表数据量是:6亿 , Limit 10 ,为啥这么慢?

刚才又查了个limit 1; 2分30秒。 整个集群抖动了。
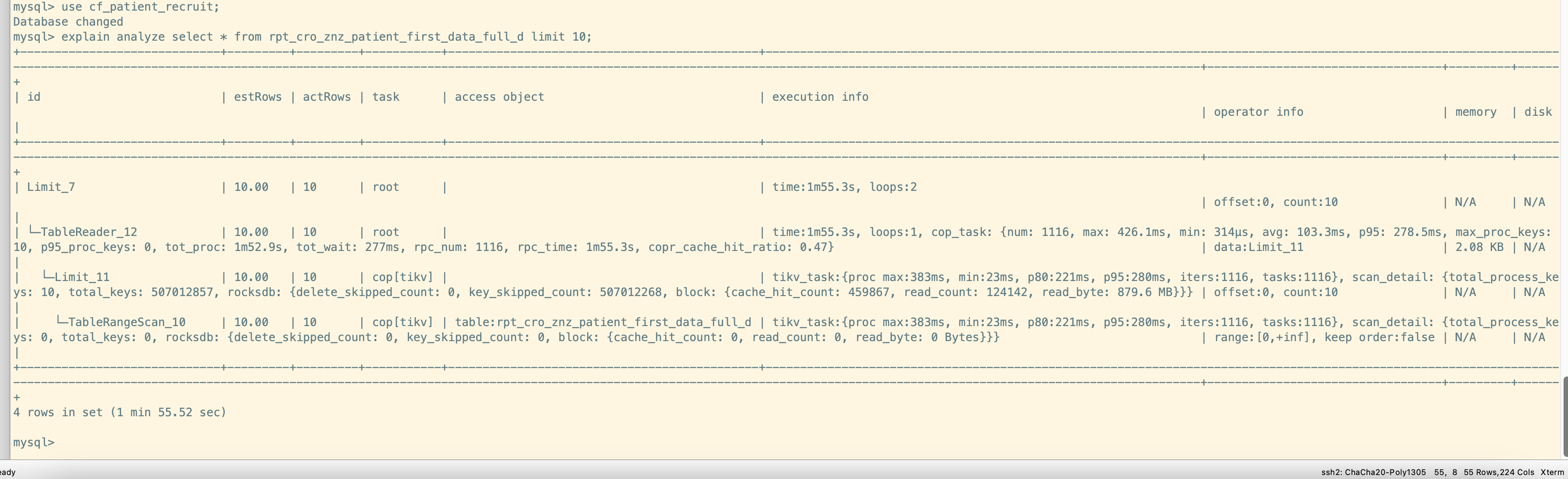
执行计划:

explain analyze:
完整的执行计划发出来看看
放到最下边了
看这个执行计划感觉不应该呀,看看dashboard详细的耗时在哪里呢。
你用explain analyze +sql搞出真实的执行计划看看慢在哪,我觉得暂时看执行计划的算子结构感觉没问题
同遇到过此问题。
使用trace format=‘row’ select * from table limit 10;看下,我记得是首次查询时loadRegion总耗时很多。
但是loadRegion一般不会很慢,这种一般出现在整个集群数据量巨大的时候,以往一般不了了之了。
这次蹲个答案。
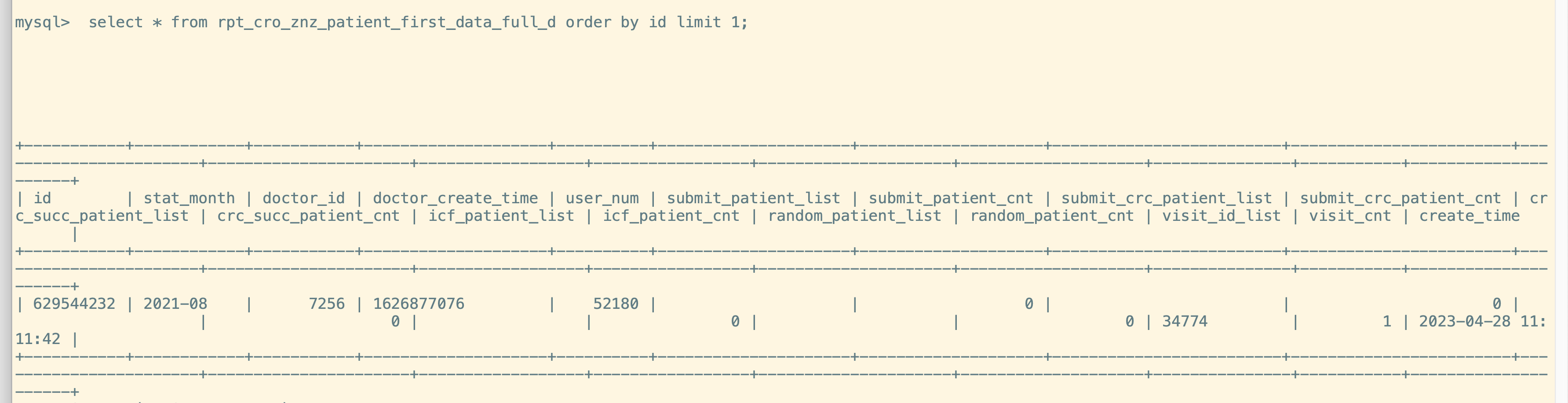
不要直接用limit10,用order by id limit 10试试;
另外你这表统计信息有问题了
![]()
,看一下统计信息健康度。
SHOW stats_healthy WHERE db_name=‘sbtest’ AND table_name=‘sbtest1’;
放到最下边了,可以关注一下
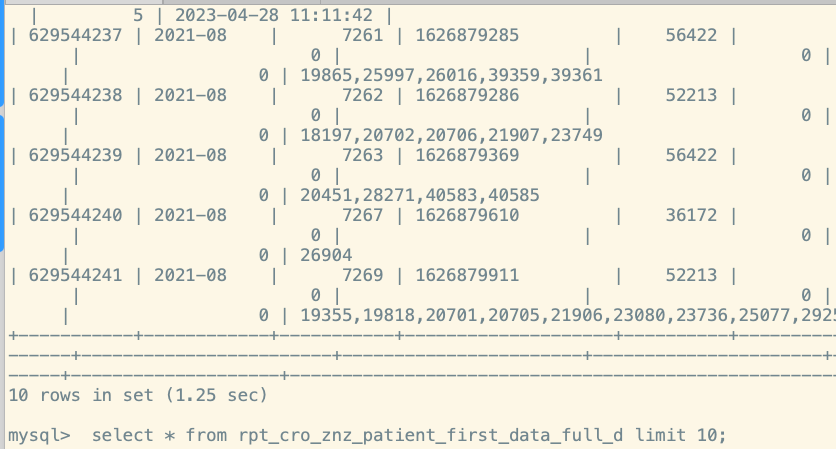
这个问题大概定位到原因了, 这个表其实就20多万数据,是数仓的小时任务,他们每小时delete一次全表, tidb 有mvcc机制,导致有很多历史版本的存在。 每12小时做一次GC。也就是每条记录 大概12个历史版本数据。 查询limit 10;这种会去扫描历史版本 数据吗? 我重建了一个表,把数据灌进去, limit 10 ; 0.06s 就出来了。 我理解查询数据 对删除的所有版本 都扫描了。 原理大家帮忙解释一下。
我觉得应该是你反复delete加insert导致这个表对应的region太多了,
SELECT * FROM INFORMATION_SCHEMA.TIKV_REGION_STATUS a WHERE a.db_name=‘’ AND a.table_name=‘’;
你查一下这个表对应有多少个region,你这样查,tidb是得把所有的region都扫描一遍。。。
你利用主键索引去查就不会遇到这样的情况了,你可以试下
IndexLookUp 算子是否使用分页 (paging) 方式发送 Coprocessor 请求,默认值为 OFF 。对于使用 IndexLookUp 和 Limit 并且 Limit 无法下推到 IndexScan 上的读请求,可能会出现读请求的延迟高、TiKV 的 Unified read pool CPU 使用率高的情况。在这种情况下,由于 Limit 算子只需要少部分数据,开启 tidb_enable_paging ,能够减少处理数据的数量,从而降低延迟、减少资源消耗。 --》 TiDB 5.4 Release Notes | PingCAP 文档中心
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。