Bug 反馈
清晰准确地描述您发现的问题,提供任何可能复现问题的步骤有助于研发同学及时处理问题
【 TiDB 版本】v6.5.0,实际当前7.0以下都有这个问题
【 Bug 的影响】当hashAgg数据落盘读取阶段,通过kill无法快速杀掉会话
【可能的问题复现步骤】
set tidb_mem_quota_query=‘1G’;
set tidb_enable_tmp_storage_on_oom=ON;
set tidb_hashagg_final_concurrency=1;
set tidb_hashagg_partial_concurrency=1;
set tidb_isolation_read_engines=‘tikv’;
tpch100->orders表
explain analyze select o_custkey,sum(o_totalprice) from orders group by o_custkey order by sum(o_totalprice) desc limit 10;
当发生大量数据落盘后,在另一个会话:kill 这个语句
【看到的非预期行为】
该语句连接不会被kill掉
【期望看到的行为】
很快被kill掉
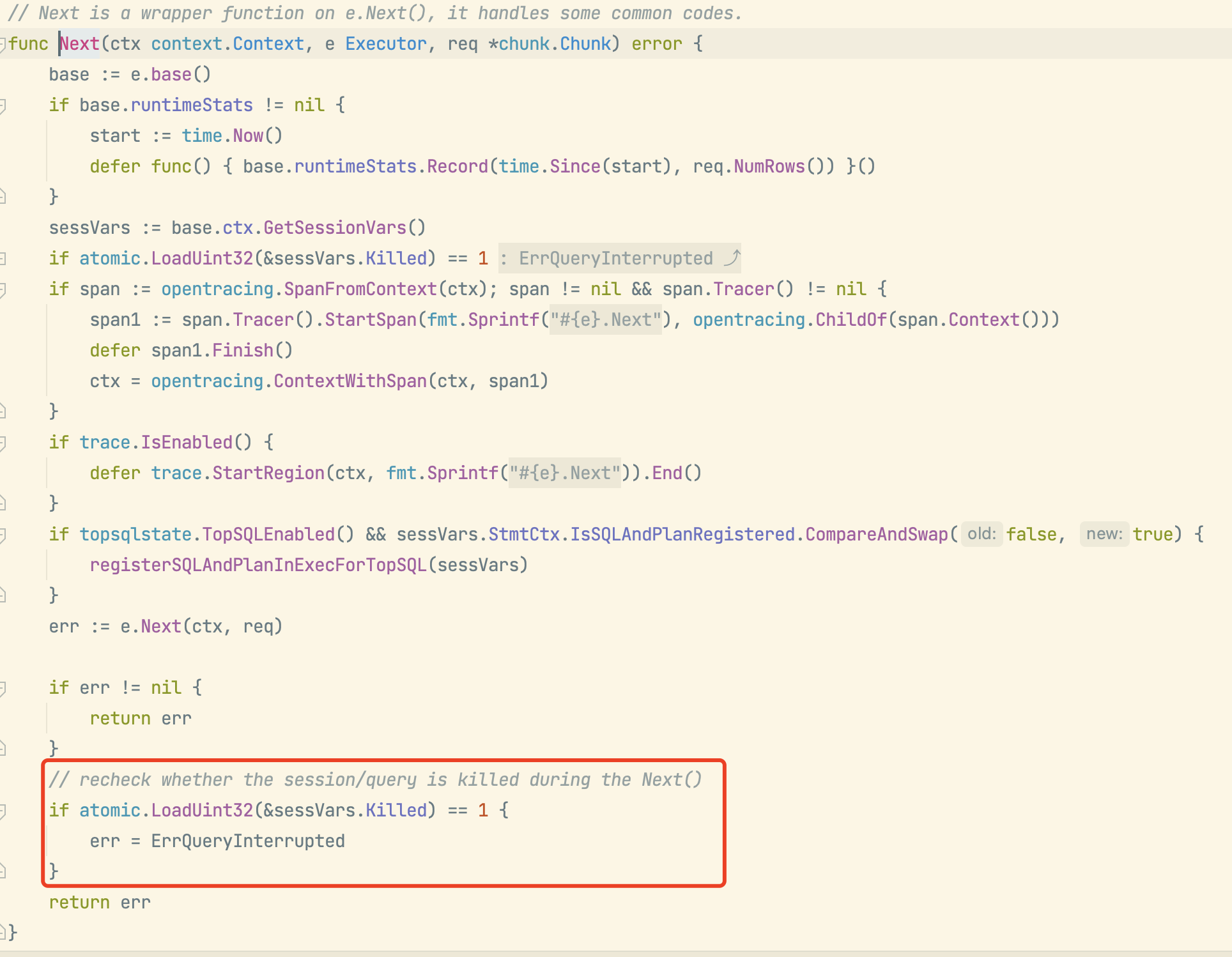
问题分析:
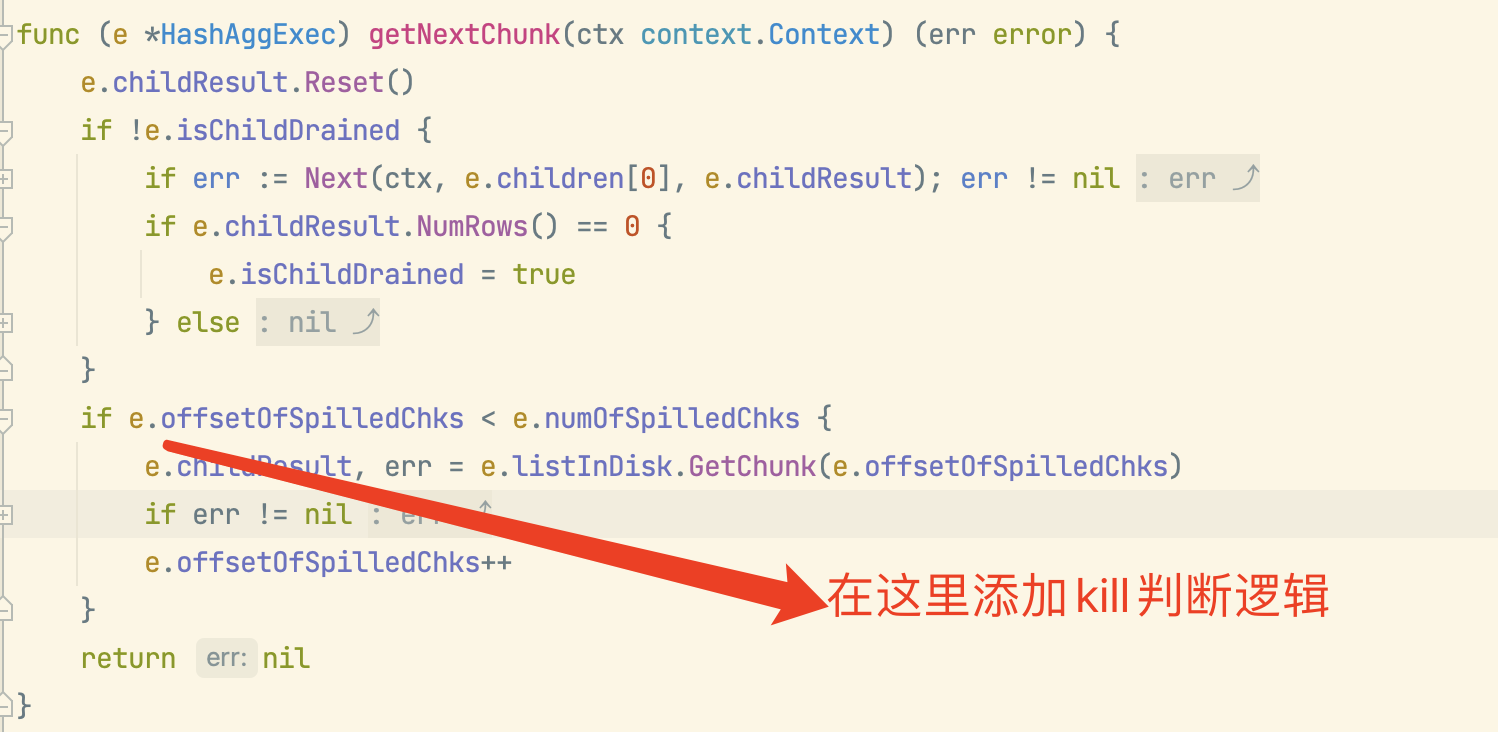
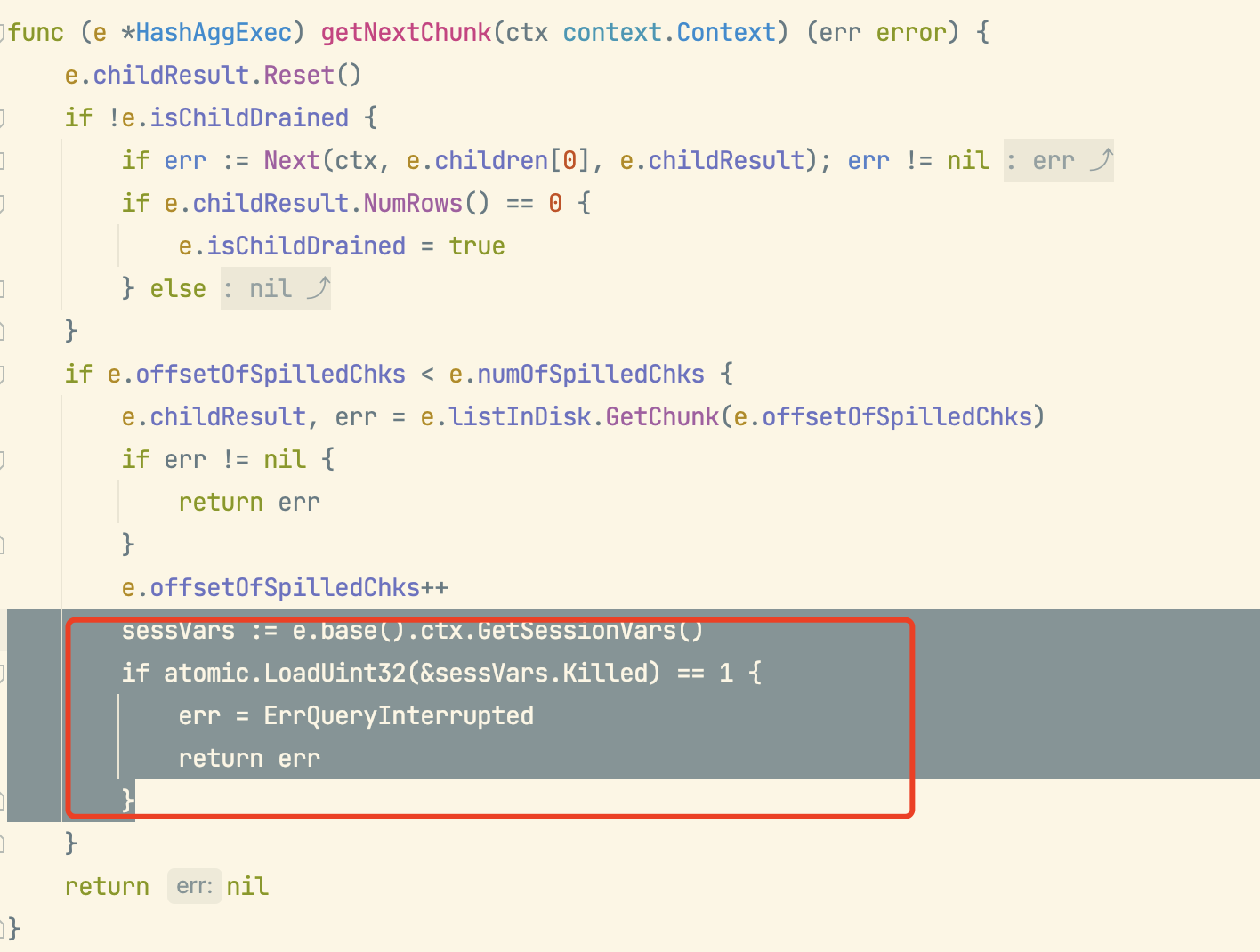
当内存足够时hashAgg通过Next调用子算子获取数据时候有kill判断操作,当hashAgg数据落盘后进行磁盘读取时候并不会被kill,因为在listInDisk.GetChunk方法中并没有kill会话的判断机制。

看是否可以在listInDisk.GetChunk方法调用前(或后)添加kill判断呢?