请问下各位老师
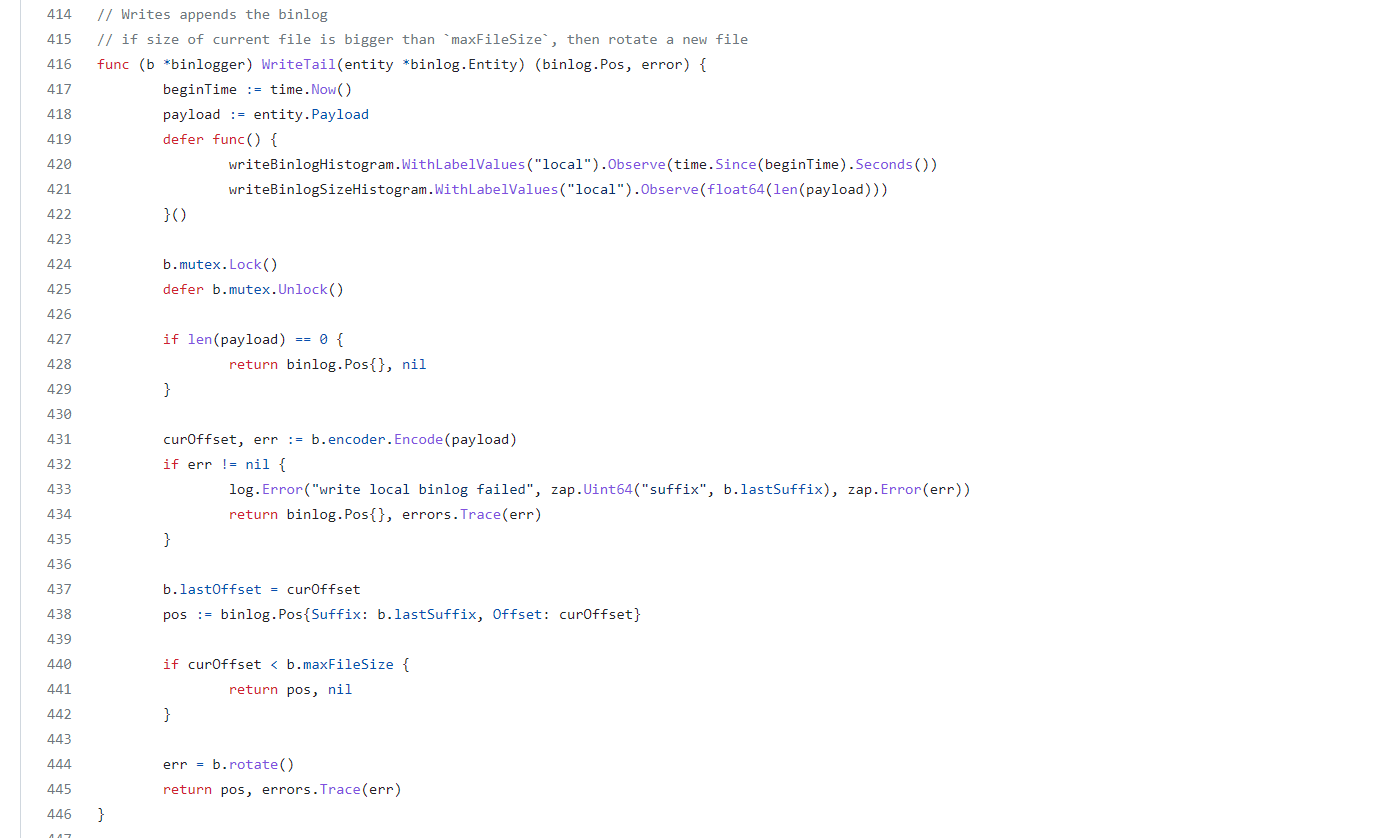
假设drainer 的下游对象是文件,那么drainer 会把从Pump 获取到的内容写到binlog 文件里面,drainer binlog 文件的写入机制代码在
https://github.com/pingcap/tidb-binlog/blob/v6.1.5/pkg/binlogfile/binlogger.go
WriteTail方法里面
这段代码,其实我比较好奇的是,在写入binlog 文件到binlog file后,并没有实时更新savepoint里面的commitTS
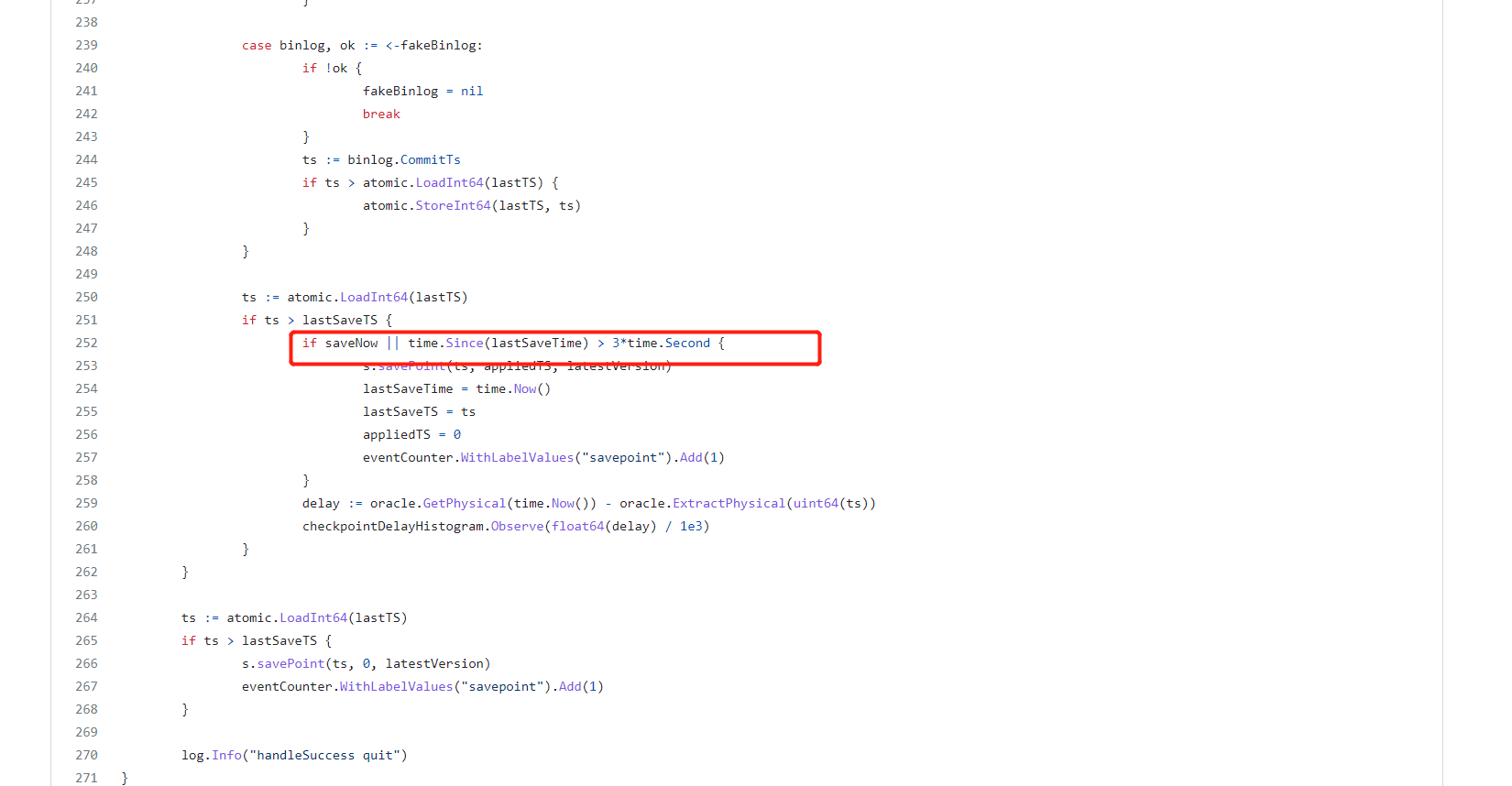
更新savepoint里面的commitTS的代码放在了https://github.com/pingcap/tidb-binlog/blob/v6.1.5/drainer/syncer.go
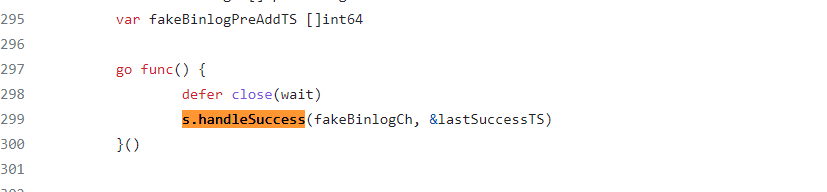
handleSuccess方法,这个方法是调用s.savePoint(ts, appliedTS, latestVersion) 方法取更新savepoint文件,
而handleSuccess方法 是单独起了1个goroutine 去执行,所以我的疑问是
既然savepoint 文件不是更新的,那么在高并发写binlog情况下,drainer的savepoint 文件在每次写完没有实时更新,那么如果drainer 突然挂掉,然后drainer 启动后,有没有可能读取的checkpoint跟已经归档的binlog并不是一致的,会不会导致,drainer 去pump拉取重复的数据,从而导致不一致呢?
抛开这里binlog代码的来说,如oracle/mysql等的redo log writer/checkpointer也并不是实时的binlog flush到哪里checkpoint就记到哪里,你有机会自己写一个类似的推进工具也会知道:checkpoint/savepoint的根本作用是为了记录一个可靠的检查点,以便使得程序中断或故障之后可以从这个检查点开始继续推进。
至于checkpint/savepoint之后的binlog是否已经flush到磁盘以及是否会重放,这个不是重点,因为binlog的重放只要追上就可以认为是幂等的。
因此有没有可能读取的checkpoint跟已经归档的binlog并不是一致,有可能但无所谓。
至于drainer有没有额外的重复校验机制那就不知道了。
[quote=“realcp1018, post:2, topic:1005485, full:true”]
抛开这里binlog代码的来说,如oracle/mysql等的redo log writer/checkpointer也并不是实时的binlog flush到哪里checkpoint就记到哪里,你有机会自己写一个类似的推进工具也会知道:checkpoint/savepoint的根本作用是为了记录一个可靠的检查点,以便使得程序中断或故障之后可以从这个检查点开始继续推进。
至于checkpint/savepoint之后的binlog是否已经flush到磁盘以及是否会重放,这个不是重点,因为binlog的重放只要追上就可以认为是幂等的。
因此有没有可能读取的checkpoint跟已经归档的binlog并不是一致,有可能但无所谓。
至于drainer有没有额外的重复校验机制那就不知道了。
因此有没有可能读取的checkpoint跟已经归档的binlog并不是一致 ,有可能但无所谓。
至于drainer有没有额外的重复校验机制那就不知道了。
为什么无所谓呢?
binlog的格式是全字段的,即假如你有ABC三个字段,你更新了A,那么binlog记录的格式大概是:
type: update, old_fields: [A:…, B: …, C:…], new_fields: [A:…, B: …, C:…]
等你向下游重放binlog之时都是使用new_fields replace into,所以重复不重复影响下游的最终一致性吗,不影响的,binlog设计之初就会考虑幂等重放的情况。
假设drainer 已经将10:00:00的binlog 进行归档了,10:00:00的binlog 对应的记录是insert xxxx
但是savepoint里面的commit是9:59:59,然后drainer 异常重启又从9:59:59 继续拉binlog,然后又将10:00:00对应的binlog 给归档了,那也就是有2条insert 记录?
隐式主键或者主键是做什么的,都replace into了还可能产生2条吗。
把binlog file 解析成sql 里面就只有replace 语句嘛?
如果是这样的数据一致性其实是靠sql 语句去保证的,并不是通过本身的机制区保证的
mysql的binlog 里面记录了各种sql 语句
binlog的格式不是SQL,binlog是一种独特的数据组织格式,你可以看下binlog的proto。
他如何被解析取决于下游如何消费,我们想要他的最终一致性,那就自然使用replace into,如果你要针对insert type就使用insert,那么没问题,处理下主键冲突的异常即可。
mysql的binlog也没有记录sql语句,同样的他也是类似上述的格式,你可以在ROW模式下解析一遍各种event看看,本质上都一样是整条记录的镜像。下游如何消费取决于你解析出binlog后如何组装为SQL,你可以使用insert/replace/update随意组装。
mysql的binlog也没有记录sql语句,同样的他也是类似上述的格式----->mysql的binlog 格式主要有2种,1.row格式
2.statement 格式
row 格式记录的是行变化,这里面也分了insert update delete 等语句带来的行变化
2.statement 格式 记录的就是原始的sql 语句
如果还需要手动处理下主键冲突的异常即可,那么就说明这个设计有点问题了
感谢老师的回复