生产环境,TIDB单表数据量超20亿,在走索引的情况下,单表的查询筛选会很慢,怎么优化查询速度。各位大佬有好的方案吗?
sql语句:
SELECT
count(0)
FROM
collect_pole_history_message a
WHERE
1 = 1
AND SITE_CODE IN (
‘XN11000121’,
‘HN11000211’,
‘HN11000413’,
‘HN11000411’,
‘HN11000313’,
‘HN11000111’,
‘HN11000113’,
‘HN11000112’,
‘HN11000213’,
‘HN11000311’
)
AND command_code IN (
‘0x3A’,
‘0x7A’,
‘0x68’,
‘0x10’,
‘0x70’,
‘0x05’,
‘0x6C’,
‘0x69’,
‘0x11’,
‘0x15’,
‘0x3A’,
‘0x05’,
‘0x17’,
‘0x15’,
‘0x70’,
‘0x3F’,
‘0x6F’,
‘0x7F’,
‘0x11’
)
AND org_id IN (
‘61386612e4b0a48664adbc60’,
‘61386cece4b0a48664adbc8b’,
‘61386e00e4b0a48664adbc9b’,
‘61386ea7e4b0a48664adbc9d’,
‘63876c92e4b00dbb07d4dc41’,
‘638d4b8fe4b00dbb07d4dcd3’,
‘61415640e4b0d3a914d45efb’,
‘61396d53e4b064a86f4a16ff’,
‘61396d7de4b064a86f4a1702’,
‘6323d716e4b00e22a4b93cf6’,
‘613acabae4b0f8f969dab71f’,
‘613acb35e4b0f8f969dab723’
)
AND occur_time >= ‘2023-04-22 08:48:51’
AND occur_time <= ‘2023-04-23 08:48:51’;
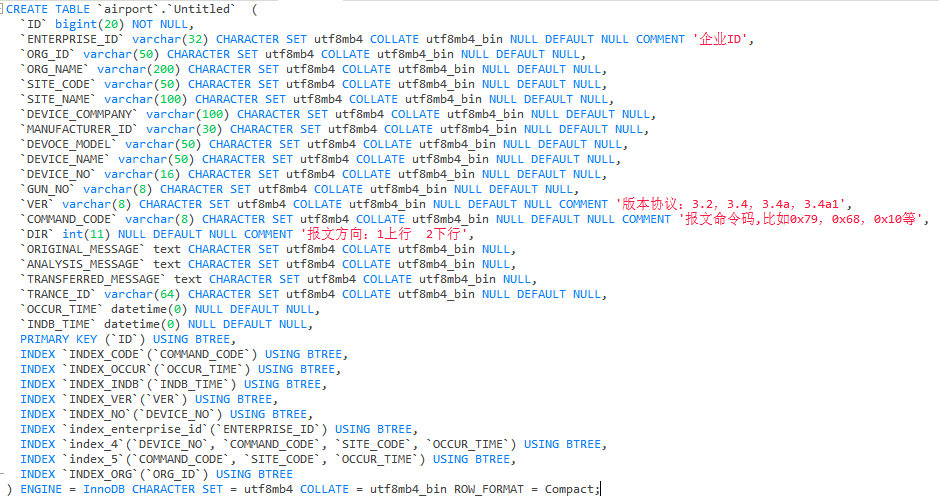
表结构:
执行计划:

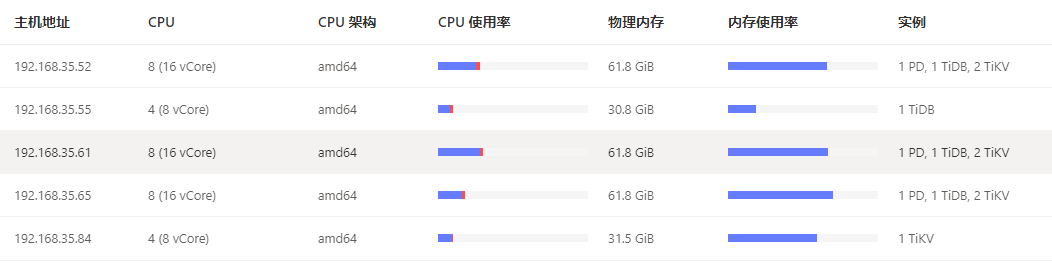
集群拓扑: