bigtable的实现中,有LG/CF/Qu多种概念。
TiKV下,CF不对用户暴露,实际上只有事务实现依赖,而且我理解底层是真的"行"存储?文档(https://tidb.net/blog/4fbd0203 )
对于这种组织方式,为什么不用bigtable中多行实现,各有什么优缺点呢?
如果用户改某一个’列’的数据,实际在TiKV是如何实现的呢?(Read Modify Write?)
计算侧会将一些计算任务下钻到存储层去做,如(where name=‘Tikv’),那么存储侧其实是知道每个列的含义的对吧?问到这个问题,主要是想了解这种方式下在业务侧来编排这个数据是否能降低存储的复杂度,或者说目前是否确实是SQL来管理Schema的。好比说对存储来讲就是K-V(存储不知道V的格式),读到这个数据之后,只有上层SQL计算才能解析这部分数据。
我的意思是对于行式数据,TiKV是怎么提供’列’的能力,至少用户看起来是这样
WalterWj
2023 年4 月 17 日 08:55
4
key values 中,values 中有列信息。改一列就是整行重新编码 append。mvcc 控制版本
整行的编码和解码的工作是在哪里做的呢,TiKV还是SQL侧呢?
SQL解析处理、执行计划优化和生成、数据的编码和解码是在tidb-server侧做的,tikv-server负责做MVCC、事务、raft peer复制等事情
分布式 SQL 运算 首先,SQL 中的谓词条件 name = "TiDB" 应被下推到存储节点进行计算 』coprocessor 呢
这里的分布式计算,核心操作是数据的查询和过滤。对于给定的谓词条件 name = "TiDB",在tidb-server层根据表的索引、列情况、统计信息等数据,在这一层经过分析和查询计划生成,就可以知道它的具体检索过程(用什么索引查什么范围)。
具体可以看看官方说计算的文档,一句话,它就是将具体的 SQL 查询映射为对 Key-Value 的查询,Key的范围根据谓词条件而定,这是执行计划生成的过程。具体某个表在哪个tikv实例上通过访问pd可知,然后通过在tidb-server的 KV 接口,再去查询tikv存储层获得对应的数据,执行各种计算。
你给的例子如果是sum/count/avg/max/min等操作,它就可以先在tikv计算再返回结果,这就是计算下推到存储层完成。
你给的例子如果是sum/count/avg/max/min等操作,它就可以先在tikv计算再返回结果,这就是计算下推到存储层完成。
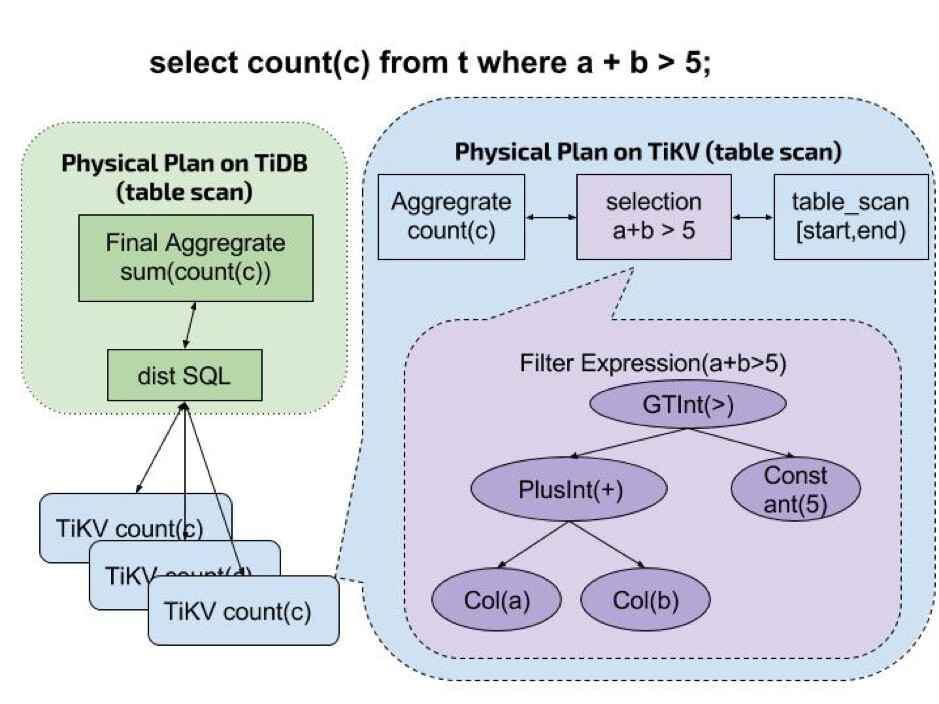
这个我还是有点疑问,譬如说 select count(c) from t where a + b < 5,我看 coprocessor 的文档是这么描述的,图示如下
在TiKV侧,有PlusInt(Col(a) + Col(b))的计算,这里核心的问题是,如果TiKV不知道每个列,如何做这个操作的。官网这个例子是列存而不是行存?还是其他的原因呢
TiKV是行存储引擎,不管是直接查到还是通过普通索引回表查到,它每次读取到数据时,拿到的都是整行数据,所以每个列它自然知道
呃,我的理解是,既然编码和解码在计算层去做 ,那么TiKV一定是不知道具体的列是什么的,这个行数据对于TiKV就是个二进制;反之如果编码和解码在存储来做,具体的列才会被TiKV知晓
上面我说的编码,是指关系型的数据行,根据映射算法可以将库表中的数据映射到 TiKV 中的 (Key, Value) 键值对。每行数据按照如下规则编码成 (Key, Value) 键值对:
Key: tablePrefix{TableID}_recordPrefixSep{RowID}
Value: [col1, col2, col3, col4]
当你拿到这行数据,每个字段都可以知道了,它这里的编码,并不是一种加密手段,而是根据一定规则来组织数据,方便存储,具体的规则建议再多看几遍文档和论坛的文章。
当然,TiKV实际存储的时候存的是二进制数组。
我在理解下哈,这里说的编码和解码是说『从SQL语句翻译成TiKV理解的接口』以及『将TiKV的返回解码成SQL语句的返回』
这么理解没错吧?
再问个写流程的问题,对于 insert into t(a, b, c) values(“1”, “2”, “3”) where id = 111; t的schema [id, a, b, c, d, e]共6列
TiDB使用read modify write语义,Get_TiKV后拿到整行数据,在更新各个列, 发给TiKV更新整行
TiDB将这三个列发给TiKV,TiKV读取整行内容后,根据这三列内容更新
直观上是第二种做法,实际也是这么做的么?
TiDBer_U161qhfO:
insert into t(a, b, c) values(“1”, “2”, “3”) where id = 111;
这个SQL 有问题吧,后面的where条件是想表达什么?
哦整错了 insert into t(id, a, b, c) values(111, “1”, “2”, “3”)
粗略来说,写流程大概是这样的:
如果是新的行,它直接写入 编码后的KV键值对,执行的是put操作。
如果是更新已有的数据(更新部分字段),它是先读出整行,然后用要更新的列值和旧的未被更新的列值,带上最新的时间戳生成新的行,然后执行put操作。新旧数据根据时间戳有不同的版本,这就是MVCC的基本原型。等到GC或者Compaction操作在清理旧的数据。
如果是删除操作,它也是用旧的数据行+最新的时间戳+删除标记,执行put操作。等到GC或者compaction操作在清理旧的数据。
事务的保证是通过2PC实现的,在比较新的 TiDB 版本里也实现了1PC,供特殊场景使用。
1 个赞
这里读出整行都是TiDB-Server侧做的对吧?TiKV底层存储v永远都是全部列,而不是存在部分列,存储做merge对么?https://github.com/pingcap/tidb/blob/master/executor/insert_common.go#L226 方便请教下读整行是在哪做的么