS THAN (200),
PARTITION p2 VALUES LESS THAN (300),
PARTITION p3 VALUES LESS THAN (400));
insert into t1 values(101,1),(201,2),(301,3),(399,4);
t2的表结构如下
CREATE TABLE t2 (
id int(11) DEFAULT NULL,
grade int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
insert into t2 values(101,0),(201,1),(301,2),(399,3);
analyze table t1;
analyze table t2;
set tidb_partition_prune_mode = ‘dynamic’;
mysql> explain select /*+ TIDB_INLJ(t1, t2) */ t1.id,t1.h_record from t1 join t2 on t1.id=t2.id where t2.grade = 0;
±--------------------------------±--------±----------±-----------------------±----------------------------------------------------------------------------------------------------------------------------+
| id | estRows | task | access object | operator info |
±--------------------------------±--------±----------±-----------------------±----------------------------------------------------------------------------------------------------------------------------+
| IndexJoin_12 | 0.01 | root | | inner join, inner:IndexLookUp_11, outer key:fqtest.t2.id, inner key:fqtest.t1.id, equal cond:eq(fqtest.t2.id, fqtest.t1.id) |
| ├─TableReader_17(Build) | 0.01 | root | | data:Selection_16 |
| │ └─Selection_16 | 0.01 | cop[tikv] | | eq(fqtest.t2.grade, 0), not(isnull(fqtest.t2.id)) |
| │ └─TableFullScan_15 | 8.00 | cop[tikv] | table:t2 | keep order:false, stats:pseudo |
| └─IndexLookUp_11(Probe) | 1.25 | root | partition:all | |
| ├─Selection_10(Build) | 1.25 | cop[tikv] | | not(isnull(fqtest.t1.id)) |
| │ └─IndexRangeScan_8 | 1.25 | cop[tikv] | table:t1, index:id(id) | range: decided by [eq(fqtest.t1.id, fqtest.t2.id)], keep order:false, stats:pseudo |
| └─TableRowIDScan_9(Probe) | 1.25 | cop[tikv] | table:t1 | keep order:false, stats:pseudo |
±--------------------------------±--------±----------±-----------------------±----------------------------------------------------------------------------------------------------------------------------+
8 rows in set (0.00 sec)

像这种都实现了分区动态裁切,为什么执行计划还是显示partition:all,是显示问题嘛,t1表不需要扫描所有的分区,按理来说只应该显示某个分区才对?